Pandas 新增数据
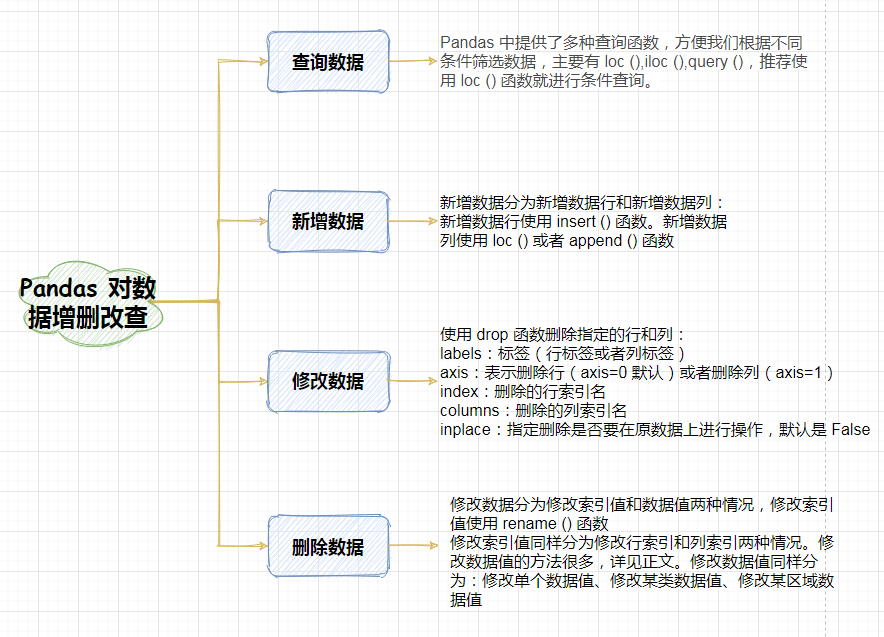
1. 前言
上一节我们讲述了 Pandas 查询数据的方法,以及查询条件的几种方式,能根据我们业务的需要,查询出我么需要的数据集。而有时候我们的数据集在数量上或者内容上不能够满足我们的分析需要,我们要对数据进行扩充,那在 Pandas 中我们该怎么操作呢?
Pandas 中为 DataFrame 提供了新增数据列和新增数据行的几种方式,本小节我们将分别讲述新增数据列和数据行的具体操作。
2. 新增数据列
2.1 直接新增数据列
直接新增数据列,需要传入新增的列索引名,以及该列每行的数据项值:
# 导入pandas包
import pandas as pd
# 指定导入的文件地址 默认是file,这里的路径中省略了 file:/
data_path="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data\_source/第7,8,9,10小节/execl数据demo.xlsx"
data = pd.read_excel(data_path)
print(data)
# --- 输出结果 ---
编程语言 推出时间 价格 主要创始人
0 java 1995年 45.6 James Gosling
1 python 1991年 67.0 Guido van Rossum
2 C 1972年 33.9 Dennis MacAlistair Ritchie
3 js 1995年 59.5 Brendan Eich
4 php 2012年 69.9 Rasmus Lerdorf
5 C++ 1983年 75.0 Bjarne Stroustrup
# 新增数据列操作
data["new\_colume"]=["a","b","c","d","e","f"]
print(data)
# --- 输出结果 ---
编程语言 推出时间 价格 主要创始人 new_colume
0 java 1995年 45.6 James Gosling a
1 python 1991年 67.0 Guido van Rossum b
2 C 1972年 33.9 Dennis MacAlistair Ritchie c
3 js 1995年 59.5 Brendan Eich d
4 php 2012年 69.9 Rasmus Lerdorf e
5 C++ 1983年 75.0 Bjarne Stroustrup f
输出解析:我们通过操作新增 new_colume 列,并指定行值分别为a,b,c,d,e,f,通过输出结果可以看到,在数据集的最后一列新增了数据列内容。
2.2 insert() 方法新增数据列
insert(loc, column, value, allow_duplicates=False) 函数可以实现向指定的列中添加数据:
| 参数名 | 说明 |
|---|---|
| loc | 指定插入列的序号,从0开始 |
| column | 列索引名 |
| value | 插入的列数据 |
| duplicates | 是否允许插入已有的数据,如果为 False 插入重复数据会报错 |
# 导入pandas包
import pandas as pd
# 指定导入的文件地址 默认是file,这里的路径中省略了 file:/
data_path="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data\_source/第7,8,9,10小节/execl数据demo.xlsx"
data = pd.read_excel(data_path)
print(data)
# --- 输出结果 ---
编程语言 推出时间 价格 主要创始人
0 java 1995年 45.6 James Gosling
1 python 1991年 67.0 Guido van Rossum
2 C 1972年 33.9 Dennis MacAlistair Ritchie
3 js 1995年 59.5 Brendan Eich
4 php 2012年 69.9 Rasmus Lerdorf
5 C++ 1983年 75.0 Bjarne Stroustrup
# 通过 insert() 函数,在第1列插入列索引为 new 的数据列
data.insert(0,"new",["a","b","c","d","e","f"], allow_duplicates=False)
print(data)
# --- 输出结果 ---
new 编程语言 推出时间 价格 主要创始人
0 a java 1995年 45.6 James Gosling
1 b python 1991年 67.0 Guido van Rossum
2 c C 1972年 33.9 Dennis MacAlistair Ritchie
3 d js 1995年 59.5 Brendan Eich
4 e php 2012年 69.9 Rasmus Lerdorf
5 f C++ 1983年 75.0 Bjarne Stroustrup
输出解析:通过 insert() 函数操作,我们看到输出结果在第一列新增了数据列内容。
3. 新增数据行
3.1 loc() 方法新增数据行
通过 loc() 函数指定要新增的行索引值,传入对应的列数据内容即可:
# 导入pandas包
import pandas as pd
# 指定导入的文件地址 默认是file,这里的路径中省略了 file:/
data_path="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data\_source/第7,8,9,10小节/execl数据demo.xlsx"
data = pd.read_excel(data_path)
print(data)
# --- 输出结果 ---
编程语言 推出时间 价格 主要创始人
0 java 1995年 45.6 James Gosling
1 python 1991年 67.0 Guido van Rossum
