Python 领域运用:网络爬虫
1. 爬虫简介
网络爬虫,又称为网页蜘蛛,是一种按照一定的规则、自动地抓取万维网信息的程序。爬虫是一个自动下载网页的程序,它有选择的访问万维网上的网页与相关的链接,获取所需要的信息。
爬虫有着广泛的应用:
- 搜索引擎,谷歌百度等搜索引擎使用爬虫抓取网站的页面
- 舆情分析与数据挖掘,通过抓取微博排行榜的文章,掌握舆情动向
- 数据聚合,比如企查查,抓取企业官网的详细信息
- 导购、价格比对,通过抓取购物网站的商品页面获取商品价格,为买家提供价格参考
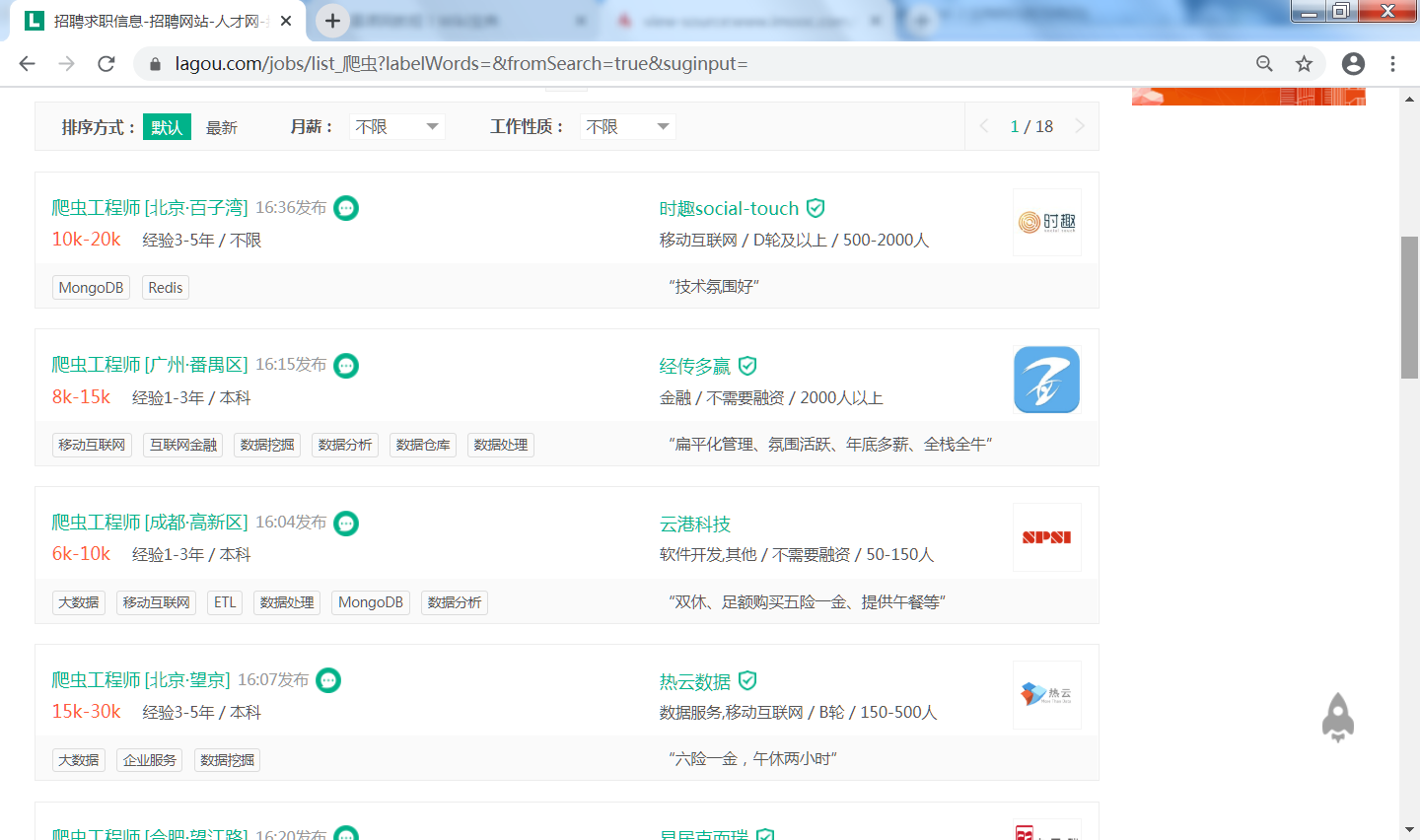
在面向计算机专业的人才招聘市场上,以爬虫为关键字搜索,可以获得大量的职位招聘:
2. 爬虫的工作原理
爬虫的工作原理如下:
- 从一个或若干初始网页的 URL 开始
- 自动下载初始网页上的 HTML 文件
- 分析 HTML 文件中包含的链接,爬取链接指向的网页
- 不断重复以上过程,直到达到某个条件时停止
下面以爬取慕课网的 wiki 为例,说明爬虫的工作原理:
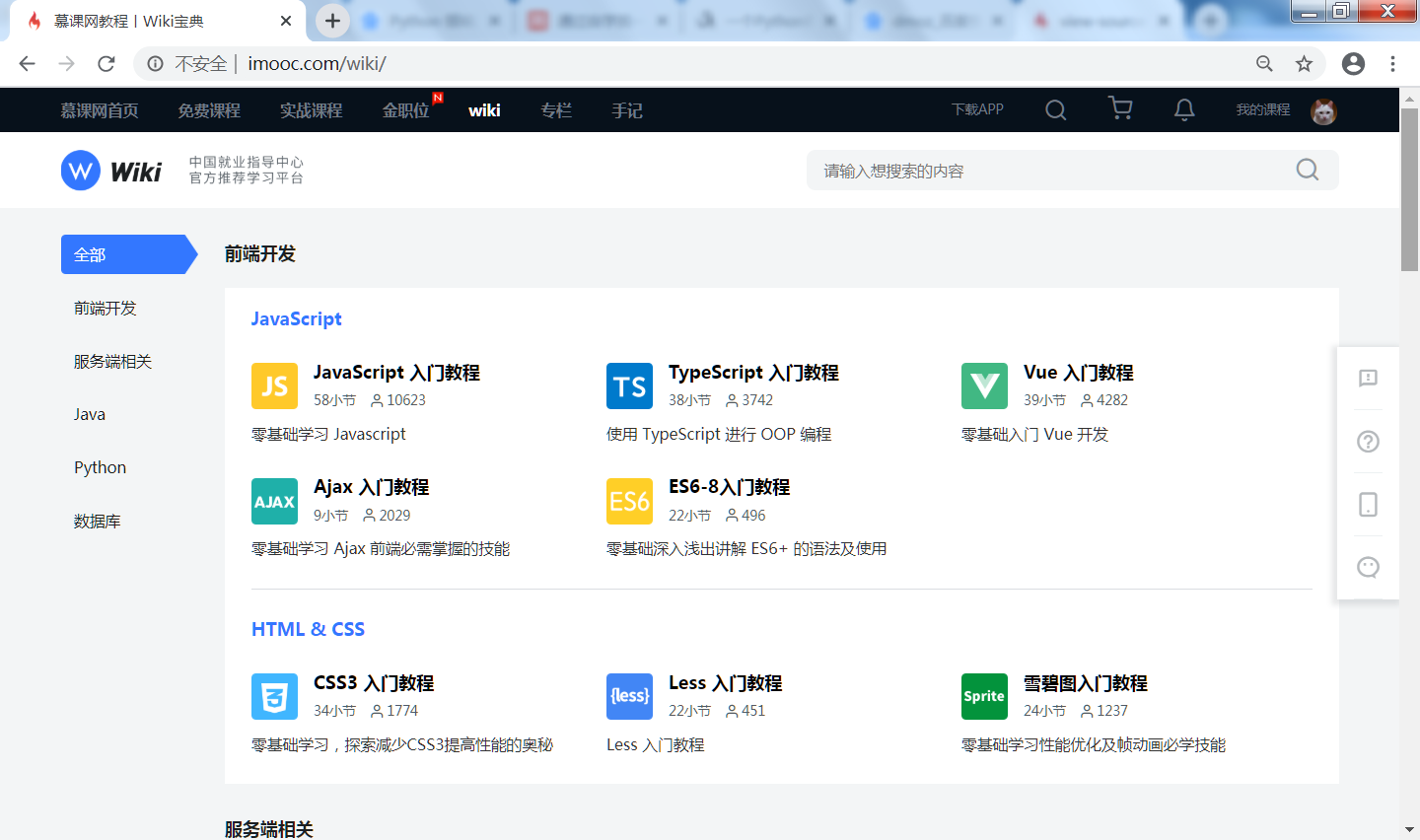
- 排虫程序选择 https://www.linkdao.cn/wiki 作为入口
- 下载网页 https://www.linkdao.cn/wiki 的内容,大致如下:
<html data-n-head-ssr>
<head >
<title>慕课网教程丨Wiki宝典</title>
<meta name="description" content="慕课网wiki教程平台">
</head>
<body>
<div>
<div class="text">
<a href="/wiki/Javascriptbase">JavaScript 入门教程</a>
<p><span>58小节</span>
</div>
<div class="text">
<a href="/wiki/typescriptlession">TypeScript 入门教程</a>
<p><span>38小节</span>
</div>
<div class="text">
<a href="/wiki/vuelession">Vue 入门教程</a>
