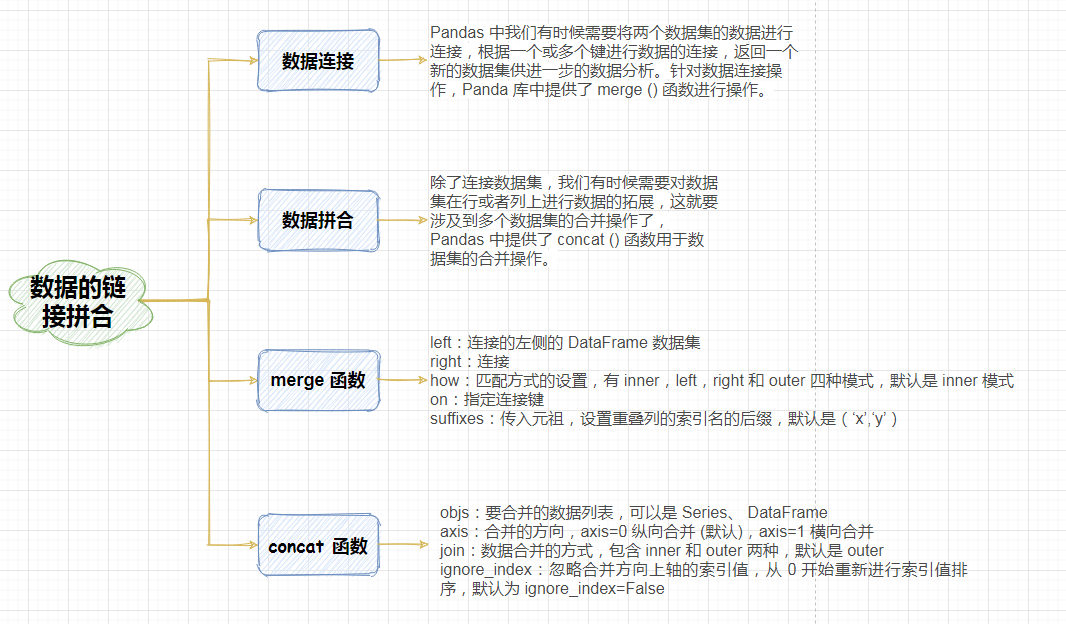
Pandas 数据的连接拼合
1. 前言
上一小节我们学习了 Pandas 库的算术运算,主要包括加法 add (),减法 sub (),乘法 mul () 和除法 div () 运算,以及每个操作中应该注意的事项,日常数据处理中,除了数据集之间的算术运算,我们有时候还需要像数据库查询那样进行数据的连接和合并操作,为进一步的数据分析做好铺垫。那作为强大的数据处理分析库 Pandas 中有没有专门提供数据集之间进行数据连接或合并的操作呢?
本节课我们将一起学习 Pandas 库对于数据连接和合并的操作,主要涉及两个操作函数 merge () 和 concat () ,接下来我们将详细的学习数据合并和连接的具体操作内容。
2. 数据的连接操作
Pandas 中我们有时候需要将两个数据集的数据进行连接,根据一个或多个键进行数据的连接,返回一个新的数据集供进一步的数据分析。针对数据连接操作,Panda 库中提供了 merge () 函数进行操作。
在讲解函数功能之前,我们这里准备了两个 Excel 数据,数据内容分别如下图:
数据文件:execl 数据 demo01.xlsx
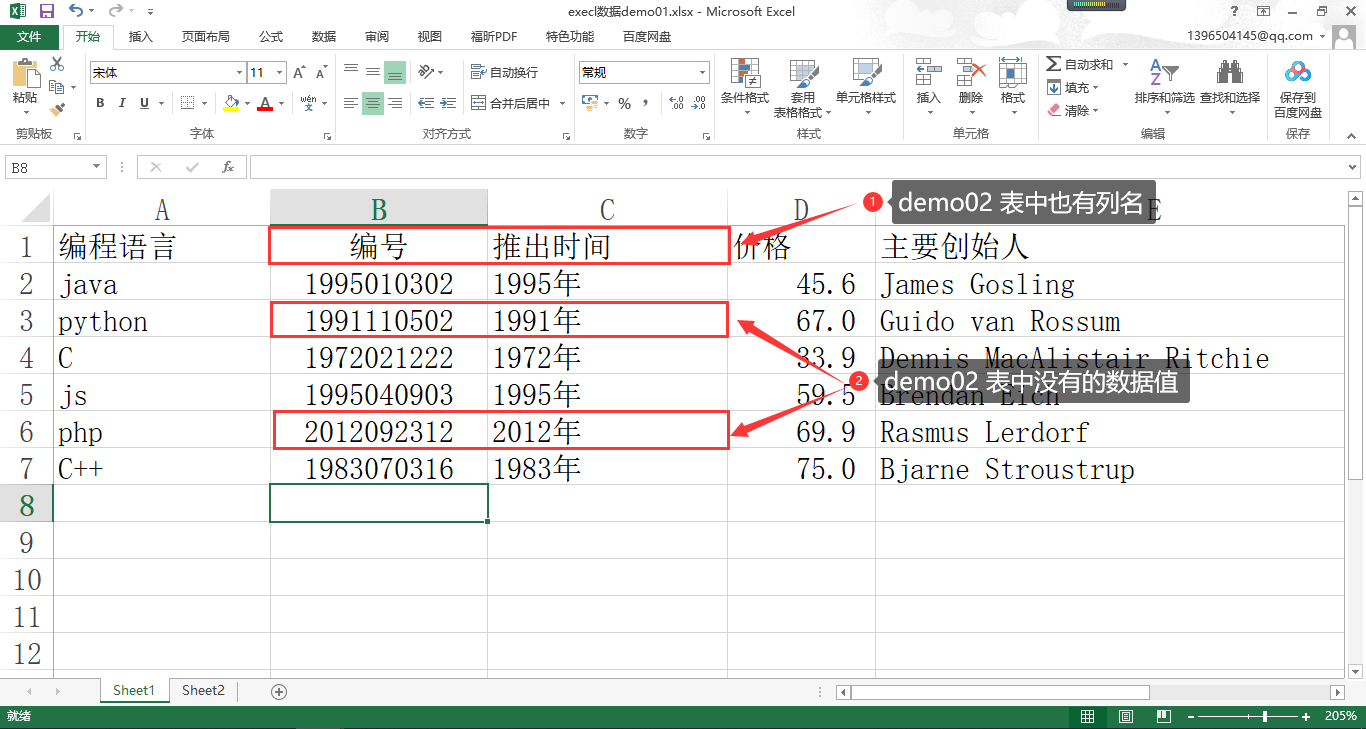
数据文件:execl 数据 demo02.xlsx
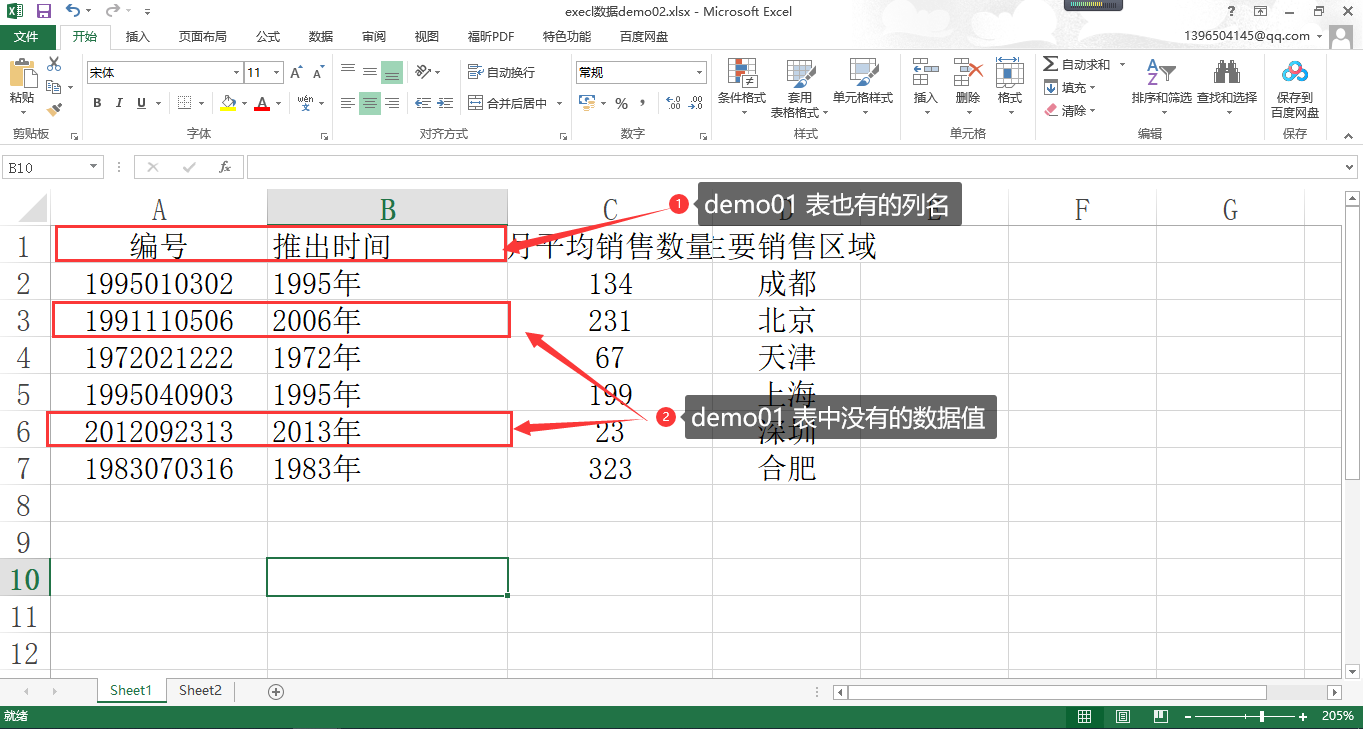
我们通过 Pandas 进行数据解析:
# 导入pandas包
import pandas as pd
data_path_01="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data\_source/第14小节/execl数据demo01.xlsx"
data_path_02="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data\_source/第14小节/execl数据demo02.xlsx"
# 解析数据
data_01 = pd.read_excel(data_path_01)
data_02 = pd.read_excel(data_path_02)
print(data_01)
print(data_02)
# --- 输出结果 data\_01 ---
编程语言 编号 推出时间 价格 主要创始人
0 java 1995010302 1995年 45.6 James Gosling
1 python 1991110502 1991年 67.0 Guido van Rossum
2 C 1972021222 1972年 33.9 Dennis MacAlistair Ritchie
3 js 1995040903 1995年 59.5 Brendan Eich
4 php 2012092312 2012年 69.9 Rasmus Lerdorf
5 C++ 1983070316 1983年 75.0 Bjarne Stroustrup
# --- 输出结果 data\_02 ---
编号 推出时间 月平均销售数量 主要销售区域
0 1995010302 1995年 134 成都
1 1991110506 2006年 231 北京
2 1972021222 1972年 67 天津
3 1995040903 1995年 199 上海
4 2012092313 2013年 23 深圳
5 1983070316 1983年 323 合肥
输出解析:通过上面的描述可以看到,我们的数据集 data_01 和 data_02 他们都有 “编号” 和 “推出时间” 这两列,对应这两列两个数据集中有相同的数据,也有不同数据。
