Pandas 数据结构 Series
1. 前言
通过上几小节的学习,我们已经能够将外部数据用 Pandas 库进行解析,通过实际代码操作可以看出,不同的数据文件解析的函数不同,不同的数据内容,解析出来数据结构也不一样。了解一组数据的结构类型,对于我们分析数据有着至关重要的作用,那 Pandas 中的数据结构究竟有哪几种呢?
Pandas 中有两种主要的数据结构 Series 和 DataFrame,正是这两种数据结构,是 Pandas 为应用提供一种可靠性、易于使用的基础。本节课我们将先从 Series 数据结构进行入手,讲解 Series 数据结构的特点,以及掌握该数据结构常用的属性和方法。
2. Series 数据结构概述
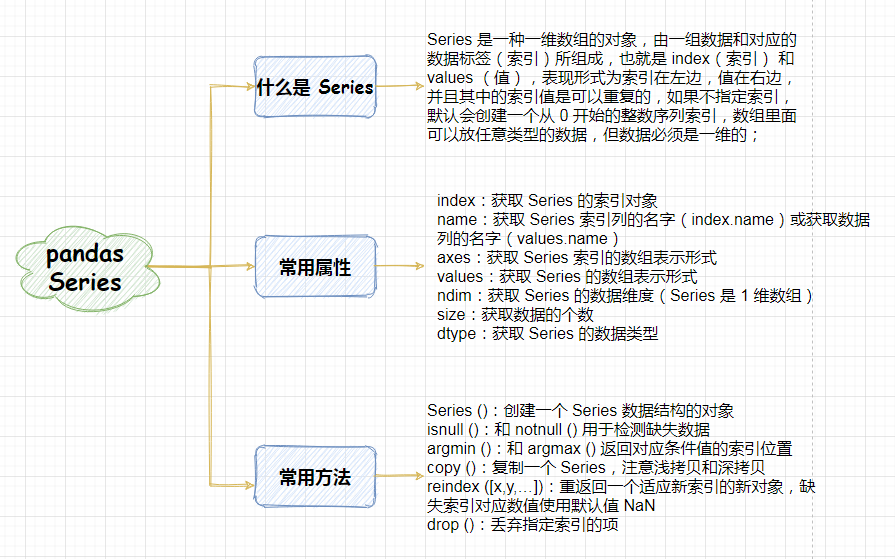
Series 是一种一维数组的对象,由一组数据和对应的数据标签(索引)所组成,也就是 index(索引) 和 values (值),表现形式为索引在左边,值在右边,并且其中的索引值是可以重复的,如果不指定索引,默认会创建一个从 0 开始的整数序列索引,数组里面可以放任意类型的数据,但数据必须是一维的;

3. Series 数据结构常用的属性
3.1 Series 常用的属性
Series 作为一维数组结构,它的对象中提供了一些常用的属性,来获取对象的信息,下面我们列举了一些常用的属性。
| 常用属性 | 属性描述 |
|---|---|
| index | 获取 Series 的索引对象 |
| name | 获取 Series 索引列的名字(index.name)或获取数据列的名字(values.name) |
| axes | 获取 Series 索引的数组表示形式 |
| values | 获取 Series 的数组表示形式 |
| ndim | 获取 Series 的数据维度(Series是1维数组) |
| size | 获取数据的个数 |
| dtype | 获取 Series 的数据类型 |
现在我们通过代码程序,具体演示上面的属性操作。
**实例:**我们通过定义一个 Series,然后分别演示上面的属性操作。
# 引入pandas
import pandas as pd
# 定义一个series对象
obj=pd.Series([12,"welcom",23, "to",34, "pandas",45])
print(obj)
# --- 输出结果 ---
0 12
1 welcom
2 23
3 to
4 34
5 pandas
6 45
具体的属性操作:
# index 属性
print(obj.index)
#--- 输出结果 ---
RangeIndex(start=0, stop=7, step=1) #索引对象的的开始下标,最后下标,步长
# values 属性
print(obj.values)
#--- 输出结果 ---
[12 'welcom' 23 'to' 34 'pandas' 45] #Series的数组表示的值
# name 属性
print(obj.index.name)
#--- 输出结果 ---
None #None是索引列和数据类默认的名称,可以通过 obj.index.name="索引" 重新命名
# axes 属性
print(obj.axes)
#--- 输出结果 ---
[RangeIndex(start=0, stop=7, step=1)] #下标从0到7,步长为1,长度为8的数组
# ndim 属性
print(obj.ndim)
#--- 输出结果 ---
1 #验证了Series是一维数组
# size 属性
print(obj.size)
#--- 输出结果 ---
7 #有7个数据
# dtype 属性
print(obj.dtype)
#--- 输出结果 ---
object #是一个object的数据类型,这里要区分一下数据类型和数据结构,我们说Series是Pandas的数据结构之一,并不是数据类型就是Series。
3.2 Series 常用的方法
另外 Series 中还提供了丰富的函数,方便我们来进行操作,下面我们列举了几个常用的操作方法。
| 常用函数 | 函数描述 |
|---|---|
| Series() | 创建一个 Series 数据结构的对象 |
| isnull()和notnull() | 用于检测缺失数据 |
| argmin()和argmax() | 返回对应条件值的索引位置 |
| copy() | 复制一个 Series,注意浅拷贝和深拷贝 |
| reindex([x,y,…]) | 重返回一个适应新索引的新对象,缺失索引对应数值使用默认值 NaN |
| drop() | 丢弃指定索引的项 |
下面我们分别看一下每个方法的具体操作实例:
Series() 方法
该方法用于创建一个一维数组的对象,通过该方法有多种方式去创建 Series 对象:方式一:Series([x,y,…])、方式二:Series([x,y,…], index=[param1,param1,…])、方式三:Series({“a”:x,“b”:y,…})
# 引入pandas
import pandas as pd
# 形式一:Series([x,y,...])
obj=pd.Series([12,23,34,45])
print(obj)
#--- 输出结果 ---
0 12
1 23
2 34
3 45
dtype: int64
# 形式二:Series([x,y,...], index=[param1,param1,...])
obj=pd.Series([12,23,34,45],index=["a","b","c","d"])
print(obj)
#--- 输出结果 ---
# 该形式,我们可以指定它的索引列的值
a 12
b 23
c 34
d 45
dtype: int64
# 形式三:Series({"a":x,"b":y,...})
obj2=pd.Series({"a":12,"b":33,"c":5,"d":22})
print(obj2)
#--- 输出结果 ---
# 这里我们里面传入的是一个字典,他的key就会对应成索引列,value对应数据列
a 12
b 33
c 5
d 22
dtype: int64
isnull() 和 notnull() 方法
isnull() 是缺失值返回 Ture 运行结果,而 notnull() 则不是缺失值的返回 Ture 运行结果
# 引入pandas
import pandas as pd
obj=pd.Series([12,23,34,45],index=["a","b","c","d"])
print(obj.isnull())
#--- 输出结果 ---
a False
b False
c False
d False
dtype: bool
print(obj.notnull())
#--- 输出结果 ---
a True
b True
c True
d True
dtype: bool
argmin() 和 argmax() 方法
argmin() 用于返回最小值索引的位置,argmax() 用于返回最大值索引的位置
# 引入pandas
import pandas as pd
obj2=pd.Series({"a":12,"b":33,"c":5,"d":22})
print(obj2.argmin())
# --- 输出结果 ---
2 #最小值的索引为2,因为索引是从0开始的,我们最小值为5,
print(obj2.argmax())
# --- 输出结果 ---
1 #最小值的索引为1,最大值是33,
copy( ) 方法
该方法为拷贝一个 Series,但要注意里面的 deep 设置,也就是深拷贝 copy(deep=True) 和浅拷贝copy(deep=False) 的问题。浅拷贝:拷贝父对象,不会拷贝对象的内部的子对象,只复制对象本身,没有复制该对象所引用的对象;深拷贝:完全拷贝了父对象及其子对象,新的组合对象与原对象没有任何关联。
# 引入pandas
import pandas as pd
obj2=pd.Series({"a":12,"b":33,"c":5,"d":22})
# 1.cpys 浅拷贝
cpys = obj2.copy(deep=False)
cpys['a']=0
print(cpys)
print(obj2)
# --- 输出结果 ---
# 这是浅拷贝之后的cpys
a 0
b 33
c 5
d 22
dtype: int64
# 这是被拷贝的 obj2
a 0
b 33
c 5
d 22
dtype: int64
# 通过上面的输出结果,我们可以看到,我们对拷贝后的对象进行修改,也会影响到被浅拷贝的对象,进而证明了,浅拷贝只复制对象本身,没有复制该对象所引用的对象
# 2.cpys\_deep深拷贝
cpys_deep = obj2.copy(deep=True)
cpys_deep['a']=0
print(cpys_deep)
print(obj2)
# --- 输出结果 ---
# 这是深拷贝之后的cpys\_deep
a 0
b 33
c 5
d 22
dtype: int64
# 这是被拷贝的 obj2
a 12
b 33
c 5
d 22
dtype: int64
# 我们通过输出结果,可以看到 索引a,obj和cps\_deep的值是不一样的,我们修改拷贝后的对象,并不能影响到被拷贝的对象,这就是深拷贝,它完全拷贝了父对象及其子对象,和之前的对象是相互独立的。
reindex([x,y,…]) 方法
该方法会将源 Series 对象,按照新的索引顺序生成新的 Series 对象,默认如果没有对应索引的则使用默认值NaN。( NaN 即"⾮数字" (not a number),在 Pandas 中,它⽤于表示缺失或NA值 )
# 引入pandas
import pandas as pd
obj=pd.Series([12,23,6,145,44],index=["a","b","c","d","e"])
rs_obj=obj.reindex(["e","d","c","b","a","f","g"])
print(rs_obj)
#--- 输出结果 ---
e 44.0
d 145.0
c 6.0
b 23.0
a 12.0
f NaN
g NaN
dtype: float64
# 这里我们看到按照我们写的索引的顺序,生成了一个新的对象rs\_obj,没有值的默认为NaN进行填充。
drop( ) 方法
该方法通过传入指定的索引,丢弃对应的数据项,返回一个新的 Series 对象。
# 引入pandas
import pandas as pd
obj=pd.Series([12,23,6,145,44],index=["a","b","c","d","e"])
drop_obj=obj.drop(["e","d"])
print(obj)
print(drop_obj)
#--- 输出结果 ---
# 源对象
a 12
b 23
c 6
d 145
e 44
dtype: int64
# drop操作后新的对象 drop\_obj
a 12
b 23
c 6
dtype: int64
4. 小结
通过本小节内容的学习,我们了解到 Pandas 库主要包含了两种数据结构,该节内容主要讲述了 Series 数据结构特点,以及我们如何操作该数据结构的常用方法,在实际运用当中,大家会接触到更多关于 Series 数据结构的使用方法和技巧。本节课程的重点如下:
- Series 数据结构的常用属性;
- Series 数据结构的常用操作方法;