<p><span>39小节</span>
</div>
</div>
</body>
</html>
- 分析 HTML 文件中的 a 标签,发现有如下 3 个 a 标签
- 爬虫爬取以上 3 个 a 标签中的链接
- 不断重复以上步骤,可以将慕课网的全部 wiki 文章抓取到本地
3. 爬虫入门
3.1 基本的爬取技术
在互联网早期,网站的内容以静态的 HTML 文件为主,不带任何反爬虫措施。比如,要爬取某个博客站点的全部文章,首先获取网站的首页,就顺着首页的链接爬到文章页,再把文章的时间、作者、正文等信息保存下来。
使用 Python 的 requests 库就可以爬取由静态网页构成的网站:
- 使用 requests 库下载指定 URL 的网页
- 使用 XPath、BeautifulSoup 或者 PyQuery 对下载的 HTML 文件进行解析
- 获取 HTML 文件中特定的字段,例如文章的时间、标题等信息,将它们保存
- 获取 HTML 文件中包含的链接,并顺着链接爬取内容
- 爬取到数据后,可以使用 MySQL、MongoDB 等来保存数据,实现持久化存储,同时方便以后的查询操作
3.2 爬取客户端渲染的网页
在互联网早期,网站的内容都是一些简单的、静态的页面,服务器后端生成网页内容,然后返回给浏览器,浏览器获取 html 文件之后就可以直接解析展示了,这种生成 HTML 文件的方式被称为服务器端渲染。
而随着前端页面的复杂性提高,出现了基于 ajax 技术的前后端分离的开发模式,即后端不提供完整的 html 页面,而是提供一些 api 返回 json 格式的数据,前端调用后端的 API 获取 json 数据,在前端进行 html 页面的拼接,最后后展示在浏览器上,这种生成 HTML 文件的方式被称为客户端渲染。
简单的使用 requests 库无法爬取客户端渲染的页面:
- requests 爬下来的页面内容并不包含真正的数据
- 只能通过调用后端的 API 才能获取页面的数据
有两种方式爬取客户端渲染的网页:
- 分析网页的调用后端 API 的接口
这种方法需要分析网站的 JavaScript 逻辑,找到调用后端 API 的的代码,分析 API 的相关参数。分析后再用爬虫模拟模拟调用后端 API,从而获取真正的数据。
