Pandas 重复值的处理
1. 前言
上一小节我们学习了 Pandas 库中对于缺失值 NaN 的检测、过滤和填充操作,对于数据完整性的提升有着十分重要的意义,除了缺失数据的存在,源数据经常还会存在重复性数据,尤其是在数据量越大的情况下,重复的概率也越大,数据中存在重复值,是常见的现象,这些数据只是根据我们的分析需要不同,而产生的价值不同,有时我们希望排除这些数据进行分析,而有时我们又需要对这部分数据进行单独的分析,那对于重复数据的不同分析需要,Pandas 库又提供了怎样的操作呢?
本小节我们将学习 Pandas 库对于重复数据的查找操作和重复数据的删除操作,为数据的进一步分析打下基础。
2. 重复值的查找
在讲解程序操作之前,我们先处理一下数据源,修改一部分重复数据出来,为下面的操作做准备:

2.1 duplicated () 函数
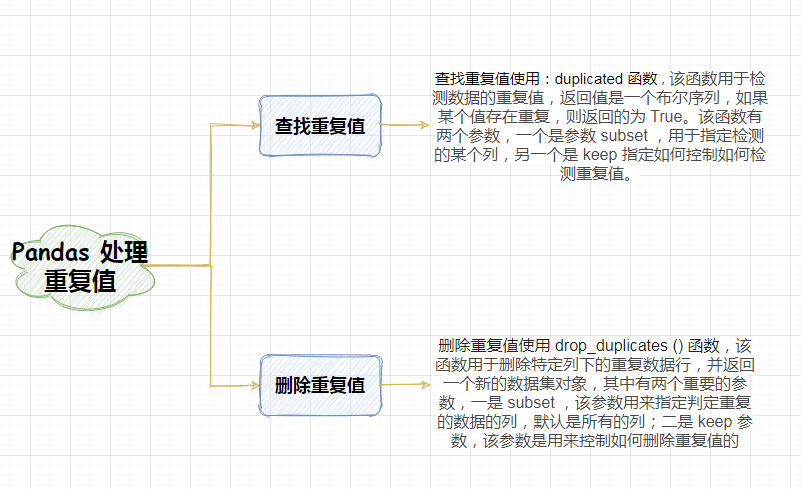
该函数用于检测数据的重复值,返回值是一个布尔序列,如果某个值存在重复,则返回的为 True。该函数有两个参数,一个是参数 subset ,用于指定检测的某个列,另一个是 keep 指定如何控制如何检测重复值,有三个值可选择:
- first:表示将第一次出现重复的值视为唯一的,后面重复的值标记为 True ,默认是这种方式;
- last:表示将最后一次出现重复的值视为唯一的,前面的重复值标记为 True ;
- False:表示将所有的重复项都标记为 True ;
下面我们通过实际代码操作来演示重复数据的检测操作:
# 导入pandas包
import pandas as pd
data_path="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data\_source/第12小节/execl数据demo.xlsx"
# 解析数据
data = pd.read_excel(data_path)
print(data)
# --- 输出结果 ---
编程语言 推出时间 价格 主要创始人
0 java 1983年 45.6 James Gosling
1 python 1991年 67.0 Bjarne Stroustrup
2 python 1972年 45.6 Dennis MacAlistair Ritchie
3 js 1983年 45.6 js
4 James Gosling 2012年 45.6 Rasmus Lerdorf
5 C++ java 75.0 Bjarne Stroustrup
# duplicated() 重复数据的判断
new_data= data.duplicated()
print(new_data)
# --- 输出结果 ---
0 False
1 False
2 False
3 False
4 False
5 False
dtype: bool
# 结果解析:这里的 duplicated() 函数我们什么参数也没设置,所有默认会以正行值作为判断,也就是判断是否有重复行的数据内容。
# duplicated() 设置 subset
new_data= data.duplicated(subset="价格")
print(new_data)
# --- 输出结果 ---
0 False
1 False
2 True
3 True
4 True
5 False
dtype: bool
# 结果解析:这里程序设置 subset="价格",则只对标签为"价格"的列进行重复数据的检测,可以看到结果中重复数据值除了第一个重复值被视为唯一的,后面出现的重复值检测结果均被设置为了 True,因为 keep 参数如果不设置,默认是 first 方式检测。
# duplicated() 设置 keep 为 last
new_data= data.duplicated(subset="价格",keep="last")
print(new_data)
# --- 输出结果 ---
0 True
1 False
2 True
3 True
4 False
5 False
dtype: bool
# 结果解析:这里指定 keep="last" ,表示最后一次出现的重复值视为唯一的,之前出现的重复值被检查为重复,结果为 True 。
# duplicated() 设置 keep 为 False
new_data= data.duplicated(subset="价格",keep=False)
print(new_data)
# --- 输出结果 ---
0 True
1 False
2 True
3 True
4 True
5 False
dtype: bool
# 结果解析:这里通过设置 keep=False ,将检测出的所有重复值均表示为 True 。
3. 重复值的删除
3.1 drop_duplicates () 函数
该函数用于删除特定列下的重复数据行,并返回一个新的数据集对象,其中有两个重要的参数,一是 subset ,该参数用来指定判定重复的数据的列,默认是所有的列;二是 keep 参数,该参数是用来控制如何删除重复值的,有三个参数值选项:
