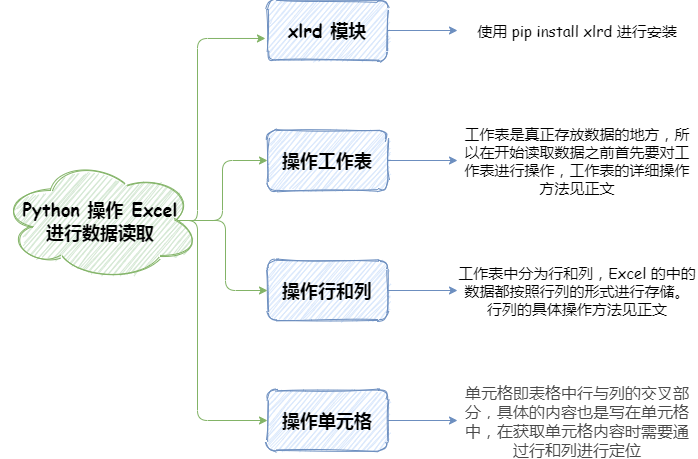
Python 操作 Excel 数据表:数据读取
从这节课开始,我们就正式的进入 Python 办公自动化的学习中去了,上一个小节说过我们的课程划分了四部分。那么这节课就是课程第一部分 “Office 自动化” 的第一课:用 Python 操作 Excel 数据表。
Excel 由于其直观的界面、出色的计算功能和图表工具,目前已经成为最流行的个人计算机数据处理软件,在日常办公中必不可少。而借助于 Python 可以让用户更加高效的使用 Excel,减少重复性的工作,我们之前也说过,Python 拥有大量的第三方库可以帮助我们完成丰富的场景,这节课我们将学习用来操作 Excel 的第三方库:xlrd。
1. xlrd 模块
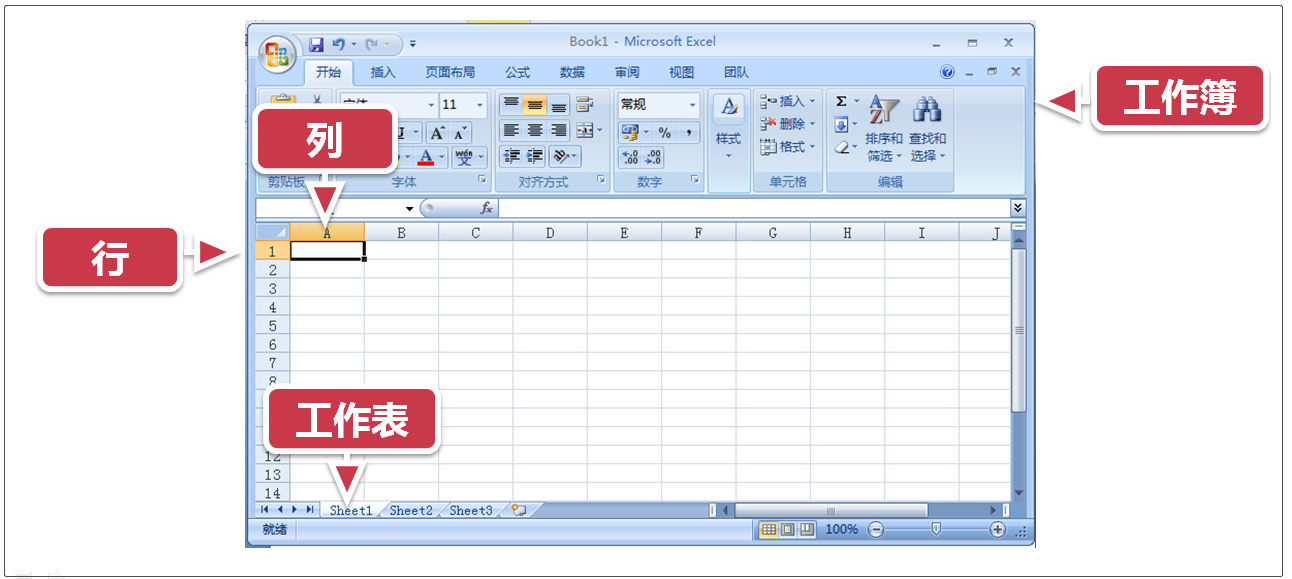
xlrd 是一个用于从 Excel 文件(.xls/.xlsx)读取数据和格式化信息的库。在内容正式开始前,建议先回顾下 Excel 文件中的一些名词概念,即工作簿、工作表、行、列、单元格,如下图所示。
1.1 安装
xlrd 是 Python 的第三方库,使用前需要通过以下命令进行安装:
pip install xlrd
1.2 使用步骤
步骤 1:导入 xlrd 模块
通过 import xlrd 完成导入。
import xlrd
步骤 2:加载 Excel 文件
import xlrd
data = xlrd.open_workbook("data.xlsx")
open_workboox () 方法返回当前工作簿的一个实例,后续的操作都是通过这个实例进行。
步骤 3:读取数据
拿到 Excel 的实例后,即可通过 xlrd 模块提供的方法进行数据的读取。
2. xlrd 模块使用
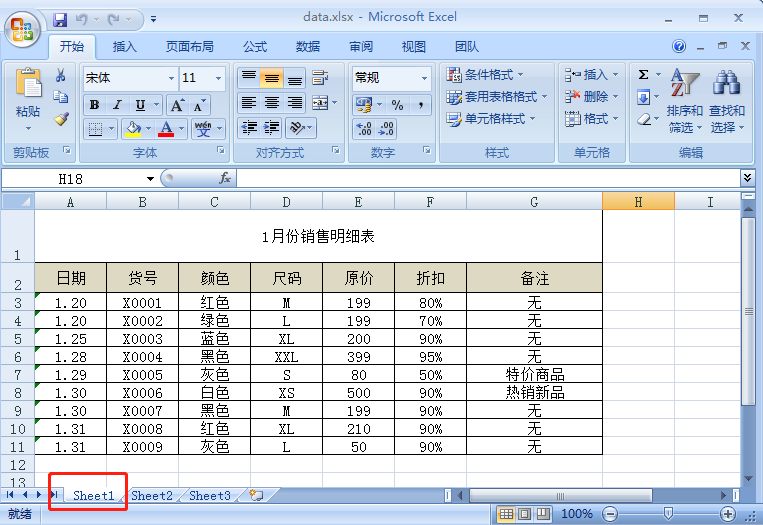
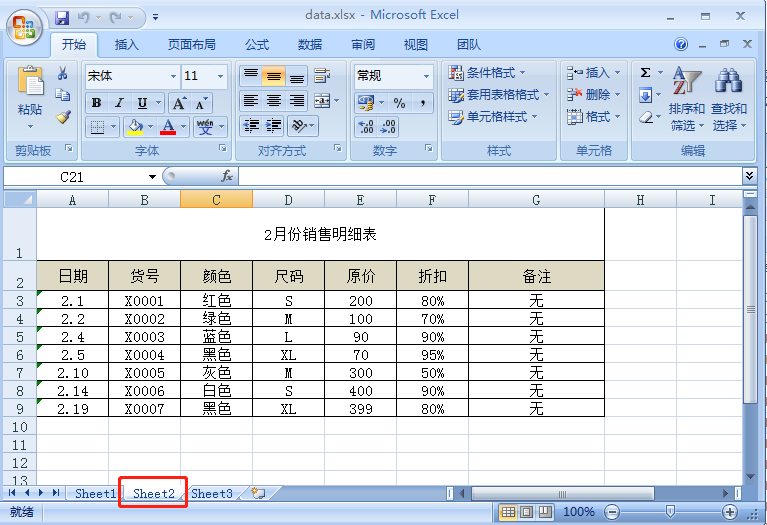
这部分内容我们将针对 Excel 中常用概念:工作表、列、行、单元格,依次对应介绍 xlrd 模块的操作方法。接下来的所有操作都将围绕工作簿 data.xlsx 进行,data.xlsx 中存放的是一份某店铺的销售明细,data.xlsx 中包括 2 个工作表(sheet),每个工作表内容如下图所示:
2.1 xlrd 操作 Excel 工作表
在一个工作簿中可以定义多个工作表(sheet),而数据真正所存放的位置正是在工作表中,所以在开始读取数据前,首先需要对工作表进行操作,常用属性,见下表:
| 属性 | 描述 |
|---|---|
| nsheets | 获取工作簿中 sheet 的数量 |
对应代码中访问,如下所示:
import xlrd
data = xlrd.open_workbook("data.xlsx")
print(data.nsheets) # 输出:2
通过上述代码,可以得知在 data.xlsx 文件中,共有 2 个工作表(sheet)。xlrd 操作工作表(sheet)常用方法,见下表。
| 方法 | 描述 |
|---|---|
| sheets() | 获取所有 sheet 的对象,以列表形式显示 |
| sheet_by_index(sheetx ) | 根据索引返回对应的 sheet |
| sheet_by_name(sheet_name ) | 通过 sheet 名称返回对应 sheet |
| sheet_names() | 返回工作簿中所有 sheet 名称 |
| sheet_loaded(sheet_name_or_index ) | 通过 sheet 名称或索引判断该 sheet 是否导入成功,返回值为 bool 类型,True 表示已导入,False 表示未导入 |
| unload_sheet(sheet_name_or_index ) | 通过 sheet 名称或索引取消 sheet 加载 |
下面来具体看下每个方法的使用:
sheets () 方法
import xlrd
data = xlrd.open_workbook("data.xlsx")
print(data.sheets())
# 输出:[<xlrd.sheet.Sheet object at 0x02A28EB0>, <xlrd.sheet.Sheet object at 0x02A28F30>, <xlrd.sheet.Sheet object at 0x02A28EF0>]
代码解释:sheets () 方法为获取 excel 中所有的工作表(sheet)对象,目前 data.xlsx 中共包含三个 sheet,所以这里输出返回三个 sheet 对象,后续可以通过每个 sheet 对象来对 sheet 中的行、列、单元格进行操作。
sheet_by_index () 方法
import xlrd
data = xlrd.open_workbook("data.xlsx")
print(data.sheet_by_index(0))
# 输出:<xlrd.sheet.Sheet object at 0x02A08EB0>
代码解释:sheet_by_index () 方法是根据索引获取 excel 中的工作表(sheet),上述代码中传递 0,表示获取索引为 0 的 sheet 对象,可以通过 sheets () 方法的输出结果与 sheet_by_index () 方法的输出结果进行对比,即可发现,第一个 sheet 在内存中的位置是相同的,都是 0x02A08EB0。
sheet_by_name () 方法
import xlrd
data = xlrd.open_workbook("data.xlsx")
print(data.sheet_by_name("Sheet1"))
# 输出:<xlrd.sheet.Sheet object at 0x02A08EB0>
代码解释:sheet_by_name () 方法是根据工作表名称来获取 excel 中的工作表(sheet),上述代码中传递 “Sheet1”,对应到 data.xlsx 中即第一个工作表。
sheet_names () 方法
import xlrd
data = xlrd.open_workbook("data.xlsx")
print(data.sheet_names())
# 输出:['Sheet1', 'Sheet2', 'Sheet3']
代码解释:sheet_names () 方法为返回工作簿中所有工作表的名称,本小节中 data.xlsx 共包含 3 个工作表,固这里返回 [‘Sheet1’, ‘Sheet2’, ‘Sheet3’]。
sheet_loaded () 方法
import xlrd
data = xlrd.open_workbook("data.xlsx")
print(data.sheet_loaded(0))
# 输出:True
代码解释:sheet_loaded () 方法表示指定工作表是否已导入(加载),返回值为布尔类型,其中参数可以为索引或工作表名称,代码中传递为 0,表示检查第一个工作表是否已导入(加载),xlrd 模块在使用 open_workbook () 方法加载工作簿时,其所有工作表均已加载完成,所以在输出时,输出 True。
unload_sheet () 方法
import xlrd