2.1 merge () 函数
该函数提供了丰富的参数,灵活的设置数据的连接方式,下面我们列举了该函数几个常用的参数。
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None)
| 参数名 | 说明 |
|---|---|
| left | 连接的左侧的 DataFrame 数据集 |
| right | 连接 |
| how | 匹配方式的设置,有 inner,left,right 和 outer 四种模式,默认是 inner 模式 |
| on | 指定连接键 |
| suffixes | 传入元祖,设置重叠列的索引名的后缀,默认是(‘x’,‘y’) |
- how 参数
该参数有四个值:
- inner:是默认的匹配方式,根据两个表的交集部分进行匹配连接;
- left:以左边的数据表为基础,匹配右边的数据表,匹配不到的通过 NaN 进行填充;
- right:以右边的数据表为基础,匹配左边的数据表,匹配不到的通过 NaN 进行填充;
- outer:将两个数据表连接汇总成一个表,有匹配的展示结果,没有匹配的填充 NaN。
下面我们通过代码程序详细的演示一下四种模式的区别:
# data\_01 和 data\_02 是从两个excel表中解析出的数据集
# merge 函数,默认的 how = “inner”
data_res=pd.merge(data_01,data_02,how="inner")
print(data_res)
# --- 输出结果 ---
编程语言 编号 推出时间 价格 主要创始人 月平均销售数量 主要销售区域
0 java 1995010302 1995年 45.6 James Gosling 134 成都
1 C 1972021222 1972年 33.9 Dennis MacAlistair Ritchie 67 天津
2 js 1995040903 1995年 59.5 Brendan Eich 199 上海
3 C++ 1983070316 1983年 75.0 Bjarne Stroustrup 323 合肥
输出解析:默认的 inner 匹配方式,会通过两个数据集对应的列索引进行数据的匹配,寻找两个数据集中在 “编号” 和 “推出时间” 上匹配的数据进行连接。因为两个数据集在 “编号” 和 “推出时间” 上,只有四个共同数据,通过 inner 方式匹配,结果只有四行数据。
# data\_01 和 data\_02 是从两个excel表中解析出的数据集
# merge 函数, how = “left”
data_res=pd.merge(data_01,data_02,how="left")
print(data_res)
# --- 输出结果 ---
编程语言 编号 推出时间 价格 主要创始人 月平均销售数量 主要销售区域
0 java 1995010302 1995年 45.6 James Gosling 134.0 成都
1 python 1991110502 1991年 67.0 Guido van Rossum NaN NaN
2 C 1972021222 1972年 33.9 Dennis MacAlistair Ritchie 67.0 天津
3 js 1995040903 1995年 59.5 Brendan Eich 199.0 上海
4 php 2012092312 2012年 69.9 Rasmus Lerdorf NaN NaN
5 C++ 1983070316 1983年 75.0 Bjarne Stroustrup 323.0 合肥