2 C 1972年 33.9 Dennis MacAlistair Ritchie
3 js 1995年 59.5 Brendan Eich
4 php 2012年 69.9 Rasmus Lerdorf
5 C++ 1983年 75.0 Bjarne Stroustrup
# 通过 loc() 传入插入的行索引为 6 ,右侧为插入的列数据内容
data.loc[6]=["ss","dd","23.1","ff"]
print(data)
# --- 输出结果 ---
编程语言 推出时间 价格 主要创始人
0 java 1995年 45.6 James Gosling
1 python 1991年 67 Guido van Rossum
2 C 1972年 33.9 Dennis MacAlistair Ritchie
3 js 1995年 59.5 Brendan Eich
4 php 2012年 69.9 Rasmus Lerdorf
5 C++ 1983年 75 Bjarne Stroustrup
6 ss dd 23.1 ff
输出解析:这里可以看到在原数据的基础上新增了行索引为 6 的数据行。但这里要注意,如果行索引指定的是已存在行索引,则不会进行数据行的插入,而是替换了该数据行的数据值,如下程序演示:
# 这里我们指定行索引为 5 的值
data.loc[5]=["ss","dd","23.1","ff"]
print(data)
# --- 输出结果 ---
编程语言 推出时间 价格 主要创始人
0 java 1995年 45.6 James Gosling
1 python 1991年 67 Guido van Rossum
2 C 1972年 33.9 Dennis MacAlistair Ritchie
3 js 1995年 59.5 Brendan Eich
4 php 2012年 69.9 Rasmus Lerdorf
5 ss dd 23.1 ff
输出解析:通过结果可以看到,行索引为5的原数据为: C++ ,1983年,75,Bjarne Stroustrup,通过操作并没有新增数据行,而是将该行的数据改为了:ss,dd,23.1, ff
3.2 append() 方法新增数据行
append(other, ignore_index=False, verify_integrity=False) 是用来在数据表尾新增数据行,并返回新增后的数据对象,该方法不仅仅适用于 DataFrame 结构的数据,还可以用于 Series 数据的追加。
| 参数名 | 说明 |
|---|---|
| other | 要添加的数据,可以是 Series、list、dict、dataframe 等等; |
| ignore_index | 新增了数据后,会重新设置索引,忽略旧的索引; |
| verify_integrity | 当为 True 时,如果和原数据的索引值相同,将会报错; |
# 新建一个 DataFrame 对象
data_new= pd.DataFrame([["11","22","33.5","44"], ["55","66","77.7","88"]],
columns=["编程语言","推出时间","价格","主要创始人"])
# 对 data 使用 append 操作,传入新创建的 DataFrame 对象
result_data=data.append(data_new)
print(result_data)
# --- 输出结果 ---
编程语言 推出时间 价格 主要创始人
0 java 1995年 45.6 James Gosling
1 python 1991年 67 Guido van Rossum
2 C 1972年 33.9 Dennis MacAlistair Ritchie
3 js 1995年 59.5 Brendan Eich
4 php 2012年 69.9 Rasmus Lerdorf
5 C++ 1983年 75 Bjarne Stroustrup
0 11 22 33.5 44
1 55 66 77.7 88
输出解析:这里可以看到通过 append() 操作是将两个数据集进行行的合并,在 data 数据集的基础上,后面合并 data_new 数据行。这里的索引并不会产生冲突,因为我们没有设置 verify_integrity=True(默认的是为 False),如果我们设置了 ignore_index= True ,合并后生成的新的数据集索引值会重新排列,如下操作所示:
data_new= pd.DataFrame([["11","22","33.5","44"], ["55","66","77.7","88"]],
columns=["编程语言","推出时间","价格","主要创始人"])
result_data=data.append(data_new, ignore_index= True)
print(result_data)
# --- 输出结果 ---
编程语言 推出时间 价格 主要创始人
0 java 1995年 45.6 James Gosling
1 python 1991年 67 Guido van Rossum
2 C 1972年 33.9 Dennis MacAlistair Ritchie
3 js 1995年 59.5 Brendan Eich
4 php 2012年 69.9 Rasmus Lerdorf
5 C++ 1983年 75 Bjarne Stroustrup
6 11 22 33.5 44
7 55 66 77.7 88
输出解析:这里可以看到通过设置 ignore_index= True 属性,返回的数据对象的行索引从0开始重新进行了排列。
3.小结
本节课我们主要学习了新增数据行和数据列的几种方式,以及新增操作过程中需要注意的地方。本节课程的重点如下:
- 直接新增数据列的操作方法;
- insert() 方法新增数据列的操作以及与直接新增方式的不同;
- loc() 新增数据行的操作;
- append() 新增数据行的操纵以及与 loc() 操作之间的不同。