如何绕过反爬虫技术分析
对于大型网站的爬取我们经常会面临网站设定的反爬技术封锁,比如输入图片验证码、识别图中汉字,甚至直接禁止你的 ip 等。这样我们的爬虫可能刚开始运行不久就会遭受严重打击,无法进行下去。如何才能伪装的更像正常的请求是我们本节关注的重点。
1. 反爬封锁应对措施
面对网站的反爬封锁,我们往往有如下几个应对措施,这些基本的方法已经能应对大部分网站的封锁。更为深入的拟人技术还需要读者自行去探索,多加实战。
1.1 修改请求头
我们前面爬虫的第一步都是在请求头中添加正常浏览器的 user-agent,但是请求头的参数不止这些,还有一个值也会经常被检查到,那就是 referer 字段,它会告诉服务器该请求是从哪个页面链接过来的,服务器基此可以获得一些信息用于处理,因此为了更好的防止请求被封,我们也要尽量在请求 header 中加上referer 字段以及其正确的值。
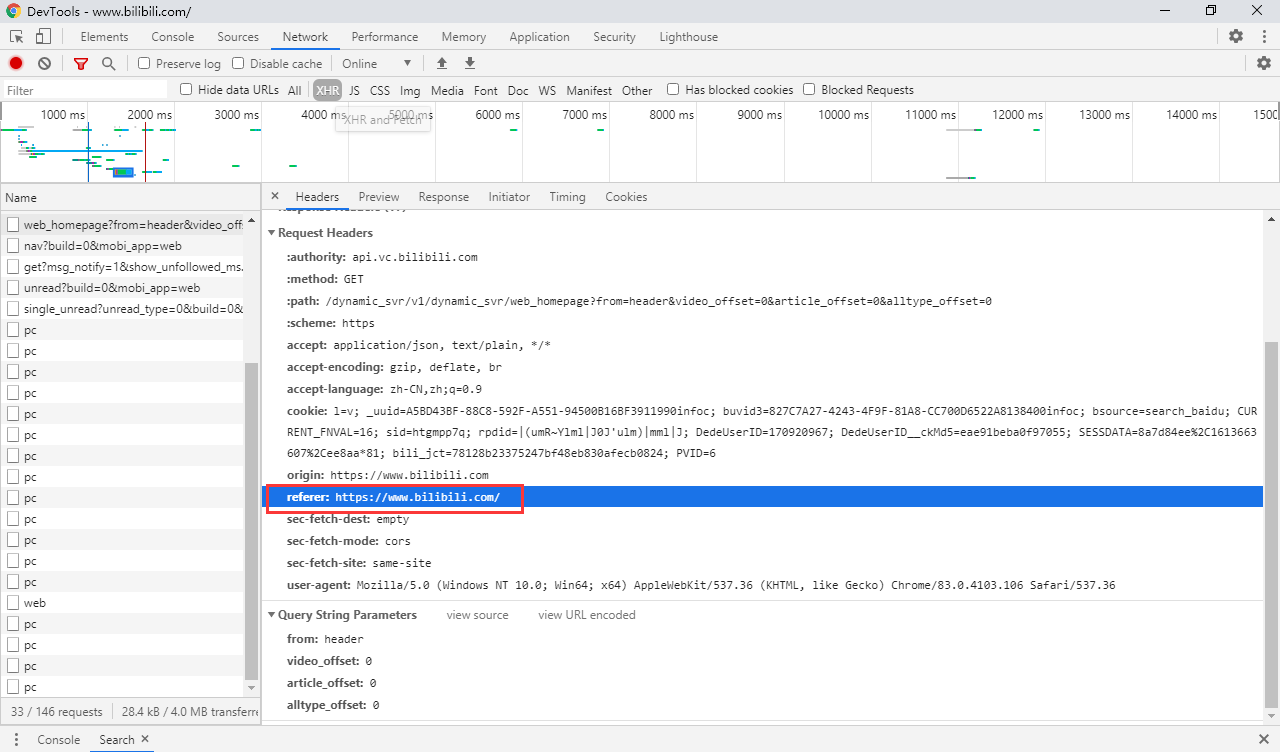
另外,user-agent 是每个反爬网站必查的字段,如果大量请求重复使用固定的 user-agent 值,在某些程序中也会被判定为爬虫。因此我们可以对所有的请求采用随机的 user-agent 值来避免这种反爬检测。Scrapy 中的中间件 UserAgentMiddleware 就是专门用来设置请求头中 user-agent 值的。
1.2 降低请求频率
正常情况下,我们的每次请求都会被记录,如果我们请求太快,比如1秒内发送10次请求,这明显不是手动实现的,很容易被识别然后采取相应措施。我们不管是在普通的爬虫代码还是 scrapy 中都要设置请求的间隔时间,防止被检测出来。在普通的爬虫程序中,我们直接使用 python 的 time 模块,调用 time.sleep() 方法进行延时调用,而在 Scrapy 中,我们只需要在 settings.py 中设置 DOWNLOAD_DELAY 的值即可。例如:
DOWNLOAD_DELAY = 2
上述的配置表示我们将两次请求的间隔设置为 2 秒,这已经是一个符合人正常操作的时间间隔了。不过太过于规律的请求同样会被更为智能的程序察觉,为了避免出现这样的情况,在 Scrapy 框架的配置中提供了 RANDOMIZE_DOWNLOAD_DELAY 参数。当它设置为 True 时 ,Scrapy 会在两次下载请求间设置一个 0.5 * DOWNLOAD_DELAY 到 1.5 * DOWNLOAD_DELAY 之间的一个随机延迟时间。
1.3 禁用Cookie
有些网站会通过 Cookie 来发现爬虫的踪迹,因此,我们在进行普通网站数据爬取时可以考虑关闭 Cookie:
COOKIES_ENABLED = False
不过,对于一些需要登录后进行操作的,比如我们之前爬取起点用户书架以及删除书架上数据的爬虫,则需要使用 COOKIES 的情况下,我们不能禁用 Cookie。所以,特定场景需要特定的配置,不能一概而论。
1.4 验证码突破
许多做的非常好的网站都会有验证码校验,比如京东、淘宝的登录。更为复杂的还有12306网站那个让人头晕的识图验证等等。目前而言,验证码技术从原来的简单数字、字母识别,到滑块拖动、拼图认证以及最新的图片识别、汉字倒立等,已经越来越复杂和难辨。很多基于机器学习以及深度学习的高难度识别算法应运而生,但这些对于普通程序员而言,难以企及。我们唯有两方面突破:
- 花钱买服务:网上有不少专门的验证码识别服务提供商,比如几年前比较流行的若快平台 (目前官网无法访问,似乎已经凉了)等;
- 开源项目:如果舍不得花钱买服务的,我们只能寄希望于部分开源工具。好在还是有不少大神愿意将他们的研究代码、工具进行开源,这也使得我们能有机会去学习和使用这些工具去突破验证码的限制;
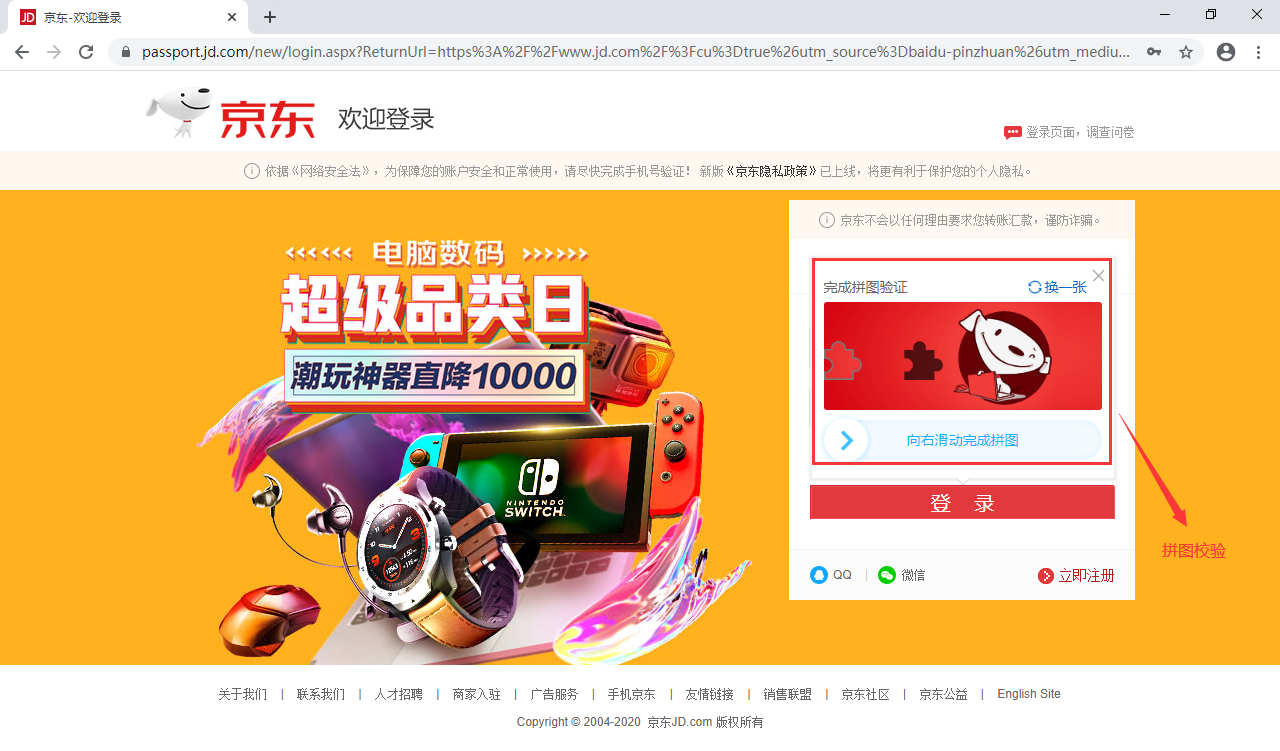