输出解析:left 匹配方式,是以左侧数据集的连接键值为标准,通过连接键将右边的数据集进行连接,如果数据在连接键上相匹配,就把数据连接进来,如果左侧数据连接键的值没有找到右侧与之对应的数据,就在右侧数据填充 NaN 。
# data\_01 和 data\_02 是从两个excel表中解析出的数据集
# merge 函数, how = “right”
data_res=pd.merge(data_01,data_02,how="right")
print(data_res)
# --- 输出结果 ---
编程语言 编号 推出时间 价格 主要创始人 月平均销售数量 主要销售区域
0 java 1995010302 1995年 45.6 James Gosling 134 成都
1 NaN 1991110506 2006年 NaN NaN 231 北京
2 C 1972021222 1972年 33.9 Dennis MacAlistair Ritchie 67 天津
3 js 1995040903 1995年 59.5 Brendan Eich 199 上海
4 NaN 2012092313 2013年 NaN NaN 23 深圳
5 C++ 1983070316 1983年 75.0 Bjarne Stroustrup 323 合肥
输出解析:right 匹配方式,是以右侧数据集的连接键值为标准,通过连接键将左侧的数据集进行连接,如果在连接键上左侧数据和右侧数据相匹配,就把左侧的数据连接进来,右侧数据连接键上数据左侧数据没有与之匹配的数据,则以 NaN 进行填充。
# data\_01 和 data\_02 是从两个excel表中解析出的数据集
# merge 函数, how = “outer”
data_res=pd.merge(data_01,data_02,how="outer")
print(data_res)
# --- 输出结果 ---
编程语言 编号 推出时间 价格 主要创始人 月平均销售数量 主要销售区域
0 java 1995010302 1995年 45.6 James Gosling 134.0 成都
1 python 1991110502 1991年 67.0 Guido van Rossum NaN NaN
2 C 1972021222 1972年 33.9 Dennis MacAlistair Ritchie 67.0 天津
3 js 1995040903 1995年 59.5 Brendan Eich 199.0 上海
4 php 2012092312 2012年 69.9 Rasmus Lerdorf NaN NaN
5 C++ 1983070316 1983年 75.0 Bjarne Stroustrup 323.0 合肥
6 NaN 1991110506 2006年 NaN NaN 231.0 北京
7 NaN 2012092313 2013年 NaN NaN 23.0 深圳
输出解析:outer 匹配方式,是以连接键为标准,将左右两边的数据集进行连接,如果连接键存中两个数据集存在匹配的数据,则把左右数据进行连接,如果有一个数据集不存在匹配数据,则用 NaN 进行填充。
- on 参数
该参数用于指定数据集的连接键,默认的是两个数据集中共有的列索引,就像我们上面的 data_01 和 data_02 数据集,他们都有 “编号” 和 “推出时间” 列,因此这两列就是默认的连接键。当然我们也可以用 on 参数指定其中的一列为连接键,如下代码演示:
# data\_01 和 data\_02 是从两个excel表中解析出的数据集
# merge 函数, on = “编号”
data_res=pd.merge(data_01,data_02,on=["编号"])
