Pandas 分组聚合操作
1. 前言
上一节我们学习了 Pandas 对数据的重塑操作,可以满足我们对数据集不同结构的分析需要,而有时候我们还需要对数据依据某个类别进行分组的需要,以及在分组后对每组数据进行分析的需要,那 Pandas 中的数据分组操作又是怎么实现的呢?
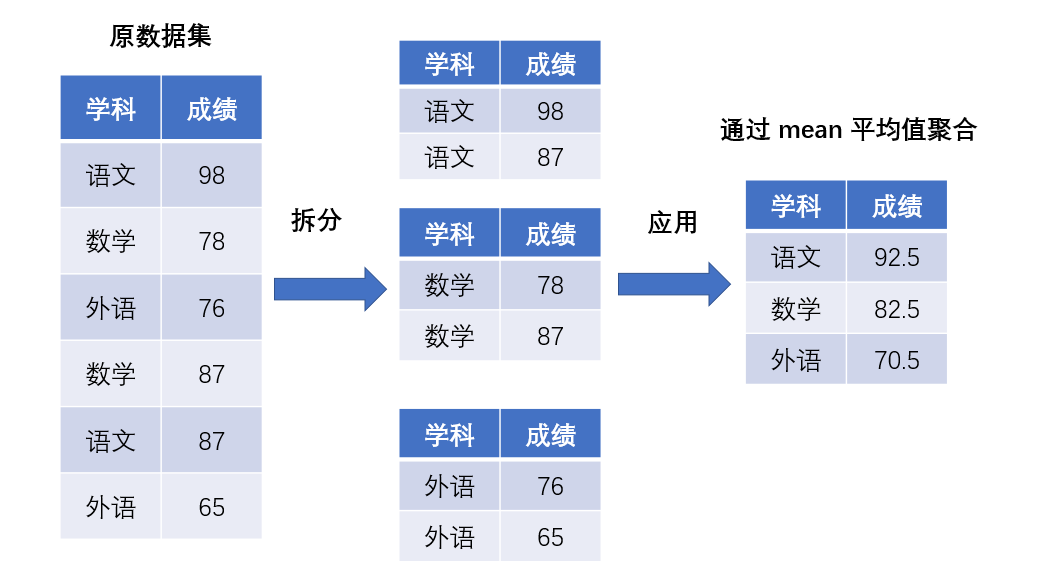
Pandas 库中提供了友好的数据分组聚合操作,分组聚合的过程包括数据的拆分、应用和聚合,如下图所示的过程。数据的分组操作主要涉及函数 groupby (),而聚合函数则有很多,在下面的学习中我们会列举一些聚合函数的具体使用方法。
2. 分组操作
Pandas 中的分组操作主要通过函数 groupby () 实现,该函数对数据进行分组,并不会产生运算,分组后会返回一个 groupby 对象,该对象并不能展示数据,要通过具体的操作函数才能看到数据结果。
首先我们通过 Pandas 解析 Excel 数据,得到 DataFrame 数据对象:
# 导入pandas包
import pandas as pd
data_path="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data\_source/第19小节/execl数据demo.xlsx"
# 解析数据
data = pd.read_excel(data_path)
print(data)
# --- 输出结果 ---
编程语言 技术方向 推出时间 年均销售数量 价格 主要创始人
0 java 后端 1995年 230 45.6 James Gosling
1 HTML 前端 1990年 124 55.3 Daniel W. Connolly
2 C 后端 1972年 35 33.9 Dennis MacAlistair Ritchie
3 js 前端 1995年 678 59.5 Brendan Eich
4 C++ 后端 1983年 125 75.0 Bjarne Stroustrup
5 CSS 前端 1990年 254 24.6 Tim Berners-Lee
接下来我们进行分组操作:
# data 为上面解析的数据对象
# 这里依据技术方向列进行分组
data.groupby('技术方向')
# --- 输出结果 ---
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x000001D618583070>
# 结果解析:这里我们使用的是单个索引‘技术方向’进行分组,也可以传入一个列表进行分组。这里可以看到输出的是一个 DataFrameGroupBy 对象
3. 聚合操作
聚合操作是分组的目的,通过聚合操作对各组数据进行聚合,得到一定的分析效果,Pandas 中提供了大量的聚合操作函数,我们下面列举了部分,用以展示数据分组后进行聚合操作的效果。
| 函数名 | 说明 |
|---|---|
| count | 各分组中非 NaN 值的数量 |
| sum | 各分组中非 NaN 值的和 |
| mean | 各分组中非 NaN 值的平均值 |
下面我们通过代码详细介绍聚合函数的使用:
- sum() 函数
该函数用于求各组数值数据的和,非数值数据不进行该聚合操作。
data.groupby(['技术方向','推出时间']).sum()
# --- 输出结果 ---
年均销售数量 价格
技术方向 推出时间
前端 1990年 378 79.9
1995年 678 59.5
后端 1972年 35 33.9
1983年 125 75.0
1995年 230 45.6
# 结果解析:这里我们指定分组索引依据为列表,传入‘技术方向’,‘推出时间’,则分组是先以技术方向分为“前端”和“后端”,再以推出时间进行分组,带分组之后,进行 sum() 各组求和的聚合运算,得到各组的年均销售数量和价格的数据结果。
在这里我们要补充一个下 groupby () 函数中的一个参数:as_index ,该参数默认为 True,是用来指定是否用分组索引作为聚合结果数据集的行索引,上面的代码中,默认 as_index=True ,因此行索引会有两层,分别为技术方向和推出时间,下面我们通过指定 as_index=False , 默认行索引会从 0 开始生成序列:
# data 为上面解析的数据对象
# 指定 as\_index=False
data.groupby(['技术方向','推出时间'],as_index=False).sum()
# --- 输出结果 ---
技术方向 推出时间 年均销售数量 价格
0 前端 1990年 378 79.9
1 前端 1995年 678 59.5
2 后端 1972年 35 33.9
3 后端 1983年 125 75.0
4 后端 1995年 230 45.6
# 结果解析:可以看到聚合后的数据集行索引为默认生成。
- count() 函数
该函数用于计算分组后各组数据的数量。
# data 为上面解析的数据对象
# count() 函数
data.groupby(['技术方向','推出时间'],as_index=False)['编程语言','年均销售数量','价格'].count()
# --- 输出结果 ---
技术方向 推出时间 编程语言 年均销售数量 价格
0 前端 1990年 2 2 2
1 前端 1995年 1 1 1
2 后端 1972年 1 1 1
3 后端 1983年 1 1 1
4 后端 1995年 1 1 1
结果解析:这里我们通过 count () 进行聚合,并指定只聚合 “编程语言”,“年均销售数量”,“价格” 列的数据数量。
- mean() 函数
该函数用于进行各分组数据的平均值的计算,该函数只对数值数据进行聚合。
# data 为上面解析的数据对象
# mean() 函数
data.groupby(['技术方向'],as_index=False).mean()
# --- 输出结果 ---
技术方向 年均销售数量 价格
0 前端 352 46.466667
1 后端 130 51.500000
结果解析:通过 groupby 指定以技术方向进行分组,分为前端和后端,然后进行平均值的聚合操作。
4. 小结
本节课程我们主要学习了 Pandas 对数据进行分组和聚合操作的内容,通过分组操作可以将数据根据不同的组类进行分组,通过聚合函数可以达到对每组数据的不同分析需要。本节课程的重点如下:
- 了解分组和聚合之间的关系;
- 掌握分组操作 groupby () 函数的使用方法;
- 掌握常用的聚合操作函数的使用方法。