Pandas 排序和排名操作
1. 前言
上一小节,我们学习了 Pandas 库对于多个数据集的连接和合并操作,满足了我们在数据行和列上的内容扩展需要,除了这点,我们很多时候也需要对某个数据集中的数据进行排序操作,按照递增或者递减的方式将数据依据某个条件进行排序,Pandas 库针对这样一个较为常见的数据处理需求,又提供了怎样的操作方式呢?
本节我们将一起学习 Pandas 库中对于数据的排序操作,分为按索引排序和按数据值进行排序,除了排序功能,Pandas 还提供了排名的操作,接下来我们一起学习 Pandas 库的排序和排名操作吧。
2. Pandas 排序操作
Pandas 对于排序的操作分为按索引排序和按数据值排序,分别通过函数 sort_index () 和 sort_values () 进行实现,接下来我们详细学习每个函数的使用方式。首先我们通过 Excel 进行数据的解析。
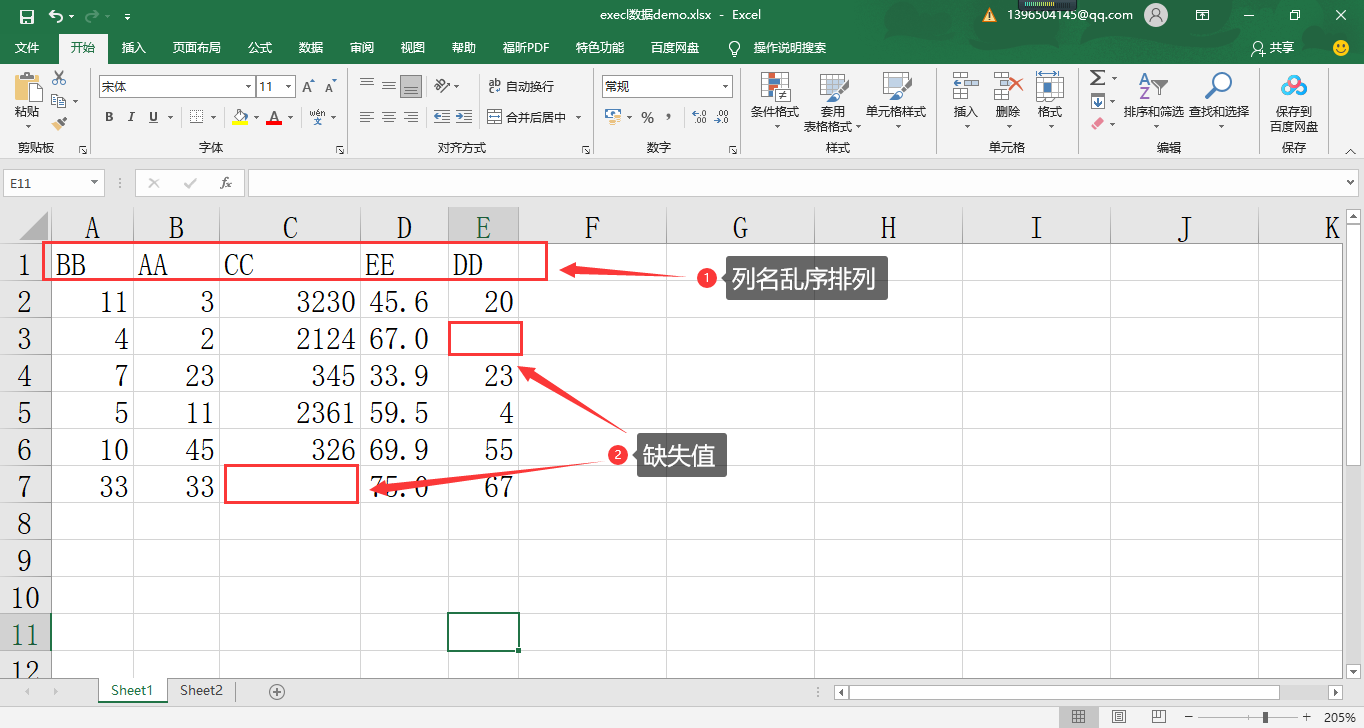
Pandas 解析的数据对象 data 具体内容如下:
# 导入pandas包
import pandas as pd
data_path="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data\_source/第15小节/execl数据demo.xlsx"
# 解析数据
data = pd.read_excel(data_path)
print(data)
# --- 输出结果 data 数据对象 ---
BB AA CC EE DD
0 11 3 3230.0 45.6 20.0
1 4 2 2124.0 67.0 NaN
2 7 23 345.0 33.9 23.0
3 5 11 2361.0 59.5 4.0
4 10 45 326.0 69.9 55.0
5 33 33 NaN 75.0 67.0
2.1 sort_index () 函数
该函数是对数据集进行按索引进行排序时使用的,里面提供了丰富的函数,下面我将列举几个常用的参数。
df.sort_index(axis=0, level=None, ascending=True, inplace=False, kind='quicksort', na_position='last', sort_remaining=True, ignore_index=False, key=None)
| 参数名 | 说明 |
|---|---|
| axis | 排序的索引轴,axis=0 行索引(默认),axis=1 列索引 |
| ascending | ascending=True 升序或是 ascending=False 降序排序 |
下面我们将通过上面从 Excel 解析的数据集 data 进行该函数这个参数的代码演示:
# data 为上面从 Excel 中解析出来的数据
# 1.按行索引进行降序排列 axis=0,ascending=False
data_res=data.sort_index(axis=0,ascending=False)
print(data_res)
# --- 输出结果 ---
BB AA CC EE DD
5 33 33 NaN 75.0 67.0
4 10 45 326.0 69.9 55.0
3 5 11 2361.0 59.5 4.0
2 7 23 345.0 33.9 23.0
1 4 2 2124.0 67.0 NaN
0 11 3 3230.0 45.6 20.0
# 结果解析:通过对这两个参数的设置,我们按照行索引进行了降序排列。
# 2.按列索引进行降序排列 axis=1,ascending=False
data_res=data.sort_index(axis=1,ascending=False)
print(data_res)
# --- 输出结果 ---
EE DD CC BB AA
0 45.6 20.0 3230.0 11 3
1 67.0 NaN 2124.0 4 2
2 33.9 23.0 345.0 7 23
3 59.5 4.0 2361.0 5 11
4 69.9 55.0 326.0 10 45
5 75.0 67.0 NaN 33 33
# 结果解析:通过设置按照列索引,进行降序排列数据,可以看到输出结果。
# 3.按列索引进行降序排列 axis=1,ascending=True
data_res=data.sort_index(axis=1,ascending=True)
print(data_res)
# --- 输出结果 ---
AA BB CC DD EE
0 3 11 3230.0 20.0 45.6
1 2 4 2124.0 NaN 67.0
2 23 7 345.0 23.0 33.9
3 11 5 2361.0 4.0 59.5