print(data_res)
# --- 输出结果 ---
编程语言 编号 推出时间_x 价格 主要创始人 推出时间_y 月平均销售数量 主要销售区域
0 java 1995010302 1995年 45.6 James Gosling 1995年 134 成都
1 C 1972021222 1972年 33.9 Dennis MacAlistair Ritchie 1972年 67 天津
2 js 1995040903 1995年 59.5 Brendan Eich 1995年 199 上海
3 C++ 1983070316 1983年 75.0 Bjarne Stroustrup 1983年 323 合肥
输出解析:这里我们指定了关键键为” 编号 “列,因此在数据匹配时,将以该列进行数据的匹配连接操作,因为两个数据集中均有” 推出时间 “列,因此会默认加上后缀 ”x“,”y“ 作为区分,当然后面我们会讲到对后缀的修改操作。
Tips:在这里我们需要注意指定连接键时传入的是列表数据,可以是多个数据列,但一定要是连接数据集中都有的列索引,否则会报错 KeyError ,如下面代码所示。
# data\_01 和 data\_02 是从两个excel表中解析出的数据集
# merge 函数, on = “主要创始人”
data_res=pd.merge(data_01,data_02,on=["主要创始人"])
print(data_res)
# --- 输出结果 ---
……
1561 values = self.axes[axis].get_level_values(key)._values
1562 else:
-> 1563 raise KeyError(key)
1564
1565 # Check for duplicates
KeyError: '主要创始人'
输出解析:这里可以看到,我们指定了连接键是 “主要创始人”,并不是两个数据集中都有的列索引,因此会报错。
- suffixes 参数
该参数用于指定连接后数据集中重复列索引的后缀,默认的是(‘x’,‘y’):
# data\_01 和 data\_02 是从两个excel表中解析出的数据集
# merge 函数,suffixes
data_res=pd.merge(data_01,data_02,on=["编号"],suffixes=("AA","BB") )
print(data_res)
# --- 输出结果 ---
编程语言 编号 推出时间AA 价格 主要创始人 推出时间BB 月平均销售数量 主要销售区域
0 java 1995010302 1995年 45.6 James Gosling 1995年 134 成都
1 C 1972021222 1972年 33.9 Dennis MacAlistair Ritchie 1972年 67 天津
2 js 1995040903 1995年 59.5 Brendan Eich 1995年 199 上海
3 C++ 1983070316 1983年 75.0 Bjarne Stroustrup 1983年 323 合肥
输出解析:通过 suffixes 参数指定重复列索引值所添加的后缀值,通过输出结果可以看出 “推出时间” 分别加上上 AA, BB 的后缀。
3. 数据的合并操作
除了连接数据集,我们有时候需要对数据集在行或者列上进行数据的拓展,这就要涉及到多个数据集的合并操作了,Pandas 中提供了 concat () 函数用于数据集的合并操作。
同样的在正式讲解该函数使用之前,我们先准备一下数据源。
