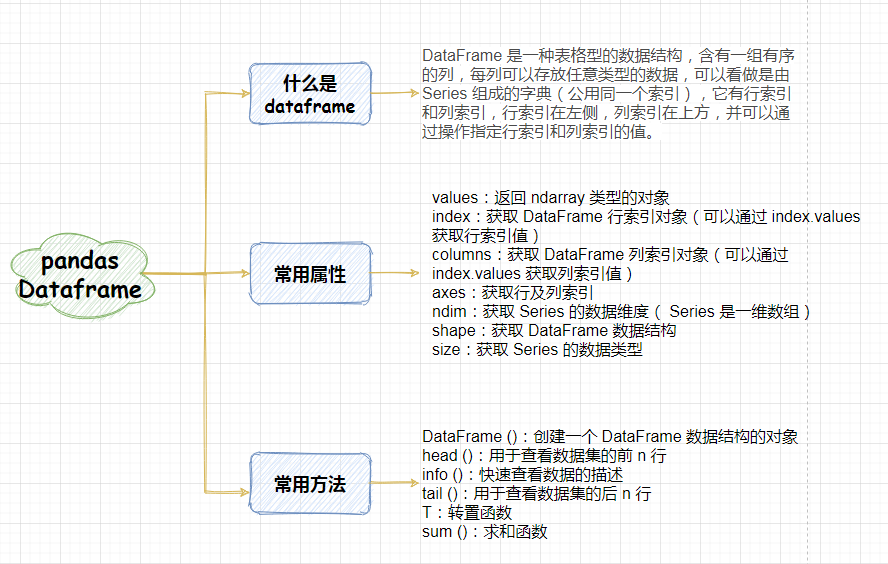
Pandas 数据结构 DataFrame
1. 前言
上一节我们讲述了 Pandas 两种数据结构之一 Series,并介绍了该数据结构的特点、常用属性及方法。Series 数据结构能有效的描述我们实际应用中的一维数据,然而,我们实际生活中接触较多的是有行和列的二维数据,那 Pandas 库中的二维数据结构又是怎样表示的呢?
Pandas 库中的 DataFrame 是一个二维数据结构,可以想象成我们常用的 Excel,它是Pandas 应用中最常用的数据结构。
2. DataFrame 数据结构概述
DataFrame 是一种表格型的数据结构,含有一组有序的列,每列可以存放任意类型的数据,可以看做是由Series组成的字典(公用同一个索引),它有行索引和列索引,行索引在左侧,列索引在上方,并可以通过操作指定行索引和列索引的值。
3. DataFrame 数据结构常用的属性
3.1 DataFrame 常用的属性
| 常用属性 | 属性描述 |
|---|---|
| values | 返回 ndarray 类型的对象 |
| index | 获取 DataFrame 行索引对象(可以通过 index.values 获取行索引值) |
| columns | 获取 DataFrame 列索引对象(可以通过 index.values 获取列索引值) |
| axes | 获取行及列索引 |
| ndim | 获取 Series 的数据维度( Series 是一维数组) |
| shape | 获取 DataFrame 数据结构 |
| size | 获取 Series 的数据类型 |
DataFrame 数据结构的属性和 Series 的部分属性内容是相同的,但因为是二维数据结构,也有自己独特的一些属性,下面我们通过代码逐一介绍。
实例:我们通过定义一个 DataFrame 数据结构,然后分别演示上面的属性操作。
# 引入pandas
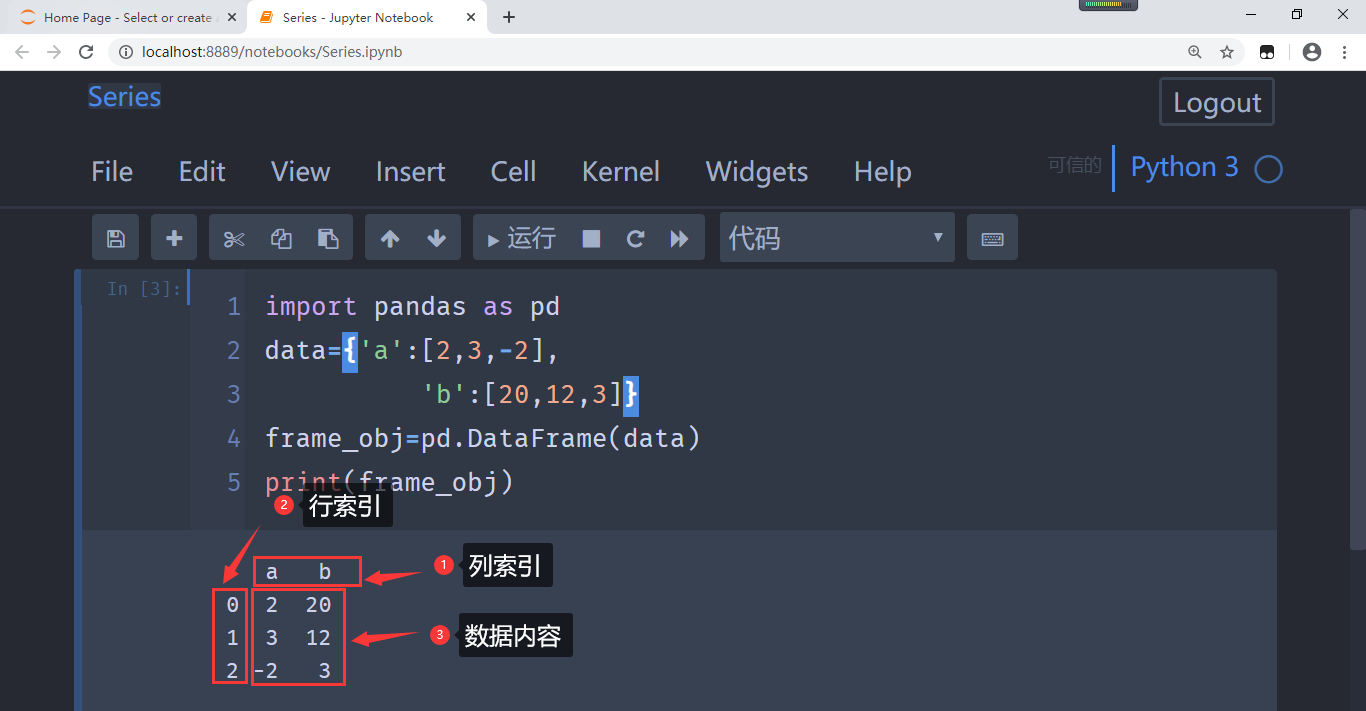
import pandas as pd
# 定义一个dataframe数据结构的对象
data={'bookname':['python入门','python编程','python实战'],
'author':['Eric','张健','刘辉'],
'price':['49.9','36.5','67.4']}
frame_obj=pd.DataFrame(data)
print(frame_obj)
# --- 输出结果 ---
bookname author price
0 python入门 Eric 49.9
1 python编程 张健 36.5
2 python实战 刘辉 67.4
具体的属性操作:
# values 属性
print(frame_obj.values)
#--- 输出结果 ---
[['python入门' 'Eric' '49.9']
['python编程' '张健' '36.5']
['python实战' '刘辉' '67.4']] # 一个ndarray类型的对象
# index 属性
print(frame_obj.index.values)
#--- 输出结果 ---
[0 1 2] # 这是一个一维数组 是dataframe数据对象的行索引值
# columns 属性
print(frame_obj.columns.values)
#--- 输出结果 ---
['bookname' 'author' 'price'] # 这是一个一维数组 是dataframe数据对象的列索引值
# axes 属性
print(frame_obj.axes)