4 45 10 326.0 55.0 69.9
5 33 33 NaN 67.0 75.0
# 结果解析:通过设置按照列索引进行升序排列数据,可以看到列数据的索引顺序变为了从 AA 到 EE 。
2.2 sort_values () 函数
该函数是专门用于数据集进行数据值的排序使用,下面同样我列举了他常用的一些参数设置。
pd.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_index=False, key=None)
| 参数名 | 说明 |
|---|---|
| by | 指定需要排序的列或者行 |
| axis | 指定需要排序的是列还是行,默认 axis=0 表示行 |
| ascending | 设置升序还是降序,默认是 ascending=True 为升序 |
| na_position | 设置缺失值显示的位置,有 first 和 last 两个值,默认是 last |
下面我们利用前面解析出来 data 数据集,进行各参数详细的设置使用。
# data 为上面从 Excel 中解析出来的数据
# 1.按 AA 列进行 行数据的 升序 排序
data_res=data.sort_values(by=["AA"],ascending=True,axis=0)
print(data_res)
# --- 输出结果 ---
BB AA CC EE DD
1 4 2 2124.0 67.0 NaN
0 11 3 3230.0 45.6 20.0
3 5 11 2361.0 59.5 4.0
2 7 23 345.0 33.9 23.0
5 33 33 NaN 75.0 67.0
4 10 45 326.0 69.9 55.0
# 结果解析:我们这里通过 by 参数设置了是以 AA 列为标准,进行 axis=0 行数据的 ascending=True 升序排序,可以看到 AA 列数据分别为 2,3,11,23,33,45,以此为标准进行了行数据的排序。
# 2.按 DD 列进行 行数据的 降序 排序
data_res=data.sort_values(by=["DD"],ascending=False,axis=0)
print(data_res)
# --- 输出结果 ---
BB AA CC EE DD
5 33 33 NaN 75.0 67.0
4 10 45 326.0 69.9 55.0
2 7 23 345.0 33.9 23.0
0 11 3 3230.0 45.6 20.0
3 5 11 2361.0 59.5 4.0
1 4 2 2124.0 67.0 NaN
# 结果解析:我们这里以 EE 列为标准,进行行数据的降序排序,可以看到数据的排序结果,这里要注意一点就是 DD 列数据存在缺失值 NaN ,默认的参数 na\_position='last' 表示将缺失值放在最后。
# 3.na\_position='first' 参数 ,按 DD 列进行 行数据的 降序 排序
data_res=data.sort_values(by=["DD"],ascending=False,axis=0,na_position='first')
print(data_res)
# --- 输出结果 ---
BB AA CC EE DD
1 4 2 2124.0 67.0 NaN
5 33 33 NaN 75.0 67.0
4 10 45 326.0 69.9 55.0
2 7 23 345.0 33.9 23.0
0 11 3 3230.0 45.6 20.0
3 5 11 2361.0 59.5 4.0
# 结果解析:这里依然是按 DD 列进行行排序,通过设置 na\_position='first' 缺失值放在了开始位置。
# 4.设置axis=1,以行为判断标准进行列排序
data_res=data.sort_values(by=[3],ascending=False,axis=1)
print(data_res)
# --- 输出结果 ---
CC EE AA BB DD
0 3230.0 45.6 3 11 20.0
1 2124.0 67.0 2 4 NaN
2 345.0 33.9 23 7 23.0
3 2361.0 59.5 11 5 4.0
4 326.0 69.9 45 10 55.0
5 NaN 75.0 33 33 67.0
# 结果解析:这里我们设置 axis=1 表示对列进行排序,ascending=False 进行降序排序,通过设置 by=[3],这里表明以第四行为排序依据对列进行降序排序。
3. Pandas 排名操作
排名操作是根据数据的大小,判断出该数据在数据集中的名次,默认是从 1 开始一直到数据中有效数据的长度,如果存在重复数据,则会求出这几个数据的平均排名。Pandas 库中针对排名操作提供了方便的操作函数 rank () .