数据文件:execl 数据 demo03.xlsx
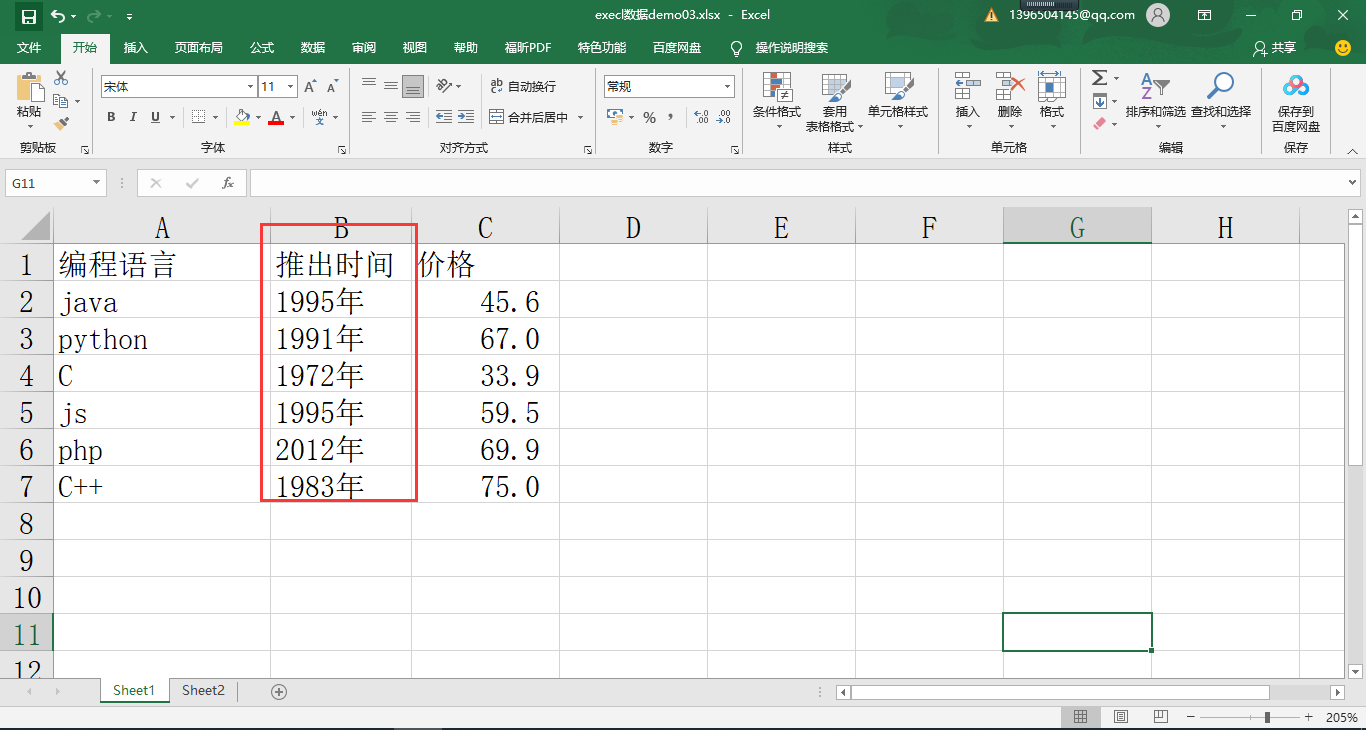
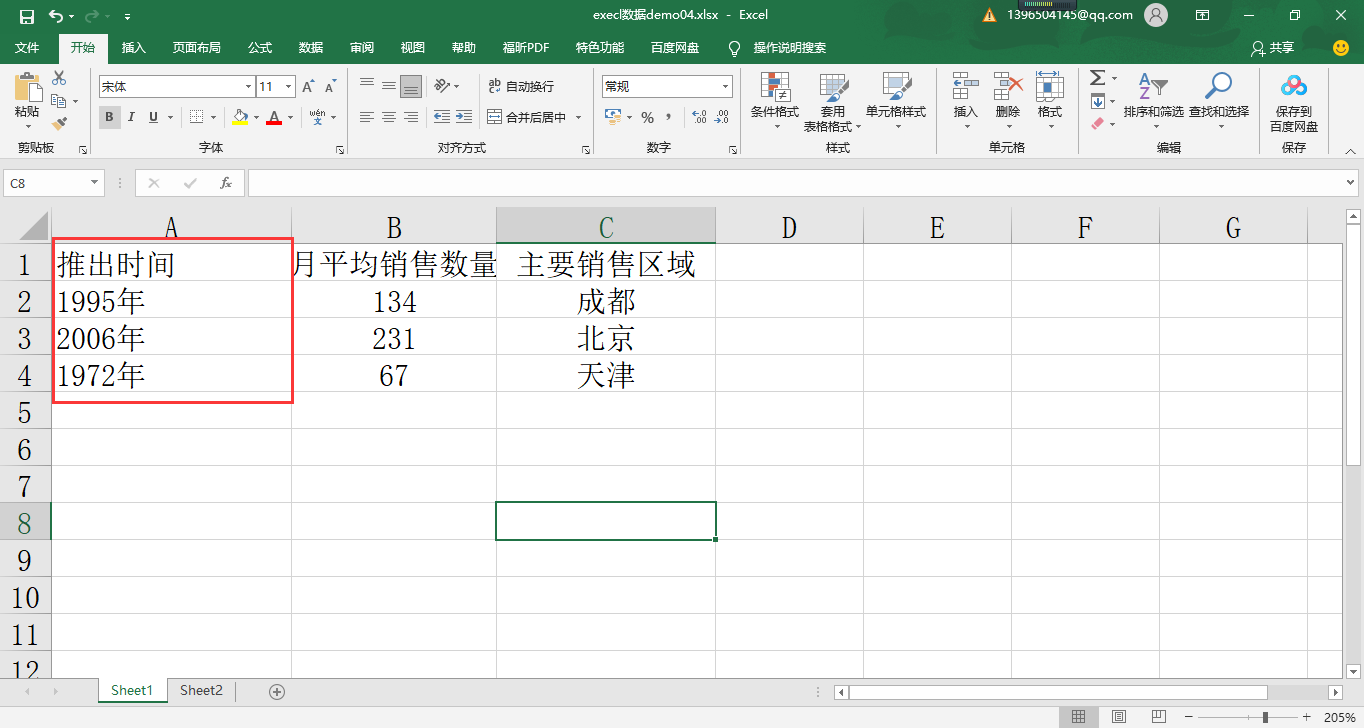
数据文件:execl 数据 demo04.xlsx
数据文件:execl 数据 demo05.xlsx

通过 Pandas 将数据解析出来,数据对象分别为:data_03 ,data_04 ,data_05
# 导入pandas包
import pandas as pd
data_path_03="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data\_source/第14小节/execl数据demo03.xlsx"
data_path_04="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data\_source/第14小节/execl数据demo04.xlsx"
data_path_05="C:/Users/13965/Documents/myFuture/IMOOC/pandasCourse-progress/data\_source/第14小节/execl数据demo05.xlsx"
# 解析数据
data_03 = pd.read_excel(data_path_03)
data_04 = pd.read_excel(data_path_04)
data_05 = pd.read_excel(data_path_05)
print(data_03)
# --- 输出结果 data\_03 ---
编程语言 推出时间 价格
0 java 1995年 45.6
1 python 1991年 67.0
2 C 1972年 33.9
3 js 1995年 59.5
4 php 2012年 69.9
5 C++ 1983年 75.0
print(data_04)
# --- 输出结果 data\_04---
推出时间 月平均销售数量 主要销售区域
0 1995年 134 成都
1 2006年 231 北京
2 1972年 67 天津
print(data_05)
# --- 输出结果 ---
推出时间 月份 发行地点
0 1995年 12 广州
1 2006年 2 上海
2 1972年 4 南京
3 2017年 5 北京
输出解析:我们构造了三个数据集,他们都有 "推出时间" 数据列,其他列名均不一样,在数据的量上也存在差异,data_03 有 6 条数据,data_04 有 3 条数据,data_05 有 4 条数据。
3.1 concat () 函数
对于多个数据集的合并操作,concat () 函数提供了丰富的设置参数,满足我们灵活的合并需要,这里我们列举几个常用的参数进行详细讲解。
pd.concat(objs, axis='0', join:'outer', ignore_index: 'False', keys='None', levels='None', names='None', verify_integrity: 'False', sort: 'False', copy:'True')
| 参数名 | 说明 |
|---|---|
| objs | 要合并的数据列表,可以是 Series、 DataFrame |
| axis | 合并的方向,axis=0 纵向合并 (默认),axis=1 横向合并 |
| join | 数据合并的方式,包含 inner 和 outer 两种,默认是 outer |
| ignore_index | 忽略合并方向上轴的索引值,从 0 开始重新进行索引值排序,默认为 ignore_index=False |