#--- 输出结果 ---
[RangeIndex(start=0, stop=3, step=1), Index(['bookname', 'author', 'price'], dtype='object')] # 对应的行索引和列索引
# ndim 属性
print(frame_obj.ndim)
#--- 输出结果 ---
2 # 2正式dataframe的数据维度
# shape 属性
print(frame_obj.shape)
#--- 输出结果 ---
(3, 3) # 该dataframe数据结构是3行3列的
# size 属性
print(frame_obj.size)
#--- 输出结果 ---
9 # 数据的个数,二维3乘以3是9个数据
3.2 DataFrame 常用的操作方法
接下来我们一起看下dataframe的常用方法,见证这个二维数据的厉害吧。
| 常用函数 | 函数描述 |
|---|---|
| DataFrame() | 创建一个DataFrame数据结构的对象 |
| head() | 用于查看数据集的前n行 |
| info() | 快速查看数据的描述 |
| tail() | 用于查看数据集的后n行 |
| T | 转置函数 |
| sum() | 求和函数 |
下面我们分别看一下每个方法的具体操作实例:
DataFrame() 方法
该方法用于创建 DataFrame 对象,我们可以指定行索引和列索引创建,还可以通过字典进行创建。下面代码中分部创建一个4*4的 DataFrame。
# 1.通过传入数据,行索引,列索引进行创建
df1=pd.DataFrame([[1,2,3,4],[5,6,7,8],[9,10,11,12],[13,14,15,16]],
index=list('ABCD'),columns=list('ABCD'))
print(df1)
# --- 输出结果 ---
A B C D
A 1 2 3 4
B 5 6 7 8
C 9 10 11 12
D 13 14 15 16
# 第一个参数是存放在DataFrame里的数据,第二个index是行名索引,第三个columns是列索引,注意:这里index,columns的list长度要和对应的行和列索引数量一致,不然会报错。
# 1.通过字典进行创建
data={'A':['1','2','3','4'],
'B':['5','6','7','8'],
'C':['9','10','10','11'],
'D':['12','13','14','15']}
df2=pd.DataFrame(data)
print(df2)
# --- 输出结果 ---
A B C D
0 1 5 9 12
1 2 6 10 13
2 3 7 10 14
3 4 8 11 15
head() 方法
该方法通过传入的值,查找数据的的前n行
# 2.head(2) 取前两行数据
data={'A':['1','2','3','4'],
'B':['5','6','7','8'],
'C':['9','10','10','11'],
'D':['12','13','14','15']}
df2=pd.DataFrame(data)
print(df2.head(2))
# --- 输出结果 ---
A B C D
0 1 5 9 12
1 2 6 10 13
# 这里我们输出了前两行的数据
info() 方法
通过该方法,可以看到数据的描述信息摘要,在对数据进行探索性分析时比较有用,比如行和列数,每个值的类型,以及非空值的数量。
# 3.info() 取前两行数据
data={'A':['1','2','3','4'],
