Django 的 ListView 类视图详解
本小节将继续介绍 Django 中常用的 ListView 类视图并深入分析其实现原理,最后达到完全掌握该视图类的目的。
1. ListView 类视图介绍和使用
ListView 类从名字上看应该是处理和列表相关的视图,事实也是如此。我们同样基于前面 TemplateView 中实现的例子,使用 ListView 来减少代码,体验下 ListView 视图类给我们带来的便捷。
实验1:重现 TemplateView 功能;
首先我们完成前面 TemplateView 的简单功能,然后在提出几个报错的问题,这些问题比较简单,只要看下报错位置和源码信息就非常清楚了。
首先我先给出一个基本的知识:ListView 具备 TemplateView 所有的功能与属性,并做了许多扩展。那么前面由TemplateView 实现的所有示例直接将 TemplateView 替换成 ListView 也是可以运行的?
我们以最简单的一个模板例子进行演示:
在 hello_app/views.py 中新增一个视图类 TestListView1:
(django-manual) [root@server first_django_app]# cat templates/test1.html
<p>{{ content }}</p>
<div>{{ spyinx.age }}</div>
class TestListView1(ListView):
template_name = 'test1.html'
在 hello_app/urls.py 中新增一个 URLConf 配置:
urlpatterns = [
# ...
path('test\_list\_view1/', views.TestListView1.as_view(extra_context=context_data), name='test\_list\_view1')
]
使用 runserver 命令启动后,请求对应的 URL 地址,发现异常,错误原因也很明显,缺少queryset。
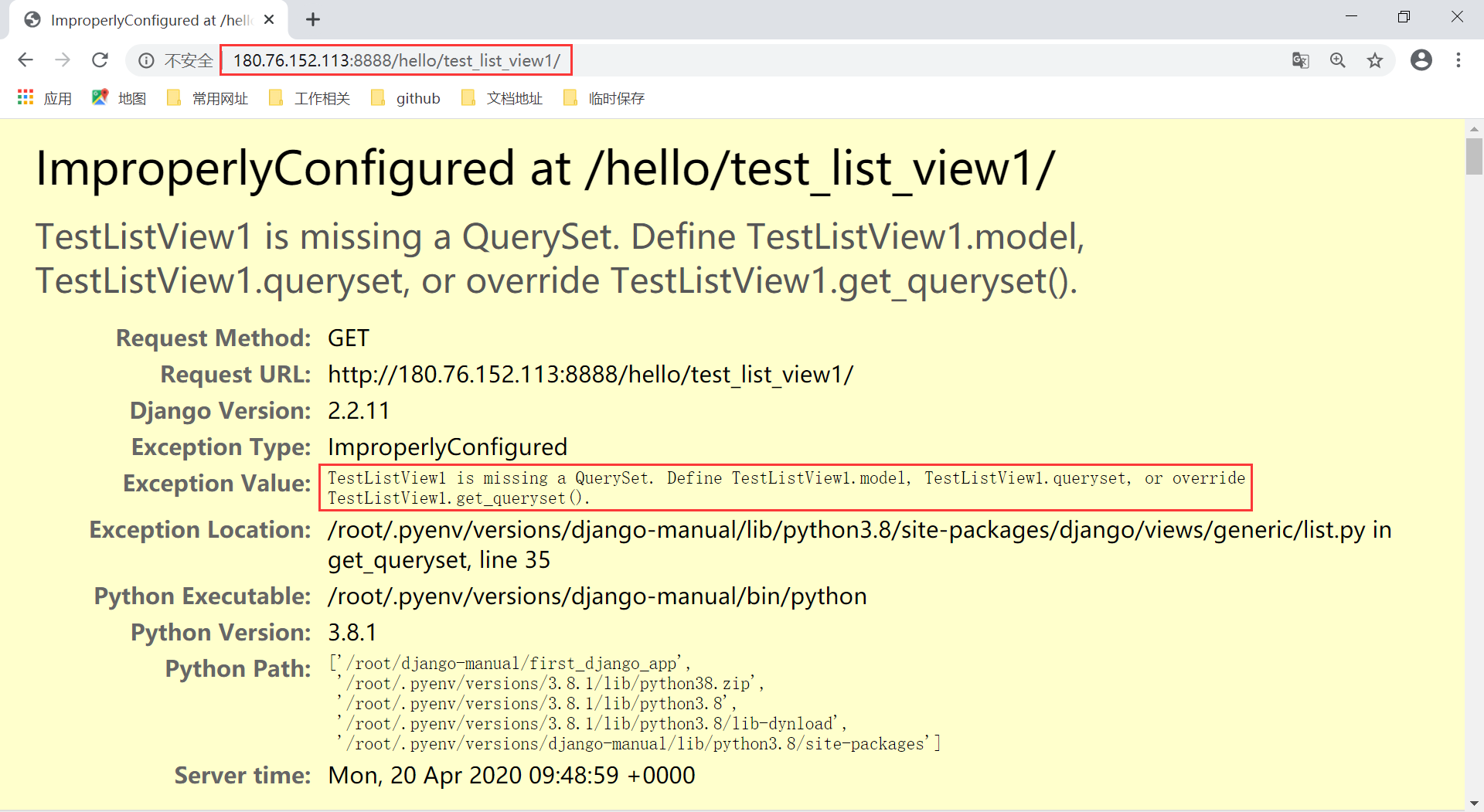
上面的出错是在父类的 get() 方法中,那么修改 hello_app/views.py 位置的视图类 TestListView1,重新定义自己的 get() 方法,如下:
class TestListView1(ListView):
template_name = 'test1.html'
def get(self, request, \*args, \*\*kwargs):
return self.render_to_response(context={'content': '正文1', 'spyinx': {'age': 29}})
启动服务后同样报错,不过这次错误不一样了,如下:
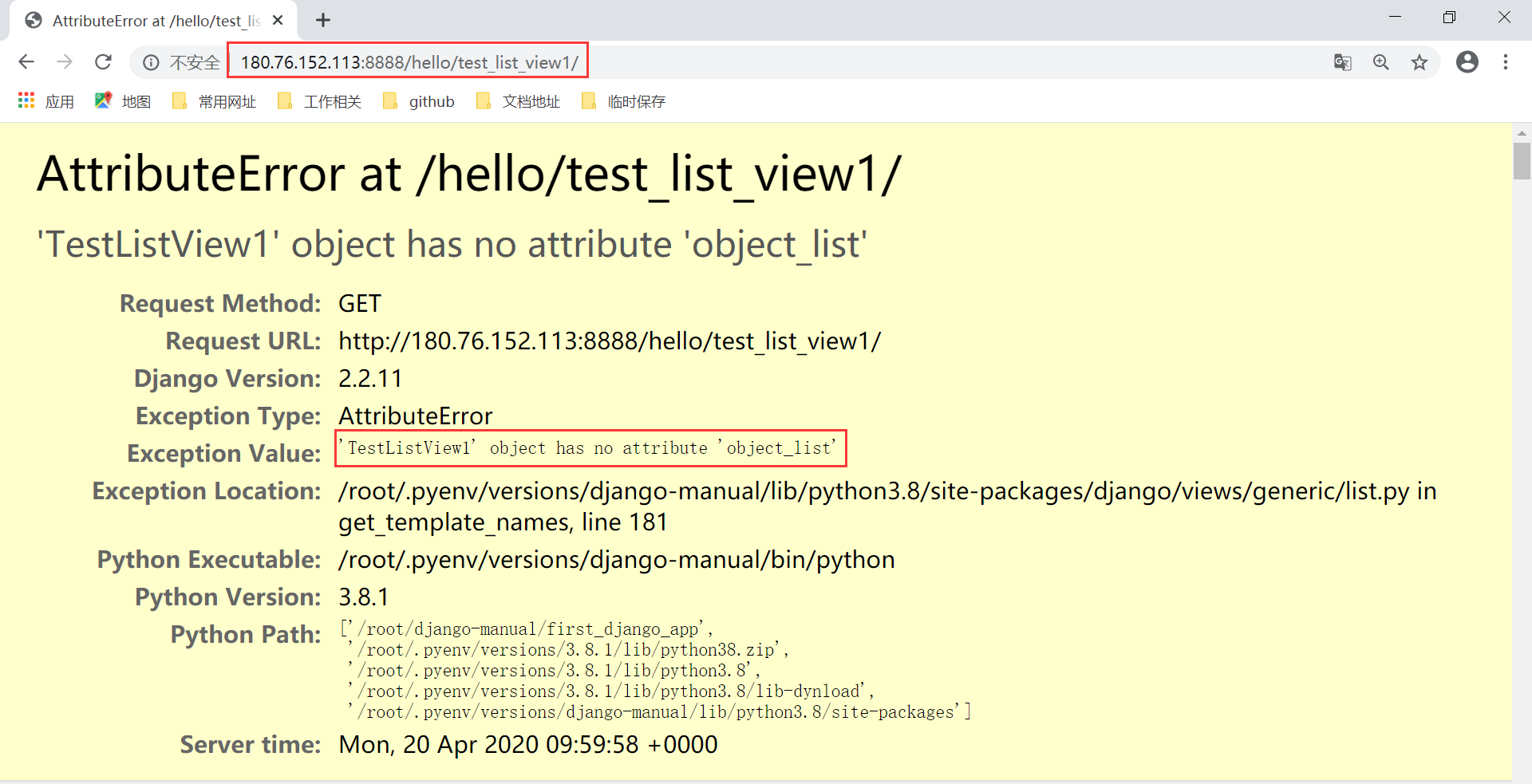
同样显示的是没有对象列表。我们通过查看源码也能轻易解决这个问题。这个问题留到后面分析原源码的时候去解决。现在直接给出两个报错的解决方案,如下:
# 解决第一个没有自定义get()函数报错
class TestListView1(ListView):
template_name = 'test1.html'
queryset = Member.objects.all()
# 另一种写法也是可以的
# model = Member
# 解决第二个自定义get()函数报错
class TestListView1(ListView):