下面我们通过代码程序进行详细学习这些参数的使用。
- axis 参数
该参数用于设置数据合并的方向。
# data\_03,data\_04,data\_05 是上面从三个excel表中解析出的数据集
# concat 函数,axis=0 是纵向上按行合并。
data_res=pd.concat([data_03,data_04,data_05],axis=0)
print(data_res)
# --- 输出结果 ---
编程语言 推出时间 价格 月平均销售数量 主要销售区域 月份 发行地点
0 java 1995年 45.6 NaN NaN NaN NaN
1 python 1991年 67.0 NaN NaN NaN NaN
2 C 1972年 33.9 NaN NaN NaN NaN
3 js 1995年 59.5 NaN NaN NaN NaN
4 php 2012年 69.9 NaN NaN NaN NaN
5 C++ 1983年 75.0 NaN NaN NaN NaN
0 NaN 1995年 NaN 134.0 成都 NaN NaN
1 NaN 2006年 NaN 231.0 北京 NaN NaN
2 NaN 1972年 NaN 67.0 天津 NaN NaN
0 NaN 1995年 NaN NaN NaN 12.0 广州
1 NaN 2006年 NaN NaN NaN 2.0 上海
2 NaN 1972年 NaN NaN NaN 4.0 南京
3 NaN 2017年 NaN NaN NaN 5.0 北京
# 输出解析:通过设置 axis=0 在纵向上合并数据,总的行数据量是3个数据集的总和,扩充了行数据。
# concat 函数,axis=1 设置在横向上合并。
data_res=pd.concat([data_03,data_04,data_05],axis=1)
print(data_res)
# --- 输出结果 ---
编程语言 推出时间 价格 推出时间 月平均销售数量 主要销售区域 推出时间 月份 发行地点
0 java 1995年 45.6 1995年 134.0 成都 1995年 12.0 广州
1 python 1991年 67.0 2006年 231.0 北京 2006年 2.0 上海
2 C 1972年 33.9 1972年 67.0 天津 1972年 4.0 南京
3 js 1995年 59.5 NaN NaN NaN 2017年 5.0 北京
4 php 2012年 69.9 NaN NaN NaN NaN NaN NaN
5 C++ 1983年 75.0 NaN NaN NaN NaN NaN NaN
# 输出解析:通过设置 axis=1 在横向上合并数据,总的列数据量是3个数据集的总和,扩充了列数据。
- join 参数
该参数设置数据集合并的方式,有两个值:
- inner:数据集之间的交集,行合并时取列索引值的相同的数据,列合并时取行索引值相同的数据;
- outer:取数据集之间的并集,没有数据的用 NaN 进行填充,默认是这种合并方式。
# data\_03,data\_04,data\_05 是上面从三个excel表中解析出的数据集
# concat 函数,axis=1,join="outer" 设置合并的方式。
data_res=pd.concat([data_03,data_04,data_05],axis=1,join="outer")
print(data_res)
# --- 输出结果 ---
编程语言 推出时间 价格 推出时间 月平均销售数量 主要销售区域 推出时间 月份 发行地点
0 java 1995年 45.6 1995年 134.0 成都 1995年 12.0 广州
1 python 1991年 67.0 2006年 231.0 北京 2006年 2.0 上海
2 C 1972年 33.9 1972年 67.0 天津 1972年 4.0 南京
3 js 1995年 59.5 NaN NaN NaN 2017年 5.0 北京
4 php 2012年 69.9 NaN NaN NaN NaN NaN NaN
5 C++ 1983年 75.0 NaN NaN NaN NaN NaN NaN
# 输出解析:这里设置在横向上合并列数据,合并方式为 outer ,所以将所有数据集的行索引取了并集,data\_03 的行索引值为0-5,data\_04 的行索引值为0-2,data\_5 的行索引值为0-3,他们的并集就是 data\_03 的从0到5,对于 data\_04 和 data\_05 在对应的行索引上不存在数据的,则以 NaN 进行填充。
# concat 函数,axis=0,join="outer" 设置合并的方式。
data_res=pd.concat([data_03,data_04,data_05],axis=0,join="outer")
print(data_res)
# --- 输出结果 ---
编程语言 推出时间 价格 月平均销售数量 主要销售区域 月份 发行地点
0 java 1995年 45.6 NaN NaN NaN NaN
1 python 1991年 67.0 NaN NaN NaN NaN
2 C 1972年 33.9 NaN NaN NaN NaN
3 js 1995年 59.5 NaN NaN NaN NaN
4 php 2012年 69.9 NaN NaN NaN NaN
5 C++ 1983年 75.0 NaN NaN NaN NaN
0 NaN 1995年 NaN 134.0 成都 NaN NaN
1 NaN 2006年 NaN 231.0 北京 NaN NaN
2 NaN 1972年 NaN 67.0 天津 NaN NaN
0 NaN 1995年 NaN NaN NaN 12.0 广州
1 NaN 2006年 NaN NaN NaN 2.0 上海
2 NaN 1972年 NaN NaN NaN 4.0 南京
3 NaN 2017年 NaN NaN NaN 5.0 北京
# 输出解析: 这里设置了在纵向上的行合并,合并方式为 outer,在列索引上取了并集,为{“编程语言”,“推出时间”,“价格”,“月平均销售数量”,“主要销售区域”,“月份”,“发行地点”},合并行中如果不存在对应列的数据,则以 NaN 进行填充。
# concat 函数,axis=1,join="inner" 设置合并的方式。
data_res=pd.concat([data_03,data_04,data_05],axis=1,join="inner")
print(data_res)
# --- 输出结果 ---
编程语言 推出时间 价格 推出时间 月平均销售数量 主要销售区域 推出时间 月份 发行地点
0 java 1995年 45.6 1995年 134 成都 1995年 12 广州
1 python 1991年 67.0 2006年 231 北京 2006年 2 上海
2 C 1972年 33.9 1972年 67 天津 1972年 4 南京
# 输出解析:这里设置了在横向上合并列数据,合并方式为 inner ,在行索引值中去交集,data\_03 的行索引值为0-5,data\_04 的行索引值为0-2,data\_5 的行索引值为0-3,他们的交集也就是0到2,可以看到输出结果合并了列,取了三行数据。
# concat 函数,axis=0,join="inner" 设置合并的方式。
data_res=pd.concat([data_03,data_04,data_05],axis=0,join="inner")