京东的拼图验证
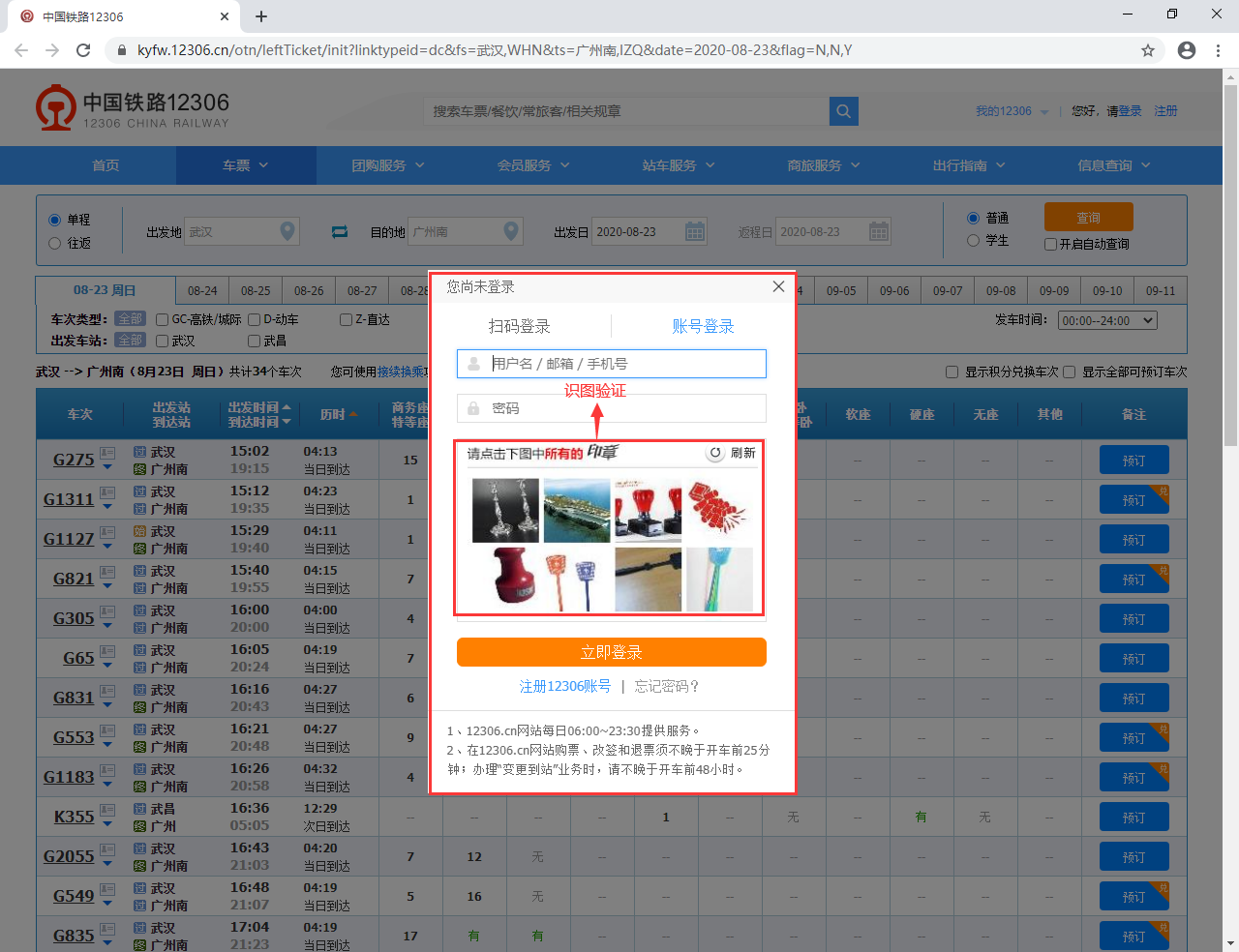
12306的识图验证
1.5 使用 ip 代理
对于一些比较狠的网站,会对一些爬虫的程序客户端 ip 进行封杀,这样我们至少在一段时间内无法在运行该程序去爬取网站数据。此时,我们可以使用代理 ip 去隐藏真实的请求 ip,这样又可以访问网站并爬取数据。如果这个代理 ip 被封了怎么办?那就需要有多个可用的代理 ip,一旦发现该 ip 被封,我们立马换下一个 ip 代理继续请求数据。假设我们有十万代理 ip,每个代理能支撑我们爬取 1分钟数据,那么我们至少能顺利爬取2个多月,且一般1-2天左右,原来被封的 ip 又会被解除禁封。这样,只要我们有大量的 ip 代理,我们就不怕网站的封杀,能源源不断获取相应的网站数据。那么到哪里去获取这样免费的代理 ip 呢?同样有两种途径:
- 网络上的免费 ip 代理:免费、不稳定且大部分不可用;
- 付费 ip 代理池:略贵、大部分稳定可用;
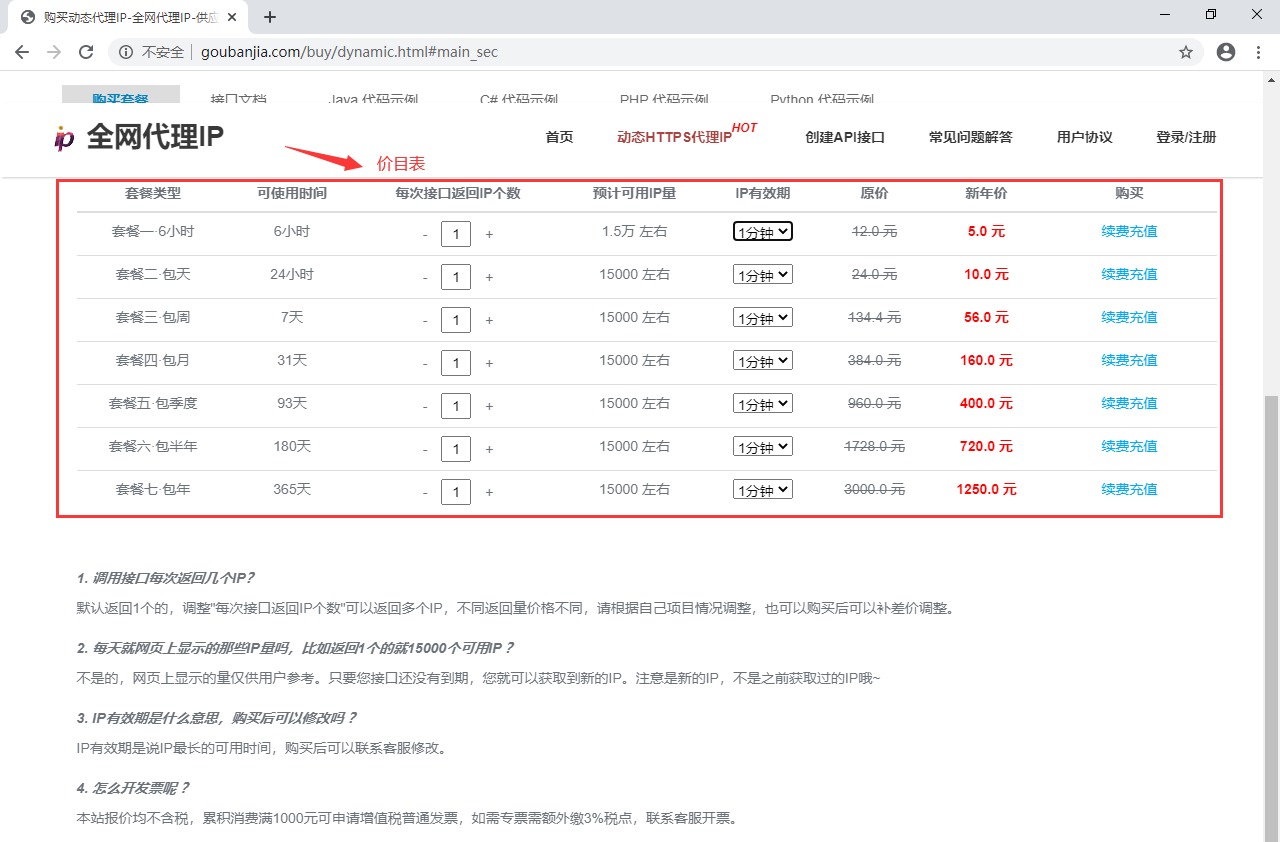
在 github 上也有许多维护和获取免费代理服务器地址的项目,我们也可以直接使用这些免费的项目帮我们抓取并维护可用的代理 ip 池。
2. 伪装成随机浏览器
我们来看看 Scrapy 给我们提供的、用于伪装 User-Agent 字段的中间件:UserAgentMiddleware 。其定义位于 scrapy/downloadermiddlewares/useragent.py 文件中,我们来看看其具体内容:
class UserAgentMiddleware:
"""This middleware allows spiders to override the user\_agent"""