df.rank(axis=0, method='average', numeric_only=None, na_option='keep', ascending=True, pct=False)
接下来我们列举该函数常用的一些参数:
| 参数名 | 说明 |
|---|---|
| axis | 指定是在行上,还是列上进行排名。默认是 axis=0 从列上进行排名 |
| method | 平级排名的取值方法,有四种方式。 |
method 用于平级数据,也就是要排名的数据中,他们的大小是一样的,这种平级的数据有四种排名的方式:
- average:在一组相等的排名数据中,为每个数据取他们的平均排名;
- min:在一组相等的排名数据中,使用最小的排名给每个数据;
- max:在一组相等的排名数据中,使用最大的排名给每个数据;
- first:在一组相等的排名数据中,按各个值在原始数据中的出现顺序进行排名。
下面我们通过程序代码详细讲解排名函数的用法:
# 导入pandas包
import pandas as pd
data_path="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data\_source/第15小节/execl数据demo.xlsx"
# 解析数据
data = pd.read_excel(data_path)
print(data)
# --- 输出结果 ---
BB AA CC EE DD
0 11 3 3230.0 45.6 20.0
1 4 2 2124.0 67.0 NaN
2 7 23 345.0 33.9 23.0
3 5 11 2361.0 59.5 4.0
4 10 45 326.0 69.9 55.0
5 33 33 NaN 75.0 67.0
# rank() 函数
# 1. 默认的 axis=0,在列上进行排序
data_res=data.rank()
print(data_res)
# --- 输出结果 ---
BB AA CC EE DD
0 5.0 2.0 5.0 2.0 2.0
1 1.0 1.0 3.0 4.0 NaN
2 3.0 4.0 2.0 1.0 3.0
3 2.0 3.0 4.0 3.0 1.0
4 4.0 6.0 1.0 5.0 4.0
5 6.0 5.0 NaN 6.0 5.0
# 结果解析: 通过 rank() 函数默认的在列方向进行排名的操作,比如"BB"列中,每一个数据在该列中的名次都得到了体现,但对于出现的缺失值 NaN 数据,是不进行排名计算的。
# 2. 设置的 axis=1,在行放方向上进行排序
data_res=data.rank(axis=1)
print(data_res)
# --- 输出结果 ---
BB AA CC EE DD
0 2.0 1.0 5.0 4.0 3.0
1 2.0 1.0 4.0 3.0 NaN
2 1.0 2.5 5.0 4.0 2.5
3 2.0 3.0 5.0 4.0 1.0
4 1.0 2.0 5.0 4.0 3.0
5 1.5 1.5 NaN 4.0 3.0
# 结果解析:这里我们设置了在行上进行排名的计算,这里看到最后一行,因为我们原数据该行的前两列数据时候相同的,都是 33,这里因为默认的 method=average,所有33取了他们平均排名 1+2 的平均值 1.5。 接下来我们设置 method=first ,看一下处理效果:
# 3. 设置 method=‘first’,修改默认的相同排名的处理方式
data_res=data.rank(axis=1,method='first')
print(data_res)
# --- 输出结果 ---
BB AA CC EE DD
0 2.0 1.0 5.0 4.0 3.0
1 2.0 1.0 4.0 3.0 NaN
2 1.0 2.0 5.0 4.0 3.0
3 2.0 3.0 5.0 4.0 1.0
4 1.0 2.0 5.0 4.0 3.0
5 1.0 2.0 NaN 4.0 3.0
# 结果解析:同样的我们还是看最后一行,因为我们设置了 method='first' ,所以对于相同排名的数据,会使用该数据在原数据中的出现顺序进行处理,所以第五行的前两列的数据排名分别为 1,2。
4. 小结
本节课程我们主要学习了 Pandas 对于数据的排序和排名操作,针对排序还具体分为了按索引进行排序和按数据值进行排序,主要涉及了 sort_index () 函数,sort_values () 函数和 rank () 函数的操作。本节课程的重点如下:
- 排序函数 sort_index () 和 sort_values () 的区别和使用;
- rank () 函数用于数据排名的具体操作方法。