很多情况下,后端 API 的接口接口带着加密参数,有可能花很长时间也无法破解,从而无法调用后端 API。
- 用模拟浏览器的方式来爬取数据
在无法解析后端 API 的调用方式的情况下,有一种简单粗暴的方法:直接用模拟浏览器的方式来爬取,比如用 Selenium、Splash 等库模拟浏览器浏览网页,这样爬取到的网页内容包含有真实的数据。这种方法绕过分析 JavaScript 代码逻辑的过程,大大降低了难度。
3.3 爬虫相关的库和框架
- 实现 HTTP 请求操作
- urllib:提供操作 URL 的功能
- requests:基于 urllib 的 HTTP 请求库,发出一个 HTTP 请求,等待服务器响应的网页
- selenium:自动化测试工具,通过这个库调用浏览器完成某些操作,比如输入验证码
- 从网页中提取信息
- beautifulsoup:对 html 和 XML 进行解析,从网页中提取信息
- pyquery:jQuery 的 Python 实现,能够以 jQuery 的语法来操作解析 HTML 文档
- lxml:对 html 和 XML 进行解析,支持 XPath 解析方式
- tesserocr:一个 OCR 库,在遇到验证码的时候,可使用该库进行识别
- 爬虫框架
- Scrapy:Scrapy 是用 python 实现的一个为了爬取网站数据,提取结构性数据而编写的应用框架。用这个框架可以轻松爬下来如亚马逊商品信息之类的数据
- PySpider: pyspider 是用 python 实现的功能强大的网络爬虫系统,能在浏览器界面上进行脚本的编写和爬取结果的实时查看,后端使用常用的数据库进行爬取结果的存储,还能定时设置任务与任务优先级等
- Newpaper: Newspaper可以用来提取新闻、文章和内容分析
4. 提升爬虫的效率
4.1 多任务爬虫
爬虫是 IO 密集型的任务,大多数情况下,爬虫都在等待网络的响应。如果使用用单线程的爬虫来抓取数据,爬虫必须等待当前页面抓取完毕后,才能请求抓取下一个网页。大型网站包含有数十万的网页,使用单线程抓取网页的速度是无法接受的。
使用多进程或者多线程的技术,爬虫可以同时请求多个网页,可以成倍地提高爬取速度。
假设爬虫需要获取 baidu.com、taobao.com、qq.com 首页,通过使用多线程技术,可以并行的抓取网页,代码如下:
import requests
import threading
def fetch(url):
response = requests.get(url)
print('Get %s: %s' % (url, response))
t0 = threading.Thread(target = fetch, args = ("https://www.baidu.com/",))
t1 = threading.Thread(target = fetch, args = ("https://www.taobao.com/",))
t2 = threading.Thread(target = fetch, args = ("https://www.qq.com/",))
t0.start()
t1.start()
t2.start()
t0.join()
t1.join()
t2.join()
- 函数 fetch,函数 fetch 获取指定 url 的网页
- 创建 3 个线程
- 线程 t0 调用 fetch 获取 baidu.com 首页
- 线程 t1 调用 fetch 获取 taobao.com 首页
- 线程 t2 调用 fetch 获取 qq.com 首页
- 线程是并行执行的,可以将抓取速度提高为原来的 3 倍
4.2 分布式爬虫
多线程、多进程能加速爬取速度,但终究还是单机的爬虫,性能提升有限。要爬取超大规模的网站,需要使用分布式爬虫。分布式爬虫把爬虫的关键功能部署到多台机器上,多台机器同时爬取数据。
下图展示了一种典型的分布式爬虫的架构:
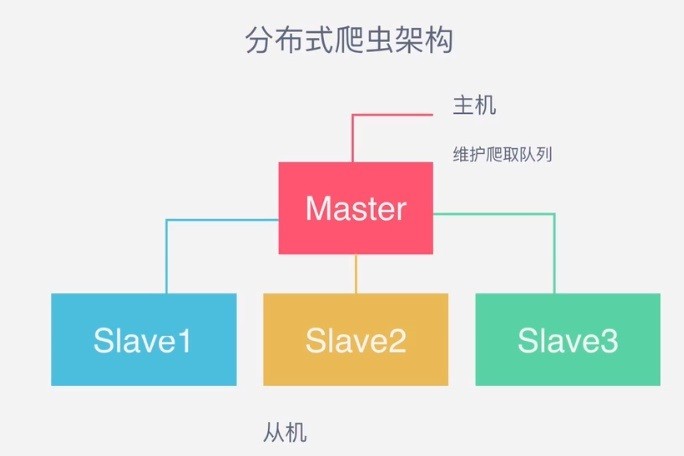
- 分布式爬虫的功能由 4 台机器承担:1 台 master 和 3 台 slave
- 分布式爬虫的关键是共享一个请求队列,请求队列保存了需要爬取的网页的 URL 地址
- 维护该队列的主机称为 master
- 负责数据的抓取、数据处理和数据存储的主机称为 slave
- master 负责管理 slave 连接、任务调度与分发、结果回收并汇总等
- slave 从 master 那里领取任务,并独自完成任务最后上传结果