def \_\_init\_\_(self, user_agent='Scrapy'):
self.user_agent = user_agent
@classmethod
def from\_crawler(cls, crawler):
o = cls(crawler.settings['USER\_AGENT'])
crawler.signals.connect(o.spider_opened, signal=signals.spider_opened)
return o
def spider\_opened(self, spider):
self.user_agent = getattr(spider, 'user\_agent', self.user_agent)
def process\_request(self, request, spider):
if self.user_agent:
request.headers.setdefault(b'User-Agent', self.user_agent)
从上面的代码我们可以看到,该中间件会从 settings.py 中取得 USER_AGENT 参数值, 然后进行实例化:
o = cls(crawler.settings['USER\_AGENT'])
在处理请求的核心方法 process_request() 会将该值赋给请求头中的 User-Agent 字段。注意该中间件属于下载中间件,在 Scrapy 中默认被启用,如下图所示:
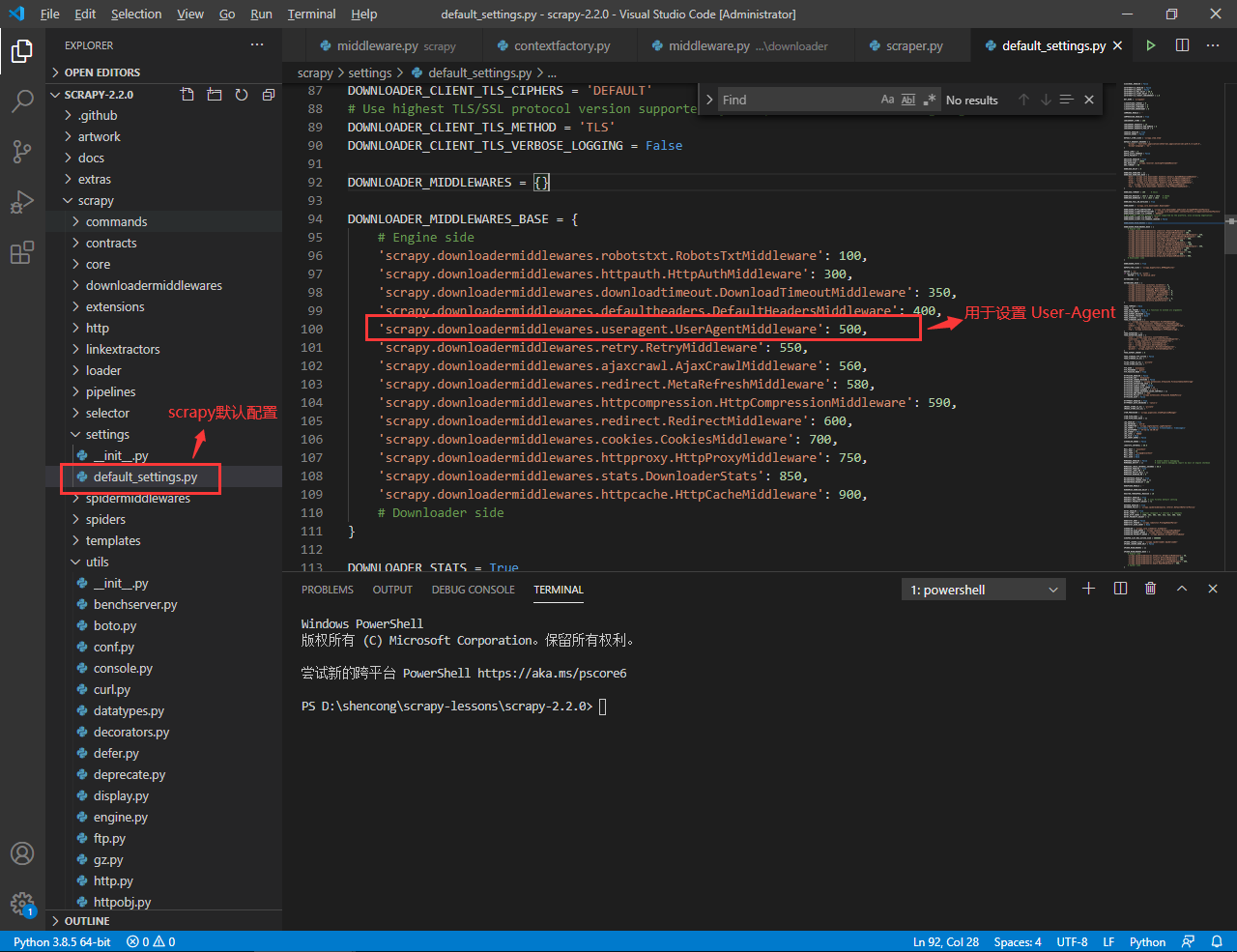
我们来看看如何在这个中间件的基础上实现随机的 User-Agent 请求:
- 编写一个基于
UserAgentMiddleware的中间件类,可以放到 scrapy 项目的 middlewares.py 文件中。这里我们使用 fake-useragent 模块来帮我们生成各种各样的user-agent值,这样避免我们手工维护一个 user-agent 的值列表。该模块的使用非常简单:
(scrapy-test) [root@server china_pub]# python
Python 3.8.1 (default, Dec 24 2019, 17:04:00)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-39)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from fake_useragent import UserAgent
>>> ua = UserAgent()
>>> ua.random
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10\_10\_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.124 Safari/537.36'
>>> ua.random
'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2049.0 Safari/537.36'
>>> ua.random
'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1464.0 Safari/537.36'
>>> ua.random
'Mozilla/5.0 (Windows NT 6.2; rv:21.0) Gecko/20130326 Firefox/21.0'
>>>
注意:使用这个模块需要联网,根据相应的版本要请求网站的相应接口,获取相应数据。例如我这里的版本是0.1.11,于是请求的 URL 及其接口数据如下:
来看我们自定义的中间件代码如下:
# 写入位置:scrapy项目的middlewares.py文件中
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
from fake_useragent import UserAgent
# ...
class MyUserAgentMiddleware(UserAgentMiddleware):
def process\_request(self, request, spider):
ua = UserAgent()
user_agent = ua.random
if user_agent:
request.headers.setdefault(b'User-Agent', user_agent)
return None
- 另外,我们这里继承了
UserAgentMiddleware中间件,那么原来的这个中间件就失去了意义、因此,在 settings.py 中,我们要启用新的设置 User-Agent 的中间件且关闭原来的中间件:
# 代码位置:scrapy项目的settings.py文件中
DOWNLOADER_MIDDLEWARES = {
'项目名称.middlewares.MyUserAgentMiddleware': 500,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
}
3. 使用代理
在 Scrapy 项目中使用代理是非常简单的一件事情,我们只需要在发送的 Request 请求中添加 meta 参数即可实现代理功能:
yield Request(url, callback=回调方法, errback=错误回调, meta={"proxy": proxy, "download\_timeout": 10})
