开发小案例-综合运用
学习了这么多知识,这节课我们来实践一下,我们在这节课会设计一个小爬虫来爬取慕课网所有的免费课信息。当然,爬取慕课网所有免费课信息只是一个大的目标而已,具体要实现这个目标我们还需要对划分步骤,将一个大目标分解成一个个的小目标才可以。在实际的开发工作中我们也需要这样,拿到需求之后不要上来就开始写代码,然后一边写一边运行调试,虽然这样不能说错吧,但是却跟装运气一样,试对了就对了,错了还一直在哪里纠结。下面我们先来看下这个小爬虫的案例步骤:
1. 案例步骤与目标:
- 分析网站
- 书写程序
- 运行程序,并将结果存入MongoDB
1.1 目标:
通过本案例,学习BeautifulSoup的网站分析方法,以及掌握将数据存入MongoDB
1.2 分析网站
第一步,打开慕课网网址,然后点击免费课程,效果如下:
接下来,我们右键单击鼠标,效果如下:
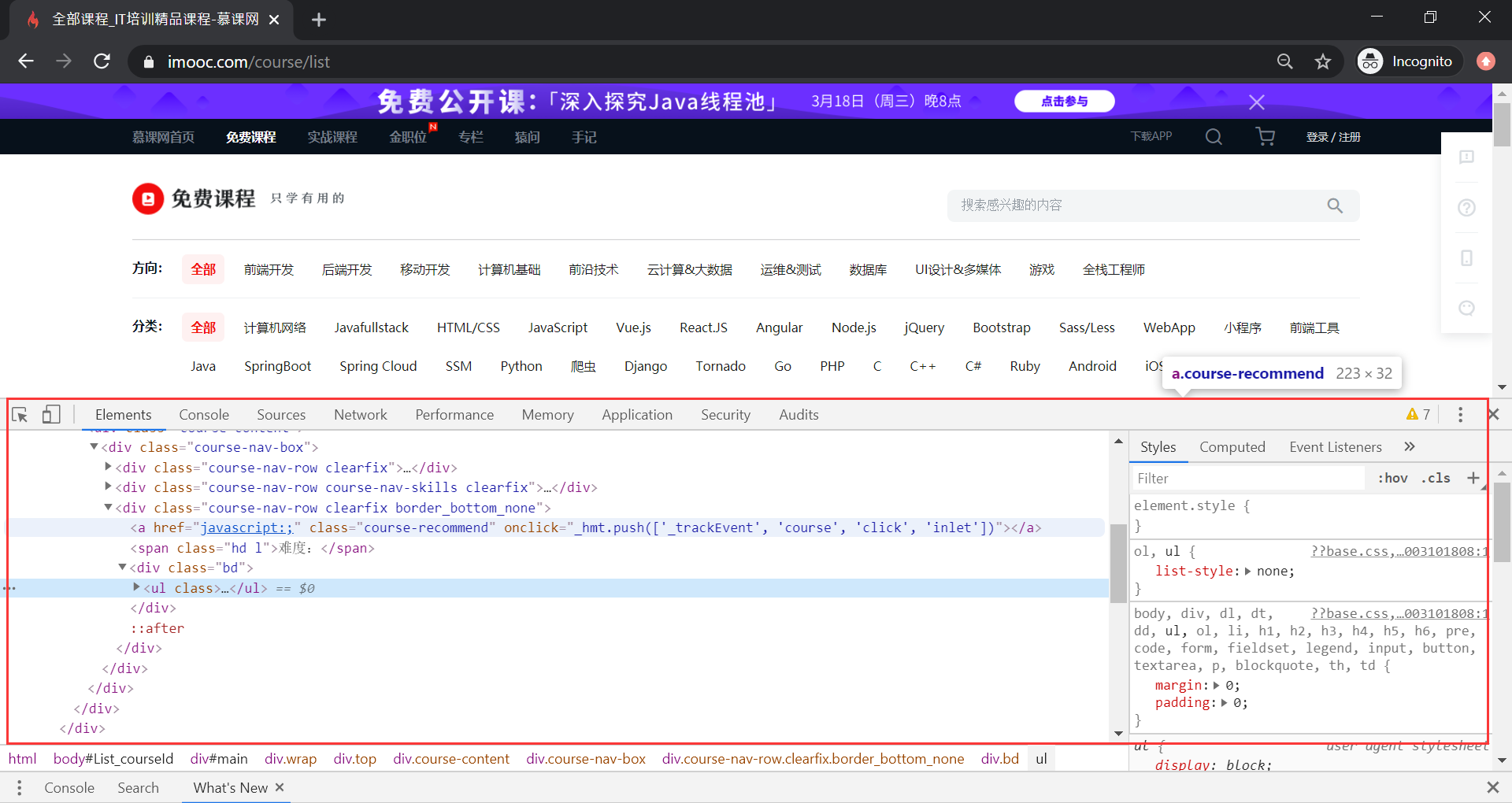
点击 Inspect 后,在浏览器的下端,会弹出浏览器 debug 控制面板:
单击左上角的小三角,然后选定一个课程,效果如下:
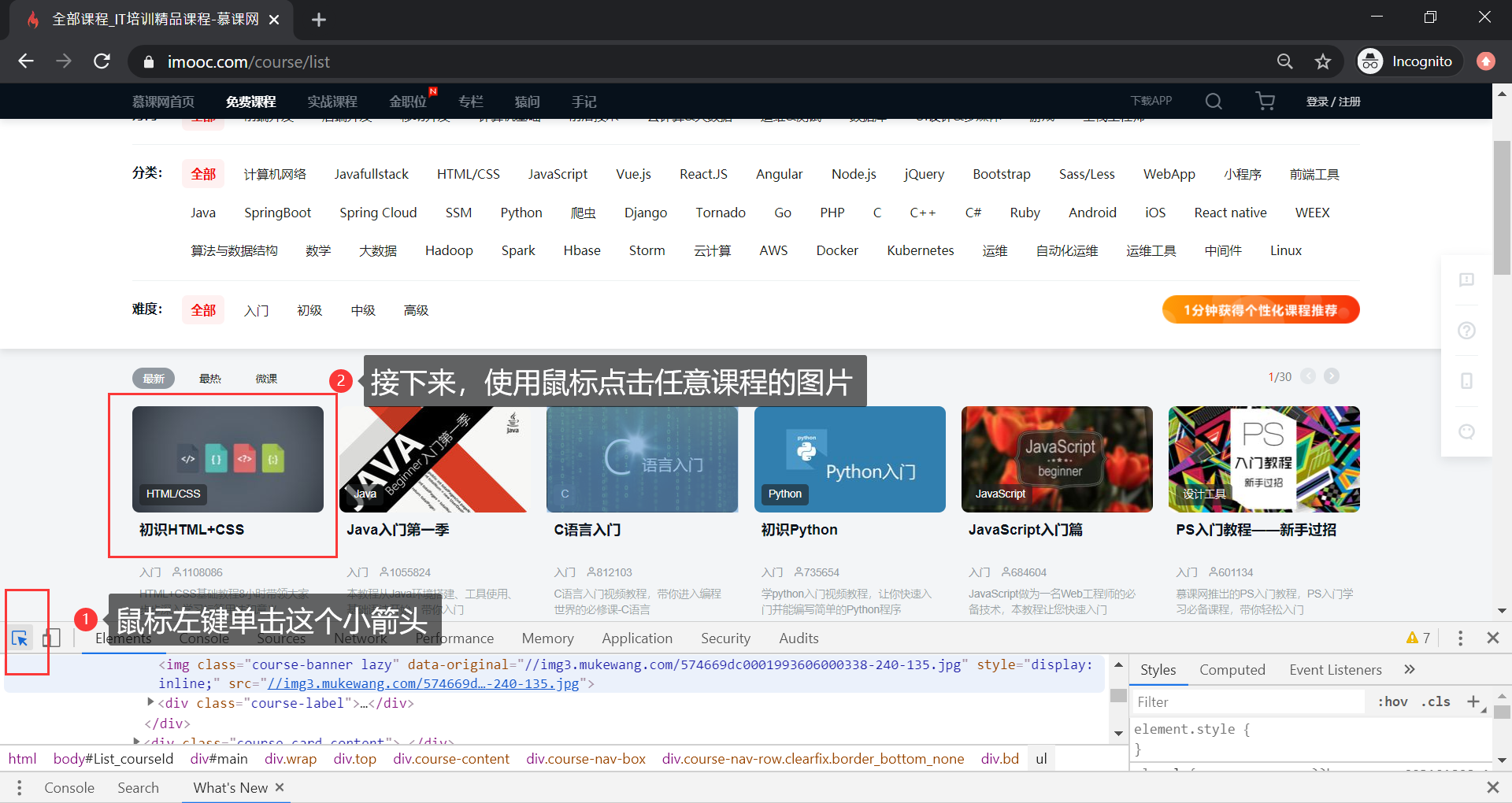
如下图阴影部分所示,是图片的在 html 中的位置,我们需要整个课程的信息,因此提取 course-card-content 作为基本模块:
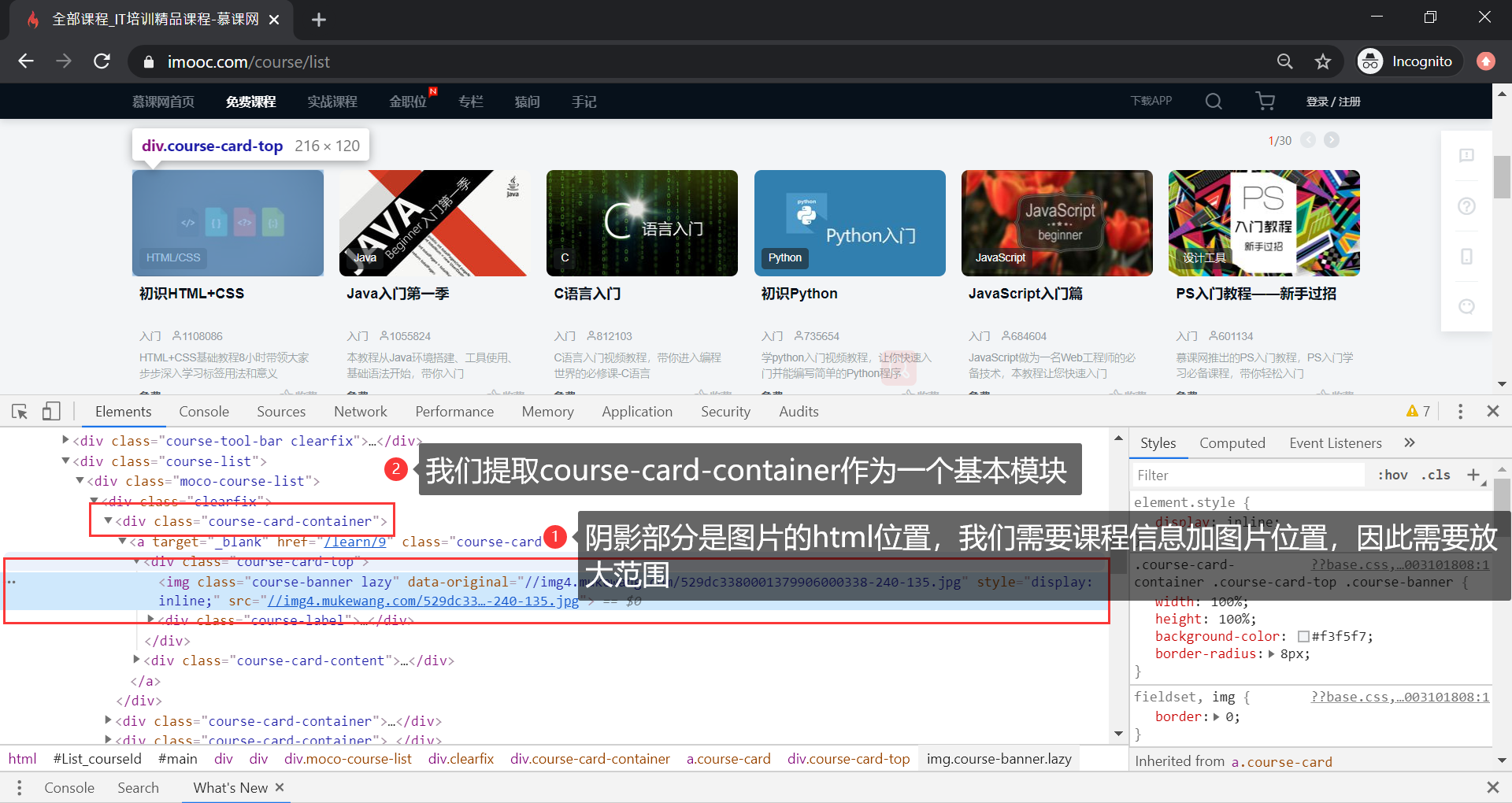
在程序里,我们需要使用 BeautifulSoup 定位到到这里。
2. 书写程序
我们先来看一下代码的架构:
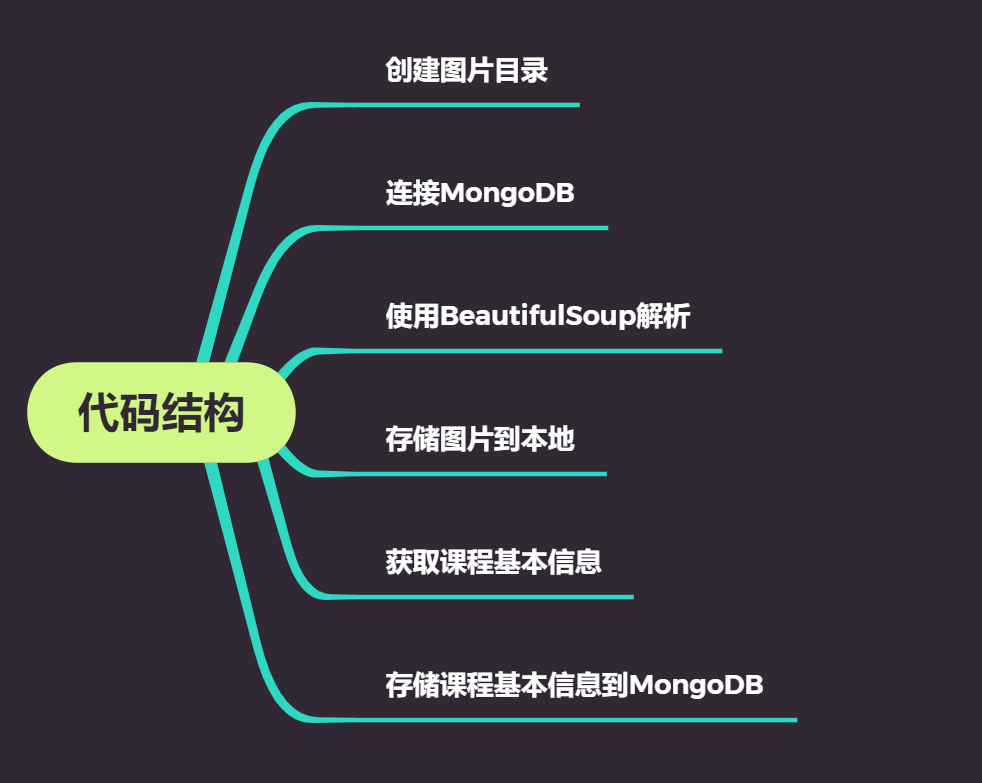
接下来,让我们看看所有代码。
import requests
from bs4 import BeautifulSoup
from pprint import pprint
import os
import lxml
import pymongo
headers = {'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10\_11\_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.79 Safari/537.36'} # 请求头部
def get\_course\_info():
""" get all course basic unit """
url = "https://www.linkdao.cn/course/list" #慕课网免费课地址
r = requests.get(url, headers= headers) # 发送请求
bs = BeautifulSoup(r.text, "lxml") # 解析网页
course_data = bs.find_all("div", class_="course-card-container") # 定位课程信息
return course_data
def save\_pics(course_data):
""" save pics from imooc free course """
for each_item in course_data:
img = each_item.find("img")
image_link = img.attrs["data-original"].split("/")
image_address = "http:" + img.attrs["data-original"]
with open(image_link[-1],'wb+') as f:
res = requests.get(image_address, headers= headers) # 发送请求
f.write(res.content)
def save\_courses\_to\_mongodb(mongod_con, course_data):
""" save info to mongodb """
for each_item in course_data:
imgs = each_item.find("img")
desc = each_item.find("p", class_="course-card-desc") # 定位课程信息
class_name = each_item.find("h3", class_="course-card-name") # 定位课程信息
imooc_dict = { "class\_name": class_name.getText(), "class\_pics": imgs.attrs["data-original"], "people":desc.getText()}
x = mongod_con.insert_one(imooc_dict)
def create\_local\_pic\_dir():
""" if don't have local dir, create one for holding the pics which download from the imooc. """
directory = os.path.dirname(os.path.realpath(__file__)) + '/imooc\_pics/'
if not os.path.exists(directory):
os.makedirs(directory)
os.chdir(directory)
def db\_connectin():
""" Connection to local mongo db service."""
try:
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["practice"]
mongod_con = mydb["imooc\_courses"]
except Exception as e:
print("ERROR(MongoPipeline):", e)
return mongod_con
def main():
""" This is the main entry for running code."""
create_local_pic_dir()
mycol = db_connectin()
data = get_course_info()
if data:
save_pics(data)
save_courses_to_mongodb(mycol, data)
if __name__ == "\_\_main\_\_":
main()
代码主要有 6 个函数:
- create_local_pic_dir: 用来创建本地文件夹,来存储爬取的图片;
- db_connectin: 用来连接 mongodb;
- get_course_info :用来获取课程基本信息;
- save_pics :函数将图片存储在本地;
- save_courses_to_mongodb :将数据存储到 MongoDB;
- main :负责运行程序。
2.1 create_local_pic_dir
首先,在本地创建一个文件夹,来存储从慕课网下载下来的图片信息。
2.2 db_connectin
建立本地的连接,并返回一个连接句柄。
2.3 get_course_info
通过前面网站的分析,我们可以通过调用 bs4 的 find_all() 方法来定位课程的基本单元,然后通过遍历,获取课程的详细信息。
2.4 save_pics
在存储图片的时候,我们需要提取图片的名称,使用 split 将网址分开,然后取倒数第一数据,就是图片的名称。
2.5 save_courses_to_mongodb
在我们成功连接 mongdb 之后,通过调用 insert_one() 方法,我们可以把课程的字典信息,一条一条的存储到 mongodb 中。
2.6 运行程序,并将结果存入MongoDB
可以看到,程序创建了 imooc_pics 文件夹,里面存储了我们从慕课网下载的免费课程的介绍图片。
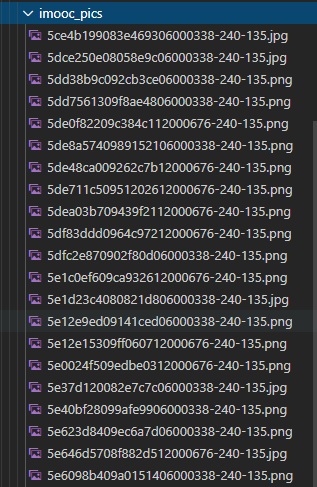
打开一张图片可以看到是一张课程的封面图:

最后,我们使用 MongoDB 的可视化工具,看一下图片的存储情况,效果如下图所示:
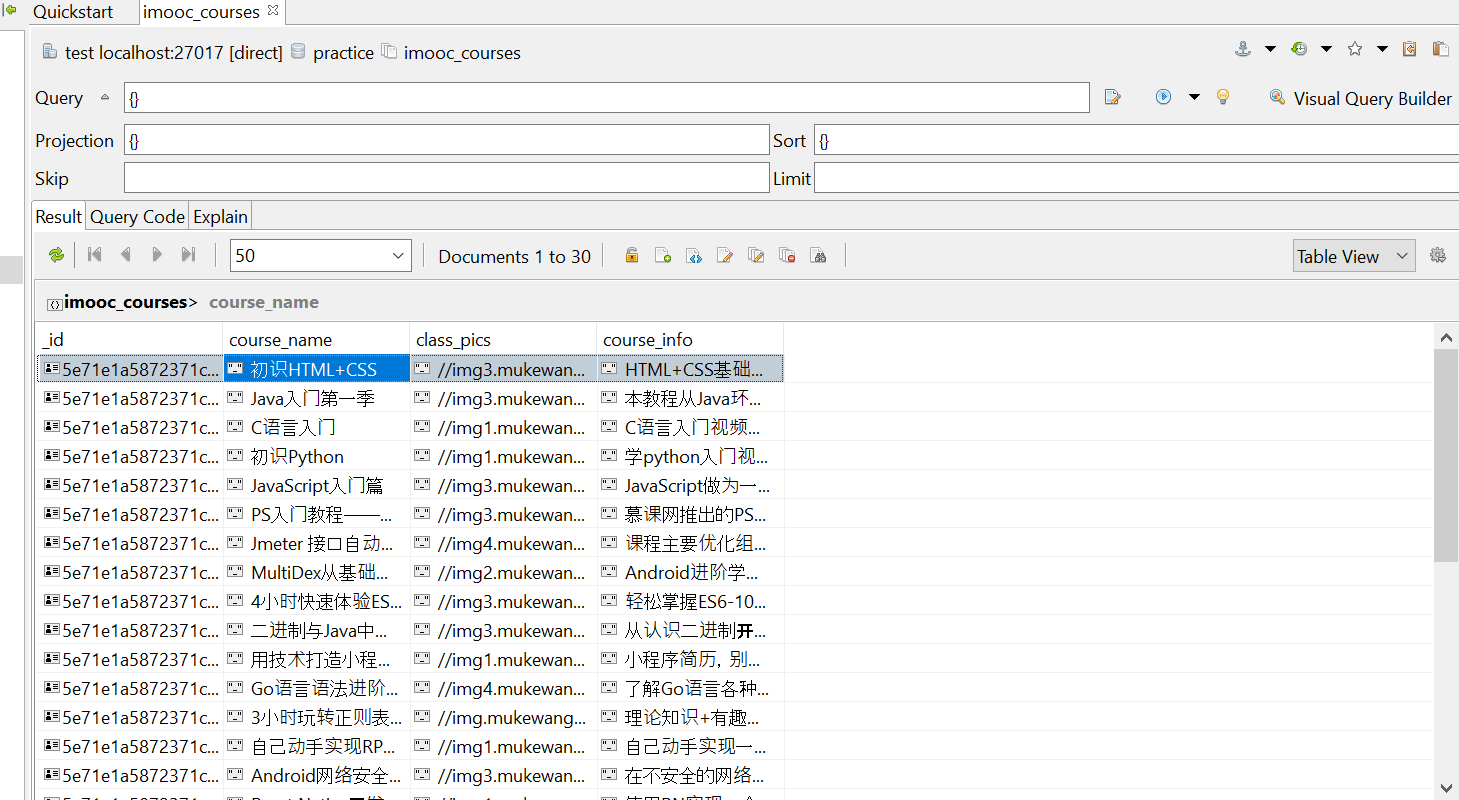
3. 小结
这一小节,我们通过实际的案例,熟悉了网址的分析,数据的存储,以及图片的存储。通过整个案例,我们需要掌握 BeautifulSoup 的用法,以及 mongoDB 数据存储的使用。掌握了这个完整的案例,同学们可以举一反三,可以使用相同的步骤轻松爬取的许多类似的网站。