print(data_res)
# --- 输出结果 ---
推出时间
0 1995年
1 1991年
2 1972年
3 1995年
4 2012年
5 1983年
0 1995年
1 2006年
2 1972年
0 1995年
1 2006年
2 1972年
3 2017年
# 输出解析:通过设置在行上进行数据合并,用的 inner 方式合并,在列的数据上,他们的交集只有“推出时间”,通过输出可以看到效果。
通过上面的代码演示可以看到,因为 outer 取得是并集,合并结果中可能会出现 NaN 的填充数据,而 inner 取的是交集,合并数据结果集中不会出现 NaN 的缺失数据。
- ignore_index 参数
该参数可以设置在合并方向上的索引值自动生成,从 0 开始的整数序列。
# data\_03,data\_04,data\_05 是上面从三个excel表中解析出的数据集
# concat 函数,ignore\_index 重新生成索引序列。
data_res=pd.concat([data_03,data_04,data_05],axis=1,ignore_index=False)
print(data_res)
# --- 输出结果 ignore\_index=False(默认的值)---
编程语言 推出时间 价格 推出时间 月平均销售数量 主要销售区域 推出时间 月份 发行地点
0 java 1995年 45.6 1995年 134.0 成都 1995年 12.0 广州
1 python 1991年 67.0 2006年 231.0 北京 2006年 2.0 上海
2 C 1972年 33.9 1972年 67.0 天津 1972年 4.0 南京
3 js 1995年 59.5 NaN NaN NaN 2017年 5.0 北京
4 php 2012年 69.9 NaN NaN NaN NaN NaN NaN
5 C++ 1983年 75.0 NaN NaN NaN NaN NaN NaN
data_res=pd.concat([data_03,data_04,data_05],axis=1,ignore_index=True)
print(data_res)
# --- 输出结果 ignore\_index=True ---
0 1 2 3 4 5 6 7 8
0 java 1995年 45.6 1995年 134.0 成都 1995年 12.0 广州
1 python 1991年 67.0 2006年 231.0 北京 2006年 2.0 上海
2 C 1972年 33.9 1972年 67.0 天津 1972年 4.0 南京
3 js 1995年 59.5 NaN NaN NaN 2017年 5.0 北京
4 php 2012年 69.9 NaN NaN NaN NaN NaN NaN
5 C++ 1983年 75.0 NaN NaN NaN NaN NaN NaN
输出解析:这里通过 ignore_index 参数设置的对比,可以看到在列索引上的索引值的变化。
4. 小结
本节课程我们主要学习了 Pandas 对多个数据集之间的连接和合并操作,对数据的拼接和扩展有重要的帮助,主要涉及到了两个操作函数以及每个操作函数中常用的参数意义。本节课程的重点如下:
- merge () 函数的适用场景,以及该函数常用的参数设置;
- concat () 函数的适用场景,以及该函数常用的参数设置。