上面生成的 Request 请求带上了 meta 参数,该参数中又设置了代理服务器的地址以及相应的超时时间。我们可以简单来看看代理服务器的使用:
- 首先我们来自己搭建一个 Nginx 服务,具体的搭建过程可以参考这个教程: Nginx入门手册;
- 接着我们使用9999这个端口做为代理转发端口,相关的配置如下:
# nginx.conf
server {
resolver 114.114.114.114;
resolver\_timeout 5s;
listen 9999;
location / {
proxy\_pass $scheme://$host$request\_uri;
proxy\_set\_header Host $http\_host;
proxy\_buffers 256 8k;
proxy\_max\_temp\_file\_size 0;
proxy\_connect\_timeout 30;
proxy\_cache\_valid 200 302 10m;
proxy\_cache\_valid 301 1h;
proxy\_cache\_valid any 1m;
}
}
- 启动 nginx 服务后,我们这个代理服务就搞定了。我们可以使用 requests 测试下这个代理服务,看看是不是生效了:
import requests
proxies = {
"http": "http://180.76.152.113:9999",
}
response = requests.get("http://www.china-pub.com/browse/", proxies=proxies)
response.encoding = 'gbk'
print(response.text)
上述代码位于另一台云服务器,请求的是互动出版物的图书分类页面,这次我们会在 requests 请求中加上我们刚刚配置的代理,使用 nginx 代理转发请求,请看视频演示: