Zookeeper 集群模式
1. 前言
在我们的生产环境中,Zookeeper 的单机模式无法保证 Zookeeper 服务的高可用性,也就是我们常说的单点故障问题,性能也存在瓶颈。所以在生产环境中,Zookeeper 最好的使用方式就是 Zookeeper 的集群模式,这样不仅在性能方面比单机模式更好,服务的高可用性也得到了保障。本节我们就来学 Zookeeper 集群模式的部署,以及在集群模式下的 Zookeeper 服务是如何工作的。
2. Zookeeper 集群模式部署
在上一节中,我们学习了 Zookeeper 的单机模式,我们可以在此基础上进行 Zookeeper 集群模式的部署。Zookeeper 集群的数量通常是大于等于 3 的奇数,比如 3、5、7,但也不宜太多,太多的集群数量会影响集群之间的同步性能。这里我们以 3 的集群数量来进行讲解。
Tips: Zookeeper 集群的数量为什么需要奇数个呢?如果采用偶数,在 Leader 节点选举投票时,有可能会产生两个 Leader 节点,两个 Leader 都不能满足大多数选票的原则,这时就会出现脑裂问题。
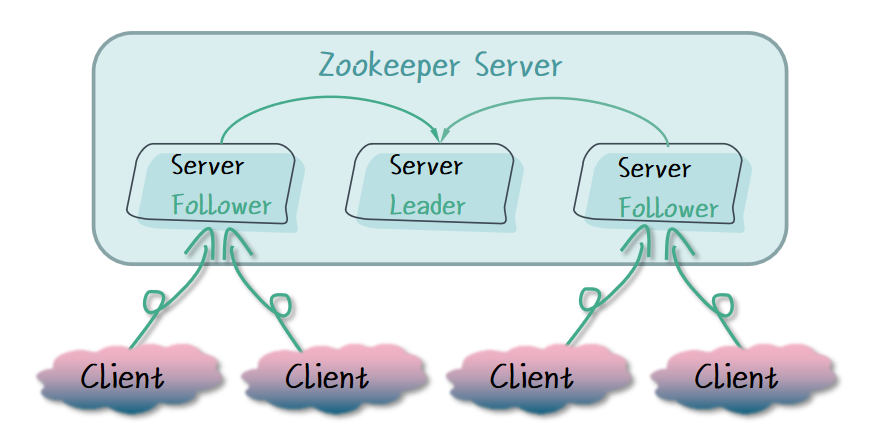
2.1 集群环境准备
我们需要提供相同环境的 3 台虚拟机,Zookeeper 和 JDK 环境都已准备好。
| Server | IP |
|---|---|
| Server1 | 192.168.0.77 |
| Server2 | 192.168.0.88 |
| Server3 | 192.168.0.99 |
Tips: 同学们进行配置的时候使用自己的服务器 IP 地址进行配置。
接下来我们来对这 3 台虚拟机中的 Zookeeper 进行配置。
2.2 集群的 myid 配置
myid 文件的内容为服务器编号,服务器编号我们可以自定义,只要每台机器不同即可。
首先我们进入 Zookeeper 的根目录,在 data 文件夹中新建 myid 文件,添加服务器编号,操作如下:
# 进入 Zookeeper 根目录
cd /usr/local/zookeeper/apache-zookeeper-3.6.1-bin/
Server1 的 myid 配置为 1 :
# echo 在文件末尾添加内容,若文件不存在,会新建此文件
echo '1' > data/myid
Server2 的 myid 配置为 2:
# echo 在文件末尾添加内容,若文件不存在,会新建此文件
echo '2' > data/myid
Server3 的 myid 配置为 3:
# echo 在文件末尾添加内容,若文件不存在,会新建此文件
echo '3' > data/myid
配置好了 myid,接下来我们对 zoo.cfg 进行配置。
2.3 集群的 cfg 配置
我们进入 Zookeeper 根目录中的 conf 文件夹,编辑 zoo.cfg 文件:
cd /usr/local/zookeeper/apache-zookeeper-3.6.1-bin/conf/
vi zoo.cfg
在 zoo.cfg 配置文件的末尾添加以下配置,这里每台机器都是同样的配置。
server.1=192.168.0.77:2888:3888
server.2=192.168.0.88:2888:3888
server.3=192.168.0.99:2888:3888
我们来介绍一下这一段配置的含义,以 server.1=192.168.0.77:2888:3888 为例:
- server.1: 表示编号为 1 的服务器,这里的 1 要与该服务器的 myid 文件的内容相同;
- 192.168.0.77: 该服务器的地址;
- 2888: 服务之间通信的端口,默认值 2888;
- 3888: 服务之间选举的端口,默认值 3888。
到这里我们的配置部分就完成了,接下来我们依次启动 3 台机器的 Zookeeper 服务。
2.4 启动服务
进入 bin 目录,使用 start 命令启动 Zookeeper 服务:
cd /usr/local/zookeeper/apache-zookeeper-3.6.1-bin/bin/
# 启动命令
./zkServer.sh start
启动完成控制台会输出以下内容:
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/apache-zookeeper-3.6.1-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
2.5 查看服务状态
完成 3 台机器的 Zookeeper 服务启动后,我们使用 status 命令来观察 Zookeeper 服务的状态:
./zkServer.sh status
Server1:
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/apache-zookeeper-3.6.1-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
# follower 表示为集群中的从节点
Mode: follower
Server2:
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/apache-zookeeper-3.6.1-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
# follower 表示为集群中的从节点
Mode: follower
Server3:
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/apache-zookeeper-3.6.1-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
# leader 表示为集群中的主节点
Mode: leader
我们可以观察到,Server1 和 Server2 的状态是 follower,也就是从节点,Server3 的状态是 leader,也就是主节点。这样我们 Zookeeper 一主多从的集群环境就部署好了。接下来我们使用 Zookeeper 客户端进行测试。
3. Zookeeper 集群的同步
在 Zookeeper 集群服务中,每个 Follower 节点都可以对外提供服务,那么我们操作其中一个 Follower 节点时,如何确保我们获取的数据与其它 Follower 节点的数据是一样的呢?在接下来的测试中,我们来观察 Follower 节点的数据。
我们首先对其中一个 Server 进行操作,使用 zkCli.sh 连接 Server1 的 Zookeeper 服务,查看 Znode 节点:
# 进入 bin 文件夹
cd /usr/local/zookeeper/apache-zookeeper-3.6.1-bin/bin/
# 连接命令
./zkCli.sh
# 查看根节点下的子节点
ls /
# 只有默认的 zookeeper 节点
[zookeeper]
此时我们使用 create 命令对 Server1 的节点进行增加操作:
# 创建根节点的子节点 imooc
create /imooc
# 输出 imooc 创建成功
Created /imooc
创建成功之后我们再来查看一下 Server1 根节点的子节点:
# 查看根节点下的子节点
ls /
# 根节点下的子节点,新增了 imooc 节点
[imooc, zookeeper]
对 Server1 的 Znode 操作成功之后,接下来我们来查看一下 Server2 和 Server3 的 Zookeeper 节点信息:
# 进入 bin 文件夹
cd /usr/local/zookeeper/apache-zookeeper-3.6.1-bin/bin/
# 连接命令
./zkCli.sh
# 查看根节点下的子节点
ls /
# 新增加的 imooc 节点和默认的 zookeeper 节点
[imooc, zookeeper]
我们发现,Server2 和 Server3 的 Zookeeper 服务的根节点也有 Server1 中新增的 imooc 节点,为什么 Server1 增加的节点,另外两个服务也会出现呢?
这个问题其实就是 Zookeeper 集群的同步机制。当其中一个节点的信息被修改时,首先会修改 Leader 节点,然后再将数据同步到集群中所有的 Follower 节点,这样就确保了集群中所有节点的数据一致。
4. Zookeeper 集群的启动流程
Zookeeper 集群启动时,首先会通过配置文件判断 Zookeeper 的启动方式是否为集群模式,如果为集群模式,则通过配置文件进行初始化工作,然后集群的节点进行 Leader 选举,选举完毕后, Follower 节点与 Leader 节点进行数据同步,完成同步后就可以启动 Leader 和 Follower 实例了。
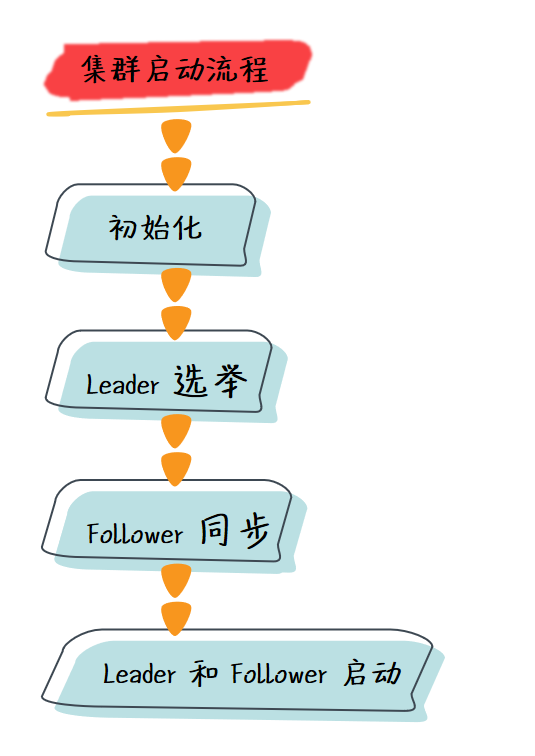
4.1 初始化
首先在集群启动的过程中,每个 Zookeeper 服务的主函数会都通过 zoo.cfg 配置文件来判定这个 Zookeeper 服务是以哪种模式启动的,然后通过配置文件进行初始化工作。
与单机模式初始化不同的是,集群模式的 Zookeeper 服务在初始化过程中还需要配置服务器列表、Leader 选举算法、会话超时时间等参数。
4.2 Leader 选举
在所有 Zookeeper 服务初始化完成后,第一件事情就是创建 Java 类 QuorumCnxManager 来进行 Zookeeper 集群的 Leader 选举。
在选举过程中,每个 Zookeeper 服务会使用自身的服务器编号 SID 、最新的事务编号 ZXID 、和当前服务器纪元值 currentEpoch 这三个参数去参加选举,然后根据 zoo.cfg 的 electionAlg 参数来选择 Leader 选举算法,来完成 Leader 的选举,完成选举后 Leader 会向其它 Zookeeper 服务发起数据同步的通知。
4.3 Follower 同步
Leader 选举完毕,其它 Zookeeper 服务的状态就会变为 Follower ,在 Follower 接收到来自 Leader 的通知后, Follower 会创建一个 LearnerHandler 类的实例来处理与 Leader 的数据同步,在半数以上的 Follower 完成数据同步后,Leader 和 Follower 的实例就可以启动了。
4.4 Leader 和 Follower 启动
在 Leader 和 Follower 实例启动时,创建和启动会话管理器,初始化 Zookeeper 的请求处理链,处理器也会在启动阶段串联请求处理链,然后把 Zookeeper 实例注册到 JMX 服务中,整个 Zookeeper 集群的启动才算完成。
5. 总结
本节我们学习了如何部署 Zookeeper 集群,Zookeeper 集群的同步机制,以及 Zookeeper 集群的启动流程。以下是本节内容的总结:
- Zookeeper 集群模式的部署。
- Zookeeper 集群模式的同步机制。
- Zookeeper 集群模式的启动流程。