template_name = 'test1.html'
object_list = Member.objects.all()
def get(self, request, \*args, \*\*kwargs):
return self.render_to_response(context={'content': '正文1', 'spyinx': {'age': 29}})
最后正确的结果如下,这里直接用 curl 命令请求结果显示即可。
[root@server ~]# curl http://127.0.0.01:8888/hello/test_list_view1/
<p>正文1</p>
<div>29</div>
实验2:简化分页代码。同样前面 TemplateView 做的那个显示会员列表的基础上,简化原来的代码。
准备原来的模板文件,修改分页那块代码:
(django-manual) [root@server first_django_app]# cat templates/test.html
<html>
<head>
<style type="text/css">
.page{
margin-top: 10px;
font-size: 14px;
}
.member-table {
width: 50%;
text-align: center;
}
</style>
</head>
<body>
<p>会员信息-第{{ page_obj.number }}页/共{{ paginator.num_pages }}页, 每页{{ paginator.per_page }}条, 总共{{ paginator.count }}条</p>
<div>
<table border="1" class="member-table">
<thead>
<tr>
<th>姓名</th>
<th>年龄</th>
<th>性别</th>
<th>职业</th>
<th>所在城市</th>
</tr>
</thead>
<tbody>
{% for member in members %}
<tr>
<td>{{ member.name }}</td>
<td>{{ member.age }}</td>
{% if member.sex == 0 %}
<td>男</td>
{% else %}
<td>女</td>
{% endif %}
<td>{{ member.occupation }}</td>
<td>{{ member.city }}</td>
</tr>
{% endfor %}
</tbody>
</table>
<div >
<div class="page">
</div>
</div>
</div>
</body>
</html>
添加一个新的 ListView 视图类,如下:
class TestListView2(ListView):
template_name = 'test.html'
model = Member
queryset=Member.objects.all()
paginate_by = 10
ordering = ["-age"]
context_object_name = "members"
注意:ordering 是设置显示列表的排序字段,字符串前面的 “-” 号表示的是按照这个字段倒序排列,可以设置多个排序字段。context_object_name 一定要设置,对应模板文件中的列表数据名。
添加 URLConf 配置:
urlpatterns = [
# ...
path('test\_list\_view2/', views.TestListView2.as_view(), name='test\_list\_view2')
]
启动 first_django_app 工程,从浏览器上直接访问这个 url,就能看到和前面差不多的结果了。可以传入 page 参数控制第几页,但是页大小在视图中已经固定,无法改变。
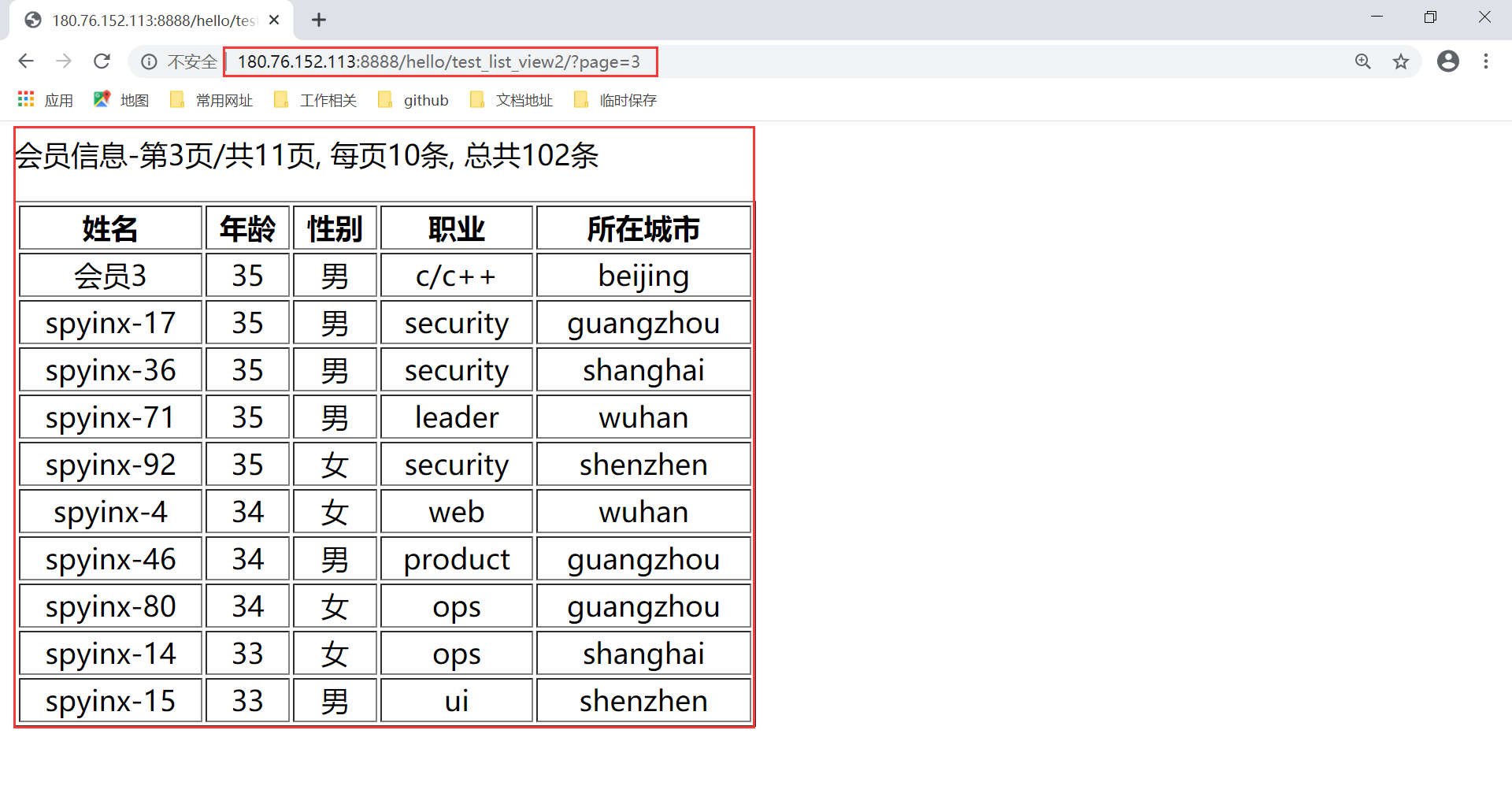
从这个简单的例子,我们可以看到,相比前面用 TemplateView 手工对数据进行分页,这里的 ListView 内部已经给我们实现了这样的功能。我们只需要简单的配置下,设置好相关属性,就能够实现对表的分页查询,这样能节省重复的代码操作,让项目看起来简洁优雅。但是我们一定要了解背后实现的逻辑,能看得懂源码,这样每一步的报错,我们都能在源码中找到原因,并迅速解决问题。接下来就是对 ListView 视图类源码的学习与分析。
2. ListView 类视图深入分析
首先在 VScode 中整体看看 ListView 的源代码,其源码路径为: djnago/views/generic/list.py。来看看ListView 类的整体继承关系:
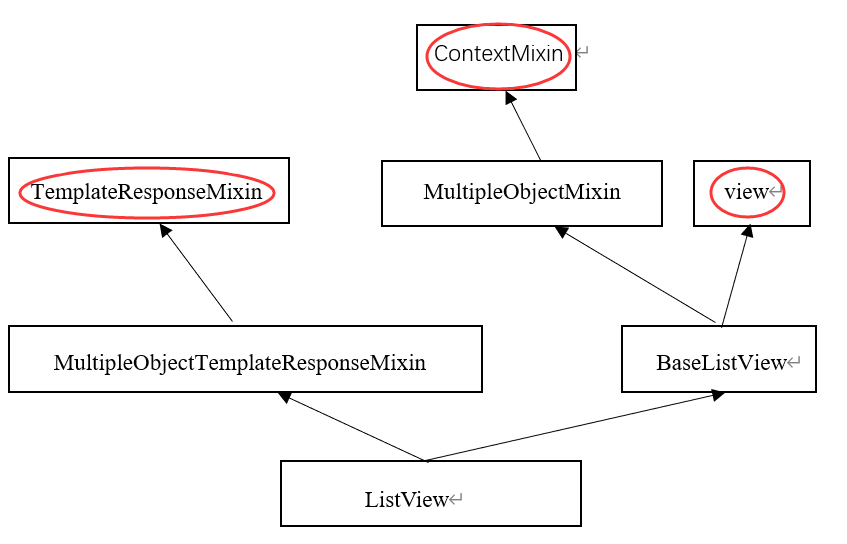
在红框中出现的对象我们是在 TemplateView 中已经遇到过了。这里可以看到 ListView 继承的比 TemplateView 要多且复杂。我们来一个个分析这些基础的类。
2.1 MultipleObjectTemplateResponseMixin
首先来看 MultipleObjectTemplateResponseMixin 这个对象,它是一个 Mixin。前面我们提到,一个 Mixin 就是一个包含一个或多个功能片段的对象。这里的 Mixin 是用于响应模板文件和展示列表数据的,它继承至前面介绍到的 TemplateResponseMixin,在 TemplateResponseMixin 上做的扩展就是重写了 get_template_names() 方法,其源码如下:
class MultipleObjectTemplateResponseMixin(TemplateResponseMixin):
"""Mixin for responding with a template and list of objects."""
template_name_suffix = '\_list'
def get\_template\_names(self):
"""
Return a list of template names to be used for the request. Must return
a list. May not be called if render\_to\_response is overridden.
"""
try:
names = super().get_template_names()
except ImproperlyConfigured:
# If template\_name isn't specified, it's not a problem --
# we just start with an empty list.
names = []
# If the list is a queryset, we'll invent a template name based on the
# app and model name. This name gets put at the end of the template
# name list so that user-supplied names override the automatically-
# generated ones.
if hasattr(self.object_list, 'model'):