data = xlrd.open_workbook("data.xlsx")
print(data.sheet_loaded(0))#输出:True
data.unload_sheet(0)
print(data.sheet_loaded(0))#输出:False
print(data.sheet_loaded(1))#输出:True
代码解释:unload_sheet () 方法表示取消指定工作表导入(加载),其中参数可以为索引或工作表名称,代码中传递为 0,表示取消第一个工作表导入(加载),代码中共做了三次输出,第一次为初始判断第一个工作表是否加载,返回 True,第二次输出时,第一个工作表已经被取消加载,固输出 False,第三次输出为第二个工作表是否加载,输出 True。
2.2 xlrd 操作 Excel 列
xlrd 中在工作表中对 Excel 列进行操作,常用属性,见下表。
| 属性 | 描述 |
|---|---|
| ncols | 获取指定工作表中总列数 |
对应代码中访问,如下所示:
import xlrd
data=xlrd.open_workbook("data.xlsx")
sheet=data.sheet_by_index(0)
print(sheet.ncols) #输出 8
想要对 Excel 列进行操作,首先需要找到具体的工作表,在上述代码中,通过 sheet_by_index 方法得到第一个工作表(sheet),工作表索引从 0 开始,对应工作簿中效果为从左到右排列。得到具体的工作表后,访问 ncols 属性输出 8,即表示在 data.xlsx 文件中第一个工作表(sheet)共有 8 列数据。
xlrd 中操作 Excel 列的常用方法,见下表。
| 方法 | 描述 |
|---|---|
| col(colx) | 返回给定列所有单元格对象组成的列表 |
| col_values(colx[,start_rowx,end_rowx,]) | 返回给定列中单元格的值 |
| col_types(colx[,start_rowx,end_rowx,]) | 返回给定列中单元格类型 |
下面来具体看下每个方法的使用:
col () 方法
import xlrd
data = xlrd.open_workbook("data.xlsx")
sheet=data.sheet_by_index(0)
print(sheet.col(1))
#输出:[empty:'', text:'货号', text:'X0001', text:'X0002', text:'X0003', text:'X0004', text:'X0005', text:'X0006', text:'X0007', text:'X0008', text:'X0009']
代码解释:col () 方法返回指定列所有单元格对象组成的列表,代码中传递 1,表示获取索引为 1 的列,由于索引从 0 开始,即表示获取的是第 2 列的所有单元格对象。
col_values () 方法
import xlrd
data = xlrd.open_workbook("data.xlsx")
sheet=data.sheet_by_index(0)
print(sheet.col_values(1))
#输出:['', '货号', 'X0001', 'X0002', 'X0003', 'X0004', 'X0005', 'X0006', 'X0007', 'X0008', 'X0009']
代码解释:col_values () 方法返回指定列所有单元格的值,代码中传递 1,即表示获取的是第 2 列的所有单元格的值,以列表的形式返回。
col_types () 方法
import xlrd
data = xlrd.open_workbook("data.xlsx")
sheet=data.sheet_by_index(0)
print(sheet.col_types(4))
#输出:[0, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2]
代码解释:col_types () 方法返回指定列所有单元格的类型,代码中传递 5,表示获取索引为 4 的列,由于索引从 0 开始,即表示获取的是第 5 列的所有单元格的类型。返回结果中,0 表示空,1 表示字符串,2 表示数字。
2.3 xlrd 操作 Excel 行
xlrd 中在工作表中对 Excel 行进行操作,常用属性,见下表。
| 属性 | 描述 |
|---|---|
| nrows | 获取指定工作表中总行数 |
对应代码中访问,如下所示:
import xlrd
data=xlrd.open_workbook("data.xlsx")
sheet=data.sheet_by_index(0)
print(sheet.nrows) #输出 4
在上述代码中,通过 sheet_by_index 方法得到第一个工作表(sheet),访问 nrows 属性输出 4,即表示在 data.xlsx 文件中第一个工作表(sheet)共有 4 行数据。
xlrd 中操作 Excel 行的常用方法,见下表。
| 方法 | 描述 |
|---|---|
| row(rowx) | 返回给定行所有单元格对象 |
| row_values(rowx[,start_colx,end_colx,]) | 返回给定行中单元格的值 |
| row_types(rowx[,start_colx,end_colx,]) | 返回给定行中单元格类型 |
下面来具体看下每个方法的使用:
row () 方法
import xlrd
data = xlrd.open_workbook("data.xlsx")
sheet=data.sheet_by_index(1)
print(sheet.row(1))
#输出:[text:'日期', text:'货号', text:'颜色', text:'尺码', text:'原价', text:'折扣', text:'备注']
代码解释:row () 方法返回指定行所有单元格对象组成的列表,代码中传递 1,表示获取索引为 1 的行,由于索引从 0 开始,即表示获取的是第 2 行的所有单元格对象。
row_values () 方法
import xlrd
data = xlrd.open_workbook("data.xlsx")
sheet=data.sheet_by_index(1)
print(sheet.row_values(1))
#输出:['日期', '货号', '颜色', '尺码', '原价', '折扣', '备注']
代码解释:row_values () 方法返回指定行所有单元格的值,代码中传递 1,即表示获取的是第 2 行的所有单元格的值,以列表的形式返回。
row_types () 方法
import xlrd
data = xlrd.open_workbook("data.xlsx")
sheet=data.sheet_by_index(0)
print(sheet.row_types(3))
#输出:array('B', [1, 1, 1, 1, 2, 2, 1])
代码解释:row_types () 方法返回指定行所有单元格的类型,代码中传递 3,表示获取索引为 3 的行,由于索引从 0 开始,即表示获取的是第 4 行的所有单元格的类型。返回结果中,1 表示空,2 表示数字。
2.4 xlrd 操作 Excel 单元格
单元格即表格中行与列的交叉部分,具体的内容也是写在单元格中,在获取单元格内容时需要通过行和列进行定位。常用操作单元格方法,见下表。
| 方法 | 描述 |
|---|---|
| cell(rowx,colx) | 返回指定行和列中单元格对象 |
| cell_value(rowx,colx) | 返回指定行和列中单元格的值 |
| cell_type(rowx,colx) | 返回指定行和列中单元格的类型 |
下面来具体看下每个方法的使用:
cell () 方法
import xlrd
data = xlrd.open_workbook("data.xlsx")
sheet=data.sheet_by_index(0)
print(sheet.cell(1,2))
#输出:text:'颜色'
代码解释:cell () 方法根据指定的行索引和列索引,返回指定单元格对象。代码中传递 1,2,表示获取行所以为 1,列索引为 2 的单元格对象,即第 2 行第 3 列的单元格对象。
cell_value () 方法
import xlrd
data = xlrd.open_workbook("data.xlsx")
sheet=data.sheet_by_index(1)
print(sheet.cell_value(1,2))
#输出:颜色
代码解释:cell_value () 方法返回指定行索引和列索引符合条件的单元格的值。代码中传递 1,2,即第 2 行第 3 列的单元格的值。
cell_type () 方法
import xlrd
data = xlrd.open_workbook("data.xlsx")
sheet=data.sheet_by_index(0)
print(sheet.cell_type(1,2))
#输出:1
代码解释:cell_type () 方法返回指定行索引和列索引符合条件的单元格类型。代码中传递 1,2,即第 2 行第 3 列的单元格类型,输出结果 1 表示为字符串类型。
除了上述方法可以获取到单元格中内容之外,也可以在获取到单元格对象后,通过单元格对象属性对单元格的值、类型进行获取,见下表。
| 属性 | 描述 |
|---|---|
| ctype | 获取单元格数据类型 |
| value | 获取单元格中的值 |
下面来具体看下每个属性的使用:
ctype 方法
import xlrd
data = xlrd.open_workbook("data.xlsx")
sheet=data.sheet_by_index(0)
print(sheet.cell(1,2).ctype)
#输出:1
代码解释:获取到单元格对象后,通过 ctype 属性来获取单元格数据类型。代码中通过 cell (1,2) 表示获取到了行索引为 1,列索引为 2 的单元格对象,通过 ctype 属性获取单元格类型,输出 1 表示为字符串类型。
value 方法
import xlrd
data = xlrd.open_workbook("data.xlsx")
sheet=data.sheet_by_index(0)
print(sheet.cell(1,2).value)
#输出:颜色
代码解释:获取到单元格对象后,通过 value 属性来获取单元格的值。代码中通过 cell (1,2) 表示获取到了行索引为 1,列索引为 2 的单元格对象,通过 value 属性获取单元格的值。
3. 小结
本节课程我们主要学习了 xlrd 模块的使用。本节课程的重点如下:
- 回顾 Excel 中各名词概念;
- 了解 xlrd 模块作用及使用步骤;
- 掌握 xlrd 模块操作 Excel 工作表(sheet)、行、列、单元格的常用属性和方法。