'B':['5','6','7','8'],
'C':['9','10','10','11'],
'D':['12','13','14','15']}
df2=pd.DataFrame(data)
print(df2.info())
# --- 输出结果 ---
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4 entries, 0 to 3
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 A 4 non-null object
1 B 4 non-null object
2 C 4 non-null object
3 D 4 non-null object
dtypes: object(4)
memory usage: 256.0+ bytes
None
tail() 方法
通过传入的值,返回 DataFrame 对象的后几行数据
# 4.tail(2) 取后两行数据
data={'A':['1','2','3','4'],
'B':['5','6','7','8'],
'C':['9','10','10','11'],
'D':['12','13','14','15']}
df2=pd.DataFrame(data)
print(df2.tail(2))
# --- 输出结果 ---
A B C D
2 3 7 10 14
3 4 8 11 15
# 这里输出的是后两行数据
T 方法
直接字母 T,可以将 DataFrame 的行和列进行置换。
# 5.T 进行置换行和列
data={'A':['1','2','3','4'],
'B':['5','6','7','8'],
'C':['9','10','10','11'],
'D':['12','13','14','15']}
df2=pd.DataFrame(data)
print(df2)
# --- 输出结果 ---
A B C D
0 1 5 9 12
1 2 6 10 13
2 3 7 10 14
3 4 8 11 15 # 原dataframe
print(df2.T)
# --- 输出结果 ---
0 1 2 3
A 1 2 3 4
B 5 6 7 8
C 9 10 10 11
D 12 13 14 15 # 进行置换后,行和列位置变换
sum() 方法
sum() 是求和方法,默认是对每列求和,传入 1 也就是 sum(1) ,是对每行进行求和。
# 1.sum()对每列求和,sum(1)对每行进行求和
data={'A':[1,2,3,4],
'B':[5,6,7,8],
'C':[9,10,11,12],
'D':[13,14,15,16]}
df2=pd.DataFrame(data)
print(df2)
# --- 输出结果 ---
A B C D
0 1 5 9 13
1 2 6 10 14
2 3 7 11 15
3 4 8 12 16 # 原dataframe数据
print(df2.sum())
# --- 输出结果 ---
A 10
B 26
C 42
D 58
dtype: int64 # 对每列进行求和
print(df2.sum(1))
# --- 输出结果 ---
0 28
1 32
2 36
3 40
dtype: int64 # 对每行进行求和
4. 小结
该小节内容讲述了 Pandas 库中的第二个重要数据结构 DataFrame ,它作为二维数据结构,拥有 Series 之外的独特属性和方法内容。本节课程的重点如下:
- DataFrame 数据结构的常用属性;
- DataFrame 数据结构的常用操作方法;