opts = self.object_list.model._meta
names.append("%s/%s%s.html" % (opts.app_label, opts.model_name, self.template_name_suffix))
elif not names:
raise ImproperlyConfigured(
"%(cls)s requires either a 'template\_name' attribute "
"or a get\_queryset() method that returns a QuerySet." % {
'cls': self.__class__.__name__,
}
)
return names
从这里的代码,我们可以解释第一个实验中,第二次添加 get() 方法后报错的原因,就在这个代码段里。首先看这个 get() 函数:
def get(self, request, \*args, \*\*kwargs):
return self.render_to_response(context={'content': '正文1', 'spyinx': {'age': 29}})
这个 get() 函数调用 self.render_to_response() 方法时会调用这个 get_template_names() 方法。如果是在 TemplateView 中,直接这样写是毫无问题的,但是在 ListView 中,ListView 继承了这个 Mixin,然后调用的get_template_names() 方法正是这里的代码。这个 get_template_names() 方法相比原来的就是多了下半部分代码,在程序执行到下面的语句时,由于没有 object_list 属性值就会触发异常:
if hasattr(self.object_list, 'model'):
修正的方法很简单,只要一开始加上这个 object_list 属性值即可。对于这个object_list 属性,它其实从名字也能看出来,表示一个对象的列表值,其实是一个 QuerySet 结果集。大概知道这些之后,我们就能理解后面的代码了:
if hasattr(self.object_list, 'model'):
opts = self.object_list.model._meta
names.append("%s/%s%s.html" % (opts.app_label, opts.model_name, self.template_name_suffix))
elif not names:
raise ImproperlyConfigured(
"%(cls)s requires either a 'template\_name' attribute "
"or a get\_queryset() method that returns a QuerySet." % {
'cls': self.__class__.__name__,
}
)
对于这段代码指的是,如果self.object_list 对应着一个模型时,代码会在 names 中添加一个默认的模板文件名,我们可以在 shell 模式下理解下这些代码:
(django-manual) [root@server first_django_app]# python manage.py shell
Python 3.8.1 (default, Dec 24 2019, 17:04:00)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-39)] on linux
Type "help", "copyright", "credits" or "license" for more information.