- first:表示将第一次出现的重复值视为唯一的,删除后面出现重复值的数据行 ,默认是这种方式;
- last:表示将最后一次出现重复的值视为唯一的,删除前面出现重复值的数据行 ;
- False:表示将删除重复值所在的所有数据行 ;
下面我们通过实际代码操作来演示重复数据的删除操作:
# 导入pandas包
import pandas as pd
data_path="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data\_source/第12小节/execl数据demo.xlsx"
# 解析数据
data = pd.read_excel(data_path)
print(data)
# --- 输出结果 ---
编程语言 推出时间 价格 主要创始人
0 java 1983年 45.6 James Gosling
1 python 1991年 67.0 Bjarne Stroustrup
2 python 1972年 45.6 Dennis MacAlistair Ritchie
3 js 1983年 45.6 js
4 James Gosling 2012年 45.6 Rasmus Lerdorf
5 C++ java 75.0 Bjarne Stroustrup
# drop\_duplicates()
data_res=data.drop_duplicates()
print(data_res)
# --- 输出结果 ---
编程语言 推出时间 价格 主要创始人
0 java 1983年 45.6 James Gosling
1 python 1991年 67.0 Bjarne Stroustrup
2 python 1972年 45.6 Dennis MacAlistair Ritchie
3 js 1983年 45.6 js
4 James Gosling 2012年 45.6 Rasmus Lerdorf
5 C++ java 75.0 Bjarne Stroustrup
# 结果解析:这里我们直接使用了 drop\_duplicates() 函数,但是没有传入任何的参数,默认则是以整行进行判断是否存在重复行,要是存在则进行删除操作。这里因为没有重复行,因此返回的数据集和原数据集内容一样。
# 设置 subset="编程语言"
data_res=data.drop_duplicates(subset="编程语言")
print(data_res)
# --- 输出结果 ---
编程语言 推出时间 价格 主要创始人
0 java 1983年 45.6 James Gosling
1 python 1991年 67.0 Bjarne Stroustrup
3 js 1983年 45.6 js
4 James Gosling 2012年 45.6 Rasmus Lerdorf
5 C++ java 75.0 Bjarne Stroustrup
# 结果解析:这里设置了 subset="编程语言" ,以编程语言列为标准查找重复值,默认 keep="first" 表示第一次的重复值视为唯一的不进行删除,通过输出结果可以看到,第3行的数据被删除了。
# 设置 keep="last"
data_res=data.drop_duplicates(subset="编程语言",keep="last")
print(data_res)
# --- 输出结果 ---
编程语言 推出时间 价格 主要创始人
0 java 1983年 45.6 James Gosling
2 python 1972年 45.6 Dennis MacAlistair Ritchie
3 js 1983年 45.6 js
4 James Gosling 2012年 45.6 Rasmus Lerdorf
5 C++ java 75.0 Bjarne Stroustrup
# 结果解析:这里设置了 keep="last" 表示将最后一个出现的重复值视为唯一的,因此这里删除了第2行的数据。
# 设置 keep=False
data_res=data.drop_duplicates(subset="编程语言",keep=False)
print(data_res)
# --- 输出结果 ---
编程语言 推出时间 价格 主要创始人
0 java 1983年 45.6 James Gosling
3 js 1983年 45.6 js
4 James Gosling 2012年 45.6 Rasmus Lerdorf
5 C++ java 75.0 Bjarne Stroustrup
# 结果解析:通过设置 keep=False 可以看到所有重复值所在的行都被删除了。
3. 小结
本节课程我们主要学习了 Pandas 库对于重复数据的处理,包括查询重复数据值,以及对出现重复的数据进行删除操作,根据我们实际的应用需要,我们可以方便的去处理重复数据,从而进一步的对数据开展分析工作。本节课程的重点如下:
- 使用 duplicated () 函数去检测重复数据值的操作以及其中参数的设置;
- 使用 drop_duplicates () 函数去删除重复的数据值。