(InteractiveConsole)
>>> from hello_app.models import Member
>>> object_list = Member.objects.all()
>>> object_list.model
<class 'hello_app.models.Member'>
>>> object_list.model._meta
<Options for Member>
>>> opts = object_list.model._meta
>>> opts.app_label
'hello_app'
>>> opts.model_name
'member'
这就很明显了,最后 names 中会加上一个额外的元素:hello_app/member_list.html。现在我们可以立马做一个实验,将实验1中的 template_name 属性值去掉,然后将原来的 test1.html 拷贝一份放到 template/hello_app 目录下,操作如下:
(django-manual) [root@server first_django_app]# mkdir templates/hello_app
(django-manual) [root@server first_django_app]# cp templates/test1.html templates/hello_app/member_list.html
class TestListView1(ListView):
# template\_name = 'test1.html'
model = Member
启动服务,然后运行发现也能成功。这就算对这个 Mixin 掌握了,我们也理解了它的代码内容并独立根据这个代码内容完成了一个实验。
(django-manual) [root@server first_django_app]# curl http://127.0.0.1:8888/hello/test\_list\_view1/
<p>正文1</p>
<div>29</div>
2.2 MultipleObjectMixin
这个 Mixin 是用来帮助视图处理多个对象的,如列表展示,分页查询都是在这里。这也是 ListView 视图类的核心所在。来看看源代码里面关于这个 Mixin 的属性和方法:
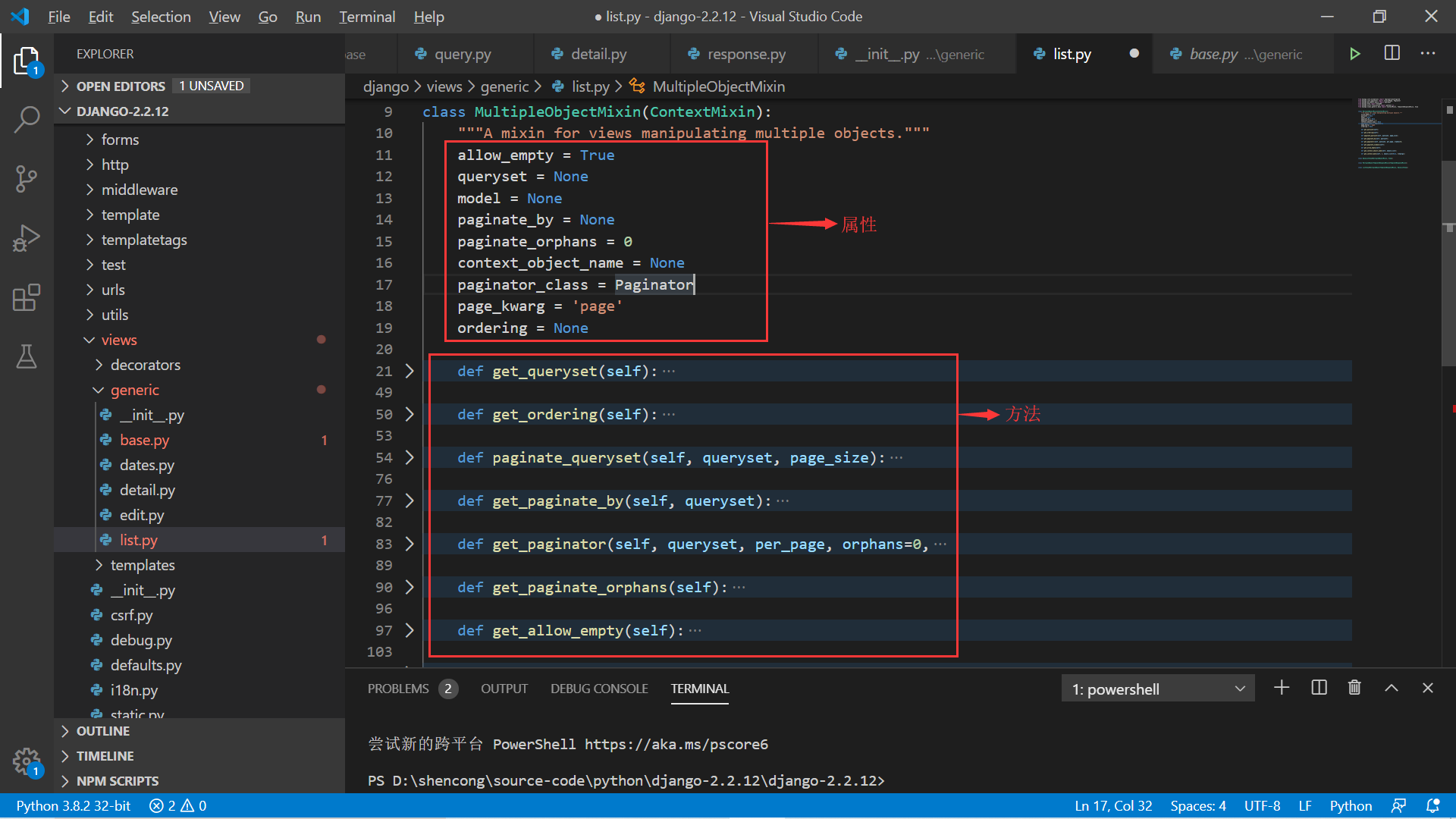
属性:
- allow_empty: 是否允许对象列表为空,默认为 True;
- queryset:对象的查询集;
- model:关联的模型;
- paginate_by: 分页大小;
- paginate_orphans: 这个比较有意思,需要通过代码来详细解释下其含义。
# 源码位置 django/core/paginator.py
class Paginator:
def \_\_init\_\_(self, object_list, per_page, orphans=0,
allow_empty_first_page=True):
self.object_list = object_list
self._check_object_list_is_ordered()
self.per_page = int(per_page)
self.orphans = int(orphans)
self.allow_empty_first_page = allow_empty_first_page
# ...
def page(self, number):
"""Return a Page object for the given 1-based page number."""
number = self.validate_number(number)
bottom = (number - 1) \* self.per_page
top = bottom + self.per_page
#这里可以看出 self.orphans 的含义
if top + self.orphans >= self.count:
top = self.count
return self._get_page(self.object_list[bottom:top], number, self)
# ...
上面的 page() 方法是根据传入的 number 获取第几页数据,每页的大小由 per_page 属性确定。我们在前面的 TemplateView 中的分页实例中知道,想要获取第几页的数据,可以按照如下公式:
# 起始位置,number从1开始
start = (number - 1) \* per_page
# 结束位置,不包括end
end = number \* per_page
# 另一种简单写法 end = start + per\_page
# 数据切片,取第number页数据
object_list[start:end]
orphans 属性的含义就体现在下面两行代码中:
if top + self.orphans >= self.count:
top = self.count
这里的含义是,如果计算出的下一页的位置加上这个 orphans 属性的值大于等于对象的总数,也就是说下一页的数据如果少于 orphans 的值,那么当前这一页需要把下一页剩余的元素都选中。举个例子,假设与102个数据,现在按照每页展示10条数据,当我展示到第10页是,元素的位置应该是 90-99,作为切片的话,应该是[90:100],即bottom=90, top=100 。假设我设置orphans=3,那么有100 + 3 > 102,即最后一页数目少于3个,因此通过上面的逻辑判断后,top=102,此时显示的列表切片为 [90:102]。
- context_object_name:这个设置上下文中对象列表名称。我们来翻看源代码,查看这个属性的含义,如下。
# 源码位置:django/views/generic/list.py
class MultipleObjectMixin(ContextMixin):
# ...
def get\_context\_object\_name(self, object_list):
"""Get the name of the item to be used in the context."""
if self.context_object_name:
return self.context_object_name
elif hasattr(object_list, 'model'):
return '%s\_list' % object_list.model._meta.model_name
else:
return None
def get\_context\_data(self, \*, object_list=None, \*\*kwargs):
"""Get the context for this view."""
queryset = object_list if object_list is not None else self.object_list
page_size = self.get_paginate_by(queryset)
context_object_name = self.get_context_object_name(queryset)
if page_size:
paginator, page, queryset, is_paginated = self.paginate_queryset(queryset, page_size)
context = {
'paginator': paginator,
'page\_obj': page,
'is\_paginated': is_paginated,
'object\_list': queryset
}
else:
context = {
'paginator': None,
'page\_obj': None,
'is\_paginated': False,
'object\_list': queryset
}
if context_object_name is not None:
context[context_object_name] = queryset
context.update(kwargs)
return super().get_context_data(\*\*context)
# ...
查看源码可以知道,这个属性不设置也是有默认值的(注意:只有在 object_list 没设置,或者不是 QuerySet 时,才返回 None 值)。通过 get_context_data() 代码中的这样一条语句:
context[context_object_name] = queryset
这样,在模板文件中,我们就可以使用 context_object_name 变量来循环显示我们的对象列表了。
- paginator_class:用于分页的类,这种写法让 django 的分页变得可扩展,我们可以提供这样的分页类来替换掉 Django 中原有的分页机制,从而实现我们自己的分页控制。这种做法在可扩展的模式中用的非常多,不过需要仔细研读分页的源码,需要定义的属性和方法才能替换官方的分页类。
- page_kwarg: 查询页号的 key 值。这个是指,查询的页号是从获取参数的这个 key 值中取出来的,可以是在 URLConf 配置中设定,也可以通过 GET 请求带参数传递过来。来看看源码里面如何使用这个属性的,具体如下。
# 源码路径:django/views/generic/list.py
class MultipleObjectMixin(ContextMixin):
# ...
def paginate\_queryset(self, queryset, page_size):
# ...
page_kwarg = self.page_kwarg
page = self.kwargs.get(page_kwarg) or self.request.GET.get(page_kwarg) or 1
# ...
# ...
- ordering:这个属性是用来设置查询列表的排序,可以放入多个排序字段。比如
ordering = ['name'],表示结果集按照 name 字段从小到大排序,如果想按照倒序的顺序,直接用ordering = ['-name']即可。
方法:
get_queryset():返回视图的对象列表:
class MultipleObjectMixin(ContextMixin):
# ...
def get\_queryset(self):
"""
Return the list of items for this view.
The return value must be an iterable and may be an instance of
`QuerySet` in which case `QuerySet` specific behavior will be enabled.
"""
if self.queryset is not None:
queryset = self.queryset
if isinstance(queryset, QuerySet):
queryset = queryset.all()
elif self.model is not None:
queryset = self.model._default_manager.all()
else:
raise ImproperlyConfigured(
"%(cls)s is missing a QuerySet. Define "
"%(cls)s.model, %(cls)s.queryset, or override "
"%(cls)s.get\_queryset()." % {
'cls': self.__class__.__name__
}
)
ordering = self.get_ordering()
if ordering:
if isinstance(ordering, str):
ordering = (ordering,)
queryset = queryset.order_by(\*ordering)
return queryset
在这里,代码逻辑也是非常清楚的。首先是需要理解 Django 的 ORM 操作。在一开始设置了 queryset 属性时,如果直接是 QuerySet 的实例,则会将用 .all() 将所有的数据取出来,得到 queryset 并返回。当然这里看代码,不设置 queryset 也是可以的,设置好关联的模型属性 model,然后通过模型的默认 manager 调用 .all() 方法也能实现同样的目标。最后,在这里还使用了 ordering 的属性值,如果有设置,则直接用 QuerySet 的 .ordering() 方法。
几个简单的获取属性值得方法,如下:
- get_ordering():获取排序字段;
- get_paginate_by(): 获取分页大小;
- get_paginator():实例化分页对象,关联 paginator_class 属性值;
- get_paginate_orphans(): 获取 paginate_orphans 这个属性值;
- get_allow_empty():获取 allow_empty 这个属性值;
- get_context_object_name():处理 context_object_name 这个属性值;
class MultipleObjectMixin(ContextMixin):
# ...
def get\_ordering(self):
"""Return the field or fields to use for ordering the queryset."""
return self.ordering
# ...
def get\_paginate\_by(self, queryset):
"""
Get the number of items to paginate by, or ``None`` for no pagination.
"""
return self.paginate_by
def get\_paginator(self, queryset, per_page, orphans=0,
allow_empty_first_page=True, \*\*kwargs):
"""Return an instance of the paginator for this view."""
return self.paginator_class(
queryset, per_page, orphans=orphans,
allow_empty_first_page=allow_empty_first_page, \*\*kwargs)
def get\_paginate\_orphans(self):
"""
Return the maximum number of orphans extend the last page by when
paginating.
"""
return self.paginate_orphans
def get\_allow\_empty(self):
"""
Return ``True`` if the view should display empty lists and ``False``
if a 404 should be raised instead.
"""
return self.allow_empty
def get\_context\_object\_name(self, object_list):
"""Get the name of the item to be used in the context."""
if self.context_object_name:
return self.context_object_name
elif hasattr(object_list, 'model'):
return '%s\_list' % object_list.model._meta.model_name
else:
return None
# ...
- paginate_queryset():获取分页数据以及分页信息。该函数会被 get_context_data() 方法调用生成上下文数据,用于填充模板中的变量内容。该部分源码会结合 get_context_data() 方法一起在下一小节中详细介绍到;
- get_context_data():获取渲染模板的上下文数据,也即分页列表元素、分页信息等,在下一部分内容会详细介绍该函数中的内容。
2.3 BaseListView
讲完上面的 MultipleObjectMixin 对象,ListView 视图的基本功能其实就分析完了。 BaseListView 类继承了 View 和 MultipleObjectMixin,并多添加了一个 get() 方法。这也是 ListView 能直接处理 get 请求的原因。实验1中的第一个报错也是源自这里:self.object_list = self.get_queryset() 。只有定义了 queryset 或者 model属性时,才能正常执行下去。
class BaseListView(MultipleObjectMixin, View):
"""A base view for displaying a list of objects."""
def get(self, request, \*args, \*\*kwargs):
# 获取对象列表
self.object_list = self.get_queryset()
# 是否设置允许为空
allow_empty = self.get_allow_empty()
if not allow_empty:
# 下面的if用于判断数据是否为空,然后相应设置is\_empty值
if self.get_paginate_by(self.object_list) is not None and hasattr(self.object_list, 'exists'):
is_empty = not self.object_list.exists()
else:
is_empty = not self.object_list
# 在不许为空的条件中,如果为空直接抛出404异常
if is_empty:
raise Http404(_("Empty list and '%(class\_name)s.allow\_empty' is False.") % {
'class\_name': self.__class__.__name__,
})
# 获取分页相关的数据
context = self.get_context_data()
# 渲染模板并返回
return self.render_to_response(context)
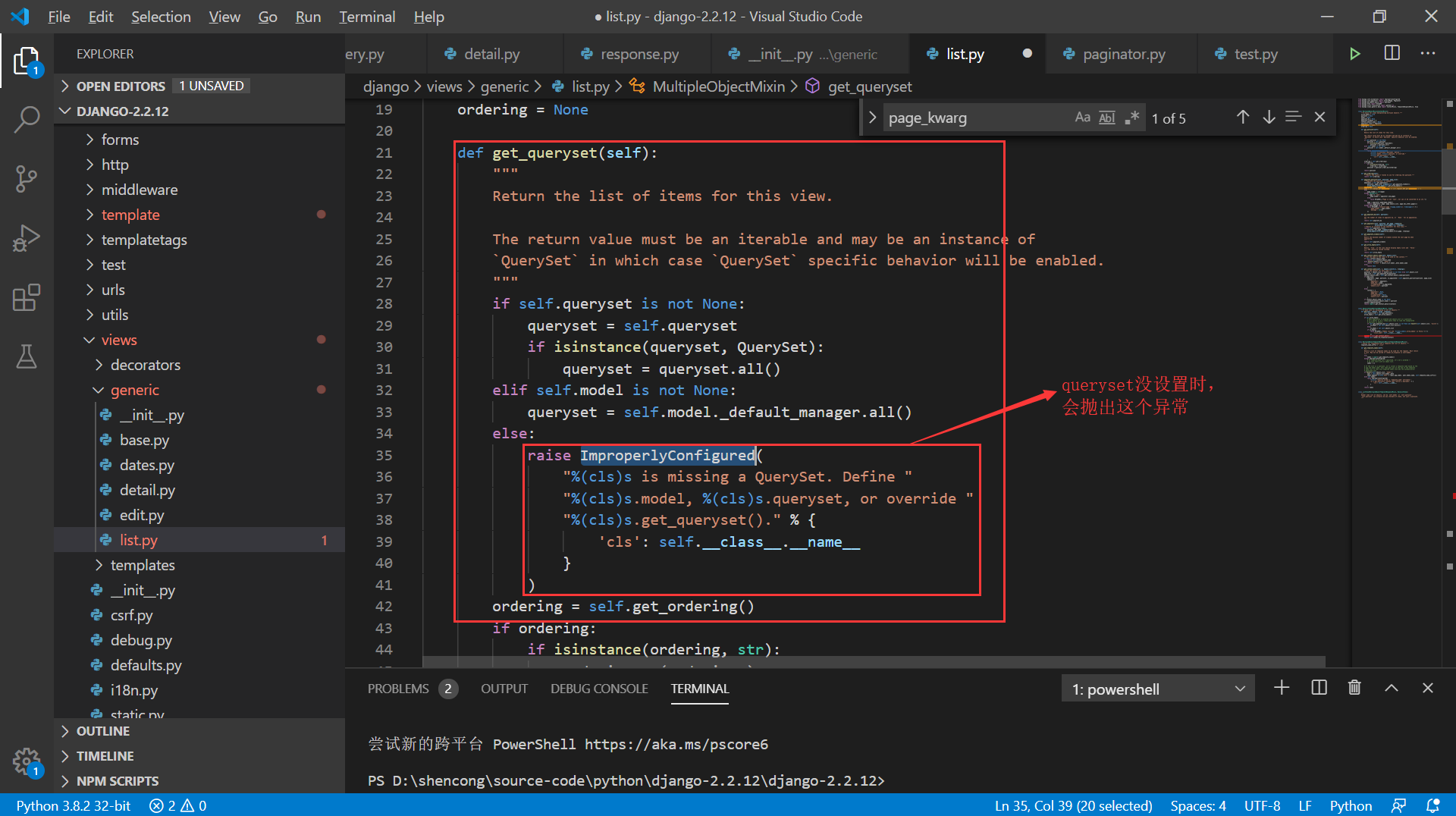
可以看到,这段代码执行的过程非常简单,很容易能看懂,我已经在上面做好了简单的注释。这段代码中最重要的部分就在这一句中: context = self.get_context_data()。这段代码是要获取相应的分页数据结果,然后调用 self.render_to_response(context) 来返回经过渲染的模板文件,最后就是我们看到的那个会员列表页面。self.get_context_data() 方法就是上面的 Mixin 提供的,函数源码如下:
def get\_context\_data(self, \*, object_list=None, \*\*kwargs):
"""Get the context for this view."""
# 获取对象列表
queryset = object_list if object_list is not None else self.object_list
# 获取分页大小
page_size = self.get_paginate_by(queryset)
# 获取context\_object\_name,我们实验2中设置的就是members,对应着模板中的变量
context_object_name = self.get_context_object_name(queryset)
if page_size:
# 核心的处理就是这一句,根据指定的分页大小对数据集进行分析,返回分页的对象列表,分页信息、是否分页等
paginator, page, queryset, is_paginated = self.paginate_queryset(queryset, page_size)
context = {
'paginator': paginator,
'page\_obj': page,
'is\_paginated': is_paginated,
'object\_list': queryset
}
else:
# 没有设置分页大小,就是获取全部数据,不进行分页
context = {
'paginator': None,
'page\_obj': None,
'is\_paginated': False,
'object\_list': queryset
}
# 设置模板中对象列表变量的数据
if context_object_name is not None:
context[context_object_name] = queryset
# context中再添加额外传入的数据
context.update(kwargs)
# 最后调用父类的get\_context\_data()方法并返回
return super().get_context_data(\*\*context)
上面的获取上下文数据的代码也比较简单,有分页大小就调用self.paginate_queryset() 方法查询分页数,没有分页大小就使用全部对象列表,然后构造 context 值,最后调用父类的 get_context_data() 方法并返回。可以看到,整个获取上下文数据的最核心处理就是 self.paginate_queryset() 这个方法了。它也是由上面介绍的那个 Mixin 提供的,代码如下:
def paginate\_queryset(self, queryset, page_size):
"""Paginate the queryset, if needed."""
# 核心处理就是这一句
paginator = self.get_paginator(
queryset, page_size, orphans=self.get_paginate_orphans(),
allow_empty_first_page=self.get_allow_empty())
# 查询第几页的key值,默认是"page"
page_kwarg = self.page_kwarg
# 第几页的值会从kwargs或者GET请求中获取,对应的key就是上面的page\_kwarg,没有就默认为1
page = self.kwargs.get(page_kwarg) or self.request.GET.get(page_kwarg) or 1
try:
# 会强制转成int
page_number = int(page)
except ValueError:
# 当强制转换异常时,处理逻辑也很清晰
if page == 'last':
page_number = paginator.num_pages
else:
raise Http404(_("Page is not 'last', nor can it be converted to an int."))
try:
# 生成对应的page实例。一切正常时,返回我们所需要的数据,否则抛出异常
page = paginator.page(page_number)
return (paginator, page, page.object_list, page.has_other_pages())
except InvalidPage as e:
raise Http404(_('Invalid page (%(page\_number)s): %(message)s') % {
'page\_number': page_number,
'message': str(e)
})
当这部分代码能看懂时,前面实验2部分的整个内部逻辑,你差不多也就弄清楚了。虽然我们看着只需要配置几个属性,但是在 Django 内部是替我们做了许多工作的,如果这部分工作并不是你想要的,这时候,就需要依据你自己的业务逻辑重写相应的函数了。如果能掌握整个 ListView 视图的执行流程,在继承它的时候就会感到胸有成竹,有错了就去根据错误提示追踪下源码,这样就不会再碰到错误时,不知道从何下手。所以,阅读源码是在学习 Django 这样的 Web 框架时,非常重要的一个技能,而且很多关于 Django 的功能和用法我们都可以通过源码来获取。
最后,我们来看看 ListView 的代码,其实就是单纯继承前面那个处理多个对象的 Mixin 和这个 BaseListView:
class ListView(MultipleObjectTemplateResponseMixin, BaseListView):
"""
Render some list of objects, set by `self.model` or `self.queryset`.
`self.queryset` can actually be any iterable of items, not just a queryset.
"""
3. 小结
本节中,我们使用 ListView 完成了两个小实验,对 ListView 有了一个基本的了解。接下来,我们深入学习了和 ListView 相关的类和 mixin,并在源码学习中完成了几个简单的实验。在完成本节学习后,是不是对 ListView 有了全新的了解?之后使用 ListView 报错后,是不是能迅速找到问题所在?如果是的话,那么本节也算起了一点小小的作用,作为本文作者,我也将感到无比荣耀。