一个简单的爬虫实例
今天我们来简单完成一个网站爬虫例子,体验下基本的爬虫工作流程。在有这个体验之后,才能更好地理解框架的重要性。
1. 网络爬虫之网站分析
这一节我们来爬取一个图书网站:互动出版网。之所以选择这个网站,主要是它的数据比较好爬取,没有反爬虫机制,且网站的结构也不复杂,比较适合作为菜鸟进行练手。我们首先来分析网站及其相关的 HTML 元素,确定要爬取的内容。
互动出版网的网站首页如下:
互动出版网首页 可以看到,这个网站没有用到 https,依旧使用的是 http 协议,这个网站是极不安全的。我们现在要爬取的是这个网站的计算机类的图书,我们可以点击全部图书分类那里,得到所有图书的分类情况。
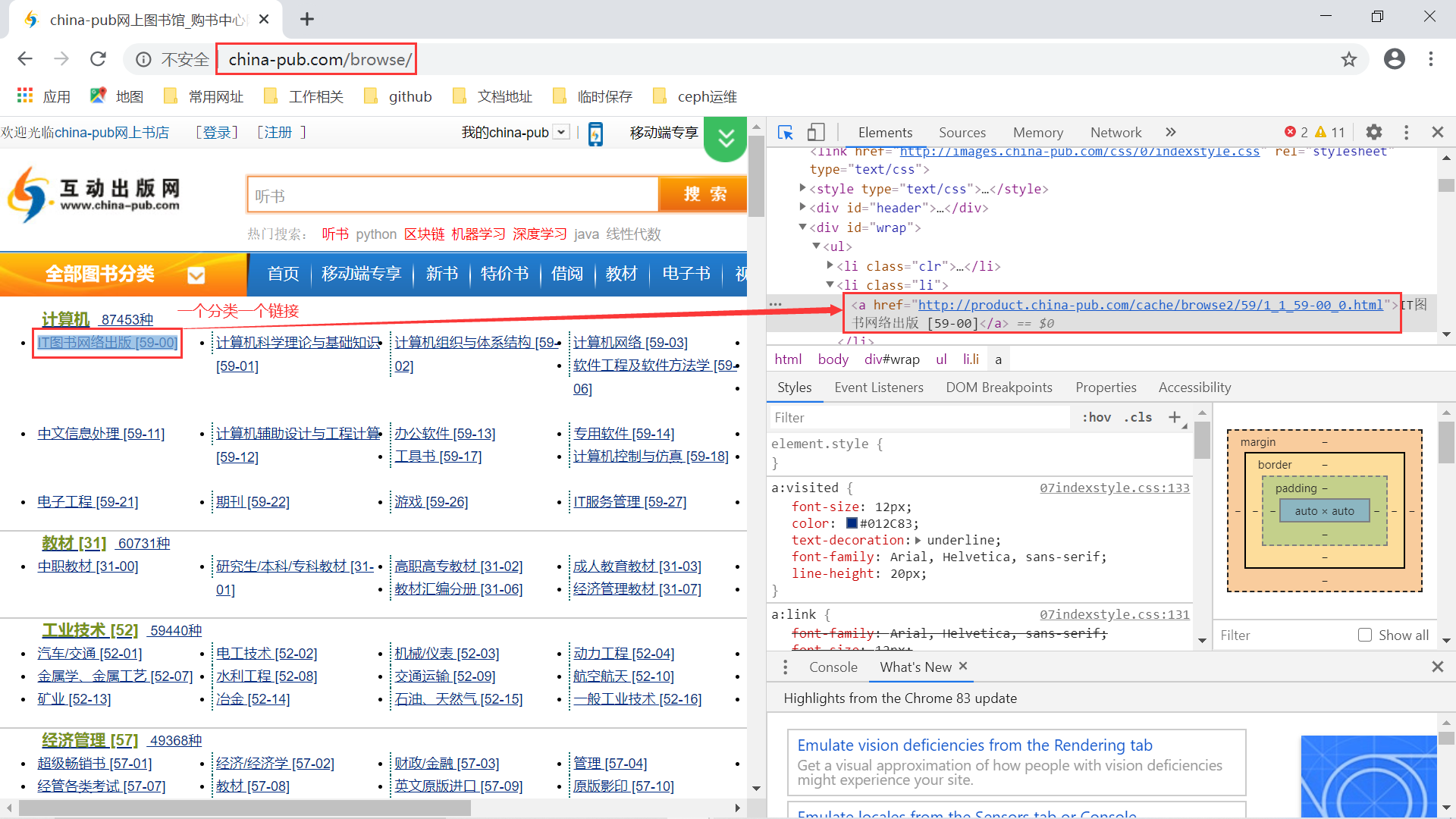
互动出版网全部图书分类 通过 F12 可以看到,每个计算机的分类对应着一个链接。我们点进去看就会得到对应分类下的图书列表,还带着分页信息:
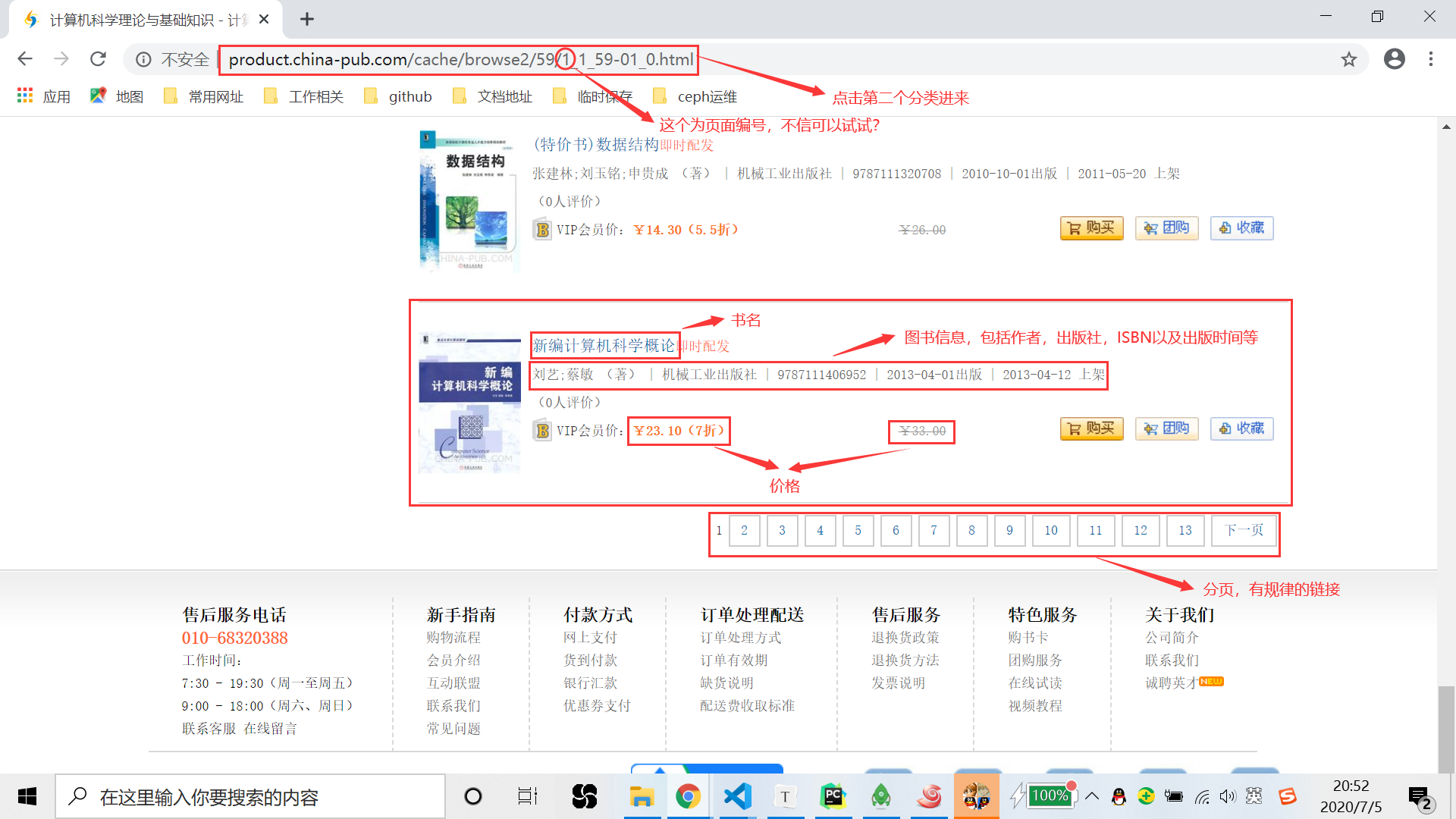
互动出版网计算机分类图书列表 从这个页面中,我们可以分析到很多,首先对于一个图书信息,我们想要提取的数据有:
- 图书标题;
- 图书作者;
- 出版社;
- ISBN;
- 出版时间;
- 图书价格。
至于图书的详情页面我们就不再进去看了,详情页中能到到更多信息,比如总页数、图书简介、目录等等。此外,这里有一个分页信息,通过多次点击可以发现,只是前面的 url 中的一个数字发生了变化,因此我们可以直接构造出相应页数的 url 请求,获取其他页的图书列表、还等什么呢?开始激动人心的图书数据爬取流程吧!!!
2. 网络爬虫之爬取流程
根据上面的分析,我们来设计相应的爬取流程,总体上有如下几个步骤:
获取计算机图书下的分类列表,包括对应的 URL。我们可以实现一个函数专门请求分类页面,然后提取相应的 URL 列表:
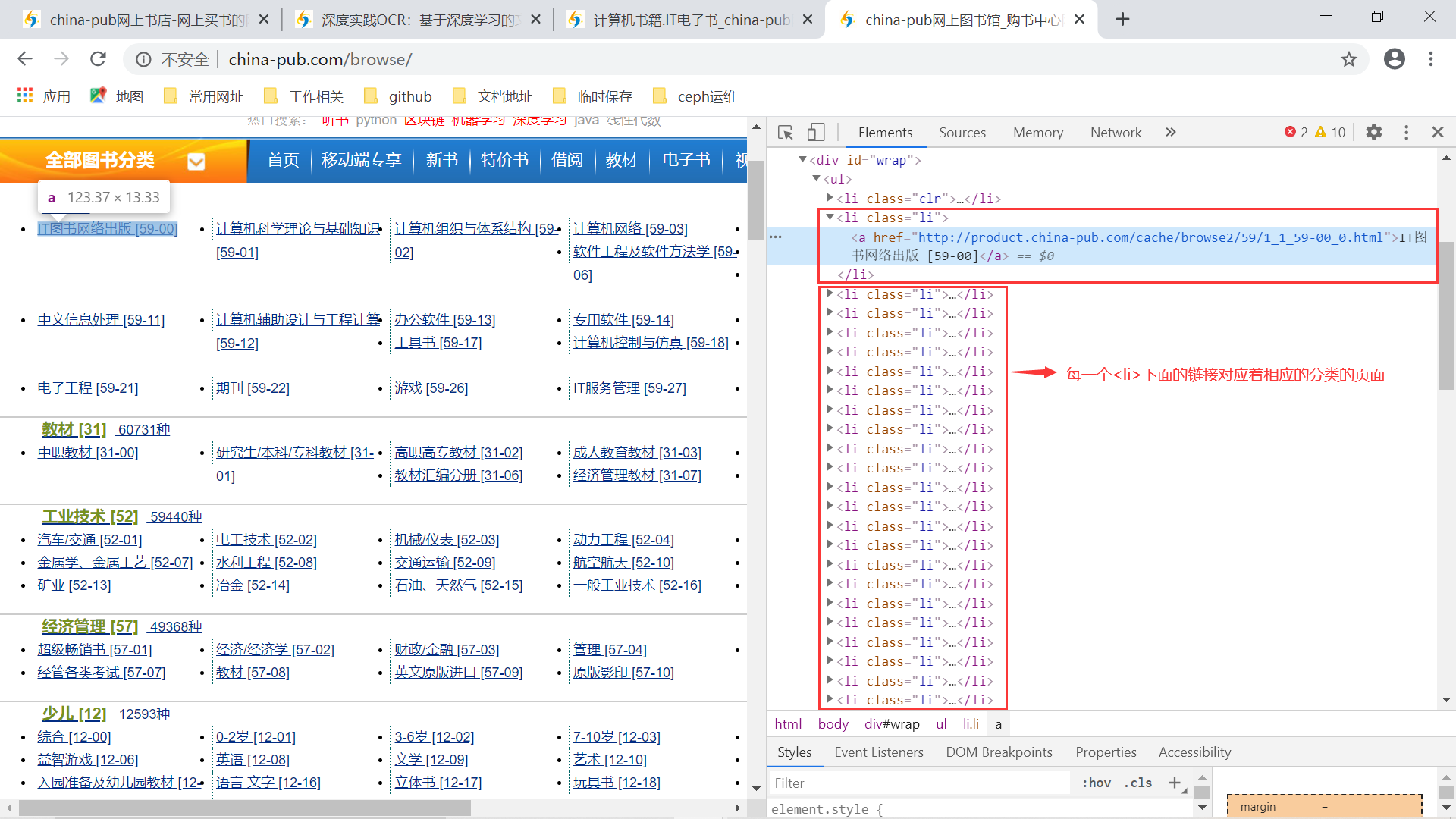
分类列表的HTML元素 专门完成一个函数,读取计算机分类下的图书列表。通过不断的分页查询将这个分类下的所有图书信息全部抓取到。
http://product.china-pub.com/cache/browse2/59/{页号}_1_59-{分类编号}_0.html
分类编号不用管,我们会自行提取 URL。而对于请求的页号,可以自行设定,从1开始请求,每次加1,直到请求的 URL 返回 404 时,表明这个分类下的图书列表请求完毕,然后就可以进行下一个分类的请求了。
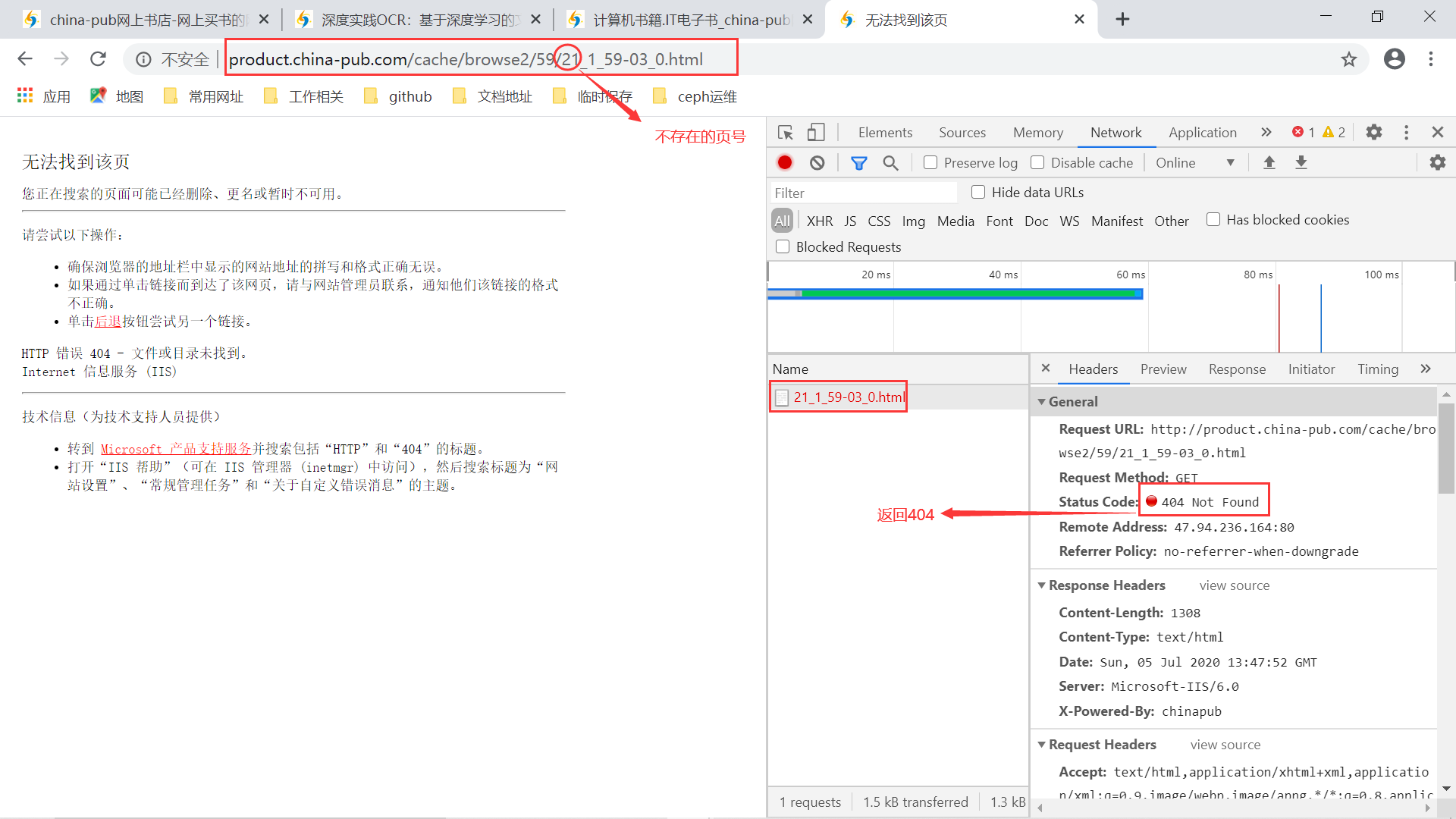
请求不存在的页号 最后完成一个简单的保存函数,保存采集到的数据库。这个就比较简单了,我们直接将采集到的图书信息成批地保存到 MongoDB 数据库中。
3. 图书爬虫之代码实现
根据上面的分析,我们来实现相应的代码。首先是完成获取计算机的所有分类以及相应的 URL 地址:
def get\_all\_computer\_book\_urls(page_url):
"""
获取所有计算机分类图书的url地址
:return:
"""
response = requests.get(url=page_url, headers=headers)
if response.status_code != 200:
return [], []
response.encoding = 'gbk'
tree = etree.fromstring(response.text, etree.HTMLParser())
# 提取计算机分类的文本列表
c = tree.xpath("//div[@id='wrap']/ul[1]/li[@class='li']/a/text()")
# 提取计算机分类的url列表
u = tree.xpath("//div[@id='wrap']/ul[1]/li[@class='li']/a/@href")
return c, u
我们简单测试下这个函数:
[store@server2 chap06]$ python3
Python 3.6.8 (default, Apr 2 2020, 13:34:55)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-39)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from china_pub_crawler import get_all_computer_book_urls
>>> get_all_computer_book_urls('http://www.china-pub.com/Browse/')
(['IT图书网络出版 [59-00]', '计算机科学理论与基础知识 [59-01]', '计算机组织与体系结构 [59-02]', '计算机网络 [59-03]', '安全 [59-04]', '软件与程序设计 [59-05]', '软件工程及软件方法学 [59-06]', '操作系统 [59-07]', '数据库 [59-08]', '硬件与维护 [59-09]', '图形图像、多媒体、网页制作 [59-10]', '中文信息处理 [59-11]', '计算机辅助设计与工程计算 [59-12]', '办公软件 [59-13]', '专用软件 [59-14]', '人工智能 [59-15]', '考试认证 [59-16]', '工具书 [59-17]', '计算机控制与仿真 [59-18]', '信息系统 [59-19]', '电子商务与计算机文化 [59-20]', '电子工程 [59-21]', '期刊 [59-22]', '游戏 [59-26]', 'IT服务管理 [59-27]', '计算机文化用品 [59-80]'], ['http://product.china-pub.com/cache/browse2/59/1\_1\_59-00\_0.html', 'http://product.china-pub.com/cache/browse2/59/1\_1\_59-01\_0.html', 'http://product.china-pub.com/cache/browse2/59/1\_1\_59-02\_0.html', 'http://product.china-pub.com/cache/browse2/59/1\_1\_59-03\_0.html', 'http://product.china-pub.com/cache/browse2/59/1\_1\_59-04\_0.html', 'http://product.china-pub.com/cache/browse2/59/1\_1\_59-05\_0.html', 'http://product.china-pub.com/cache/browse2/59/1\_1\_59-06\_0.html', 'http://product.china-pub.com/cache/browse2/59/1\_1\_59-07\_0.html', 'http://product.china-pub.com/cache/browse2/59/1\_1\_59-08\_0.html', 'http://product.china-pub.com/cache/browse2/59/1\_1\_59-09\_0.html', 'http://product.china-pub.com/cache/browse2/59/1\_1\_59-10\_0.html', 'http://product.china-pub.com/cache/browse2/59/1\_1\_59-11\_0.html', 'http://product.china-pub.com/cache/browse2/59/1\_1\_59-12\_0.html', 'http://product.china-pub.com/cache/browse2/59/1\_1\_59-13\_0.html', 'http://product.china-pub.com/cache/browse2/59/1\_1\_59-14\_0.html', 'http://product.china-pub.com/cache/browse2/59/1\_1\_59-15\_0.html', 'http://product.china-pub.com/cache/browse2/59/1\_1\_59-16\_0.html', 'http://product.china-pub.com/cache/browse2/59/1\_1\_59-17\_0.html', 'http://product.china-pub.com/cache/browse2/59/1\_1\_59-18\_0.html', 'http://product.china-pub.com/cache/browse2/59/1\_1\_59-19\_0.html', 'http://product.china-pub.com/cache/browse2/59/1\_1\_59-20\_0.html', 'http://product.china-pub.com/cache/browse2/59/1\_1\_59-21\_0.html', 'http://product.china-pub.com/cache/browse2/59/1\_1\_59-22\_0.html', 'http://product.china-pub.com/cache/browse2/59/1\_1\_59-26\_0.html', 'http://product.china-pub.com/cache/browse2/59/1\_1\_59-27\_0.html', 'http://product.china-pub.com/cache/browse2/59/1\_1\_59-80\_0.html'])
可以看到这个函数已经实现了我们想要的结果。接下来我们要完成一个函数来获取对应分类下的所有图书信息,不过在此之前,我们需要先完成解析单个图书列表页面的方法:
def parse\_books\_page(html_data):
books = []
tree = etree.fromstring(html_data, etree.HTMLParser())
result_tree = tree.xpath("//div[@class='search\_result']/table/tr/td[2]/ul")
for result in result_tree:
try:
book_info = {}
book_info['title'] = result.xpath("./li[@class='result\_name']/a/text()")[0]
book_info['book\_url'] = result.xpath("./li[@class='result\_name']/a/@href")[0]
info = result.xpath("./li[2]/text()")[0]
book_info['author'] = info.split('|')[0].strip()
book_info['publisher'] = info.split('|')[1].strip()
book_info['isbn'] = info.split('|')[2].strip()
book_info['publish\_date'] = info.split('|')[3].strip()
book_info['vip\_price'] = result.xpath("./li[@class='result\_book']/ul/li[@class='book\_dis']/text()")[0]
book_info['price'] = result.xpath("./li[@class='result\_book']/ul/li[@class='book\_price']/text()")[0]
# print(f'解析出的图书信息为:{book\_info}')
books.append(book_info)
except Exception as e:
print("解析数据出现异常,忽略!")
return books
上面的函数主要解析的是一页图书列表数据,同样基于 xpath 定位相应的元素,然后提取我们想要的数据。其中由于部分信息合在一起,我们在提取数据后还要做相关的处理,分别提取对应的信息。我们可以从网页中直接样 HTML 拷贝下来,然后对该函数进行测试:

提取图书列表的网页数据
我们把保存的网页命名为 test.html,放到与该代码同级的目录下,然后进入命令行操作:
>>> from china_pub_crawler import parse_books_page
>>> f = open('test.html', 'r+')
>>> html_content = f.read()
>>> parse_books_page(html_content)
[{'title': '(特价书)零基础学ASP.NET 3.5', 'book\_url': 'http://product.china-pub.com/216269', 'author': '王向军;王欣惠 (著)', 'publisher': '机械工业出版社', 'isbn': '9787111261414', 'publish\_date': '2009-02-01出版', 'vip\_price': 'VIP会员价:', 'price': '¥58.00'}, {'title': 'Objective-C 2.0 Mac和iOS开发实践指南(原书第2版)', 'book\_url': 'http://product.china-pub.com/3770704', 'author': '(美)Robert Clair (著)', 'publisher': '机械工业出版社', 'isbn': '9787111484561', 'publish\_date': '2015-01-01出版', 'vip\_price': 'VIP会员价:', 'price': '¥79.00'}, {'title': '(特价书)ASP.NET 3.5实例精通', 'book\_url': 'http://product.china-pub.com/216272', 'author': '王院峰 (著)', 'publisher': '机械工业出版社', 'isbn': '9787111259794', 'publish\_date': '2009-01-01出版', 'vip\_price': 'VIP会员价:', 'price': '¥55.00'}, {'title': '(特价书)CSS+HTML语法与范例详解词典', 'book\_url': 'http://product.china-pub.com/216275', 'author': '符旭凌 (著)', 'publisher': '机械工业出版社', 'isbn': '9787111263647', 'publish\_date': '2009-02-01出版', 'vip\_price': 'VIP会员价:', 'price': '¥39.00'}, {'title': '(特价书)Java ME 游戏编程(原书第2版)', 'book\_url': 'http://product.china-pub.com/216296', 'author': '(美)Martin J. Wells; John P. Flynt (著)', 'publisher': '机械工业出版社', 'isbn': '9787111264941', 'publish\_date': '2009-03-01出版', 'vip\_price': 'VIP会员价:', 'price': '¥49.00'}, {'title': '(特价书)Visual Basic实例精通', 'book\_url': 'http://product.china-pub.com/216304', 'author': '柴相花 (著)', 'publisher': '机械工业出版社', 'isbn': '9787111263296', 'publish\_date': '2009-04-01出版', 'vip\_price': 'VIP会员价:', 'price': '¥59.80'}, {'title': '高性能电子商务平台构建:架构、设计与开发[按需印刷]', 'book\_url': 'http://product.china-pub.com/3770743', 'author': 'ShopNC产品部 (著)', 'publisher': '机械工业出版社', 'isbn': '9787111485643', 'publish\_date': '2015-01-01出版', 'vip\_price': 'VIP会员价:', 'price': '¥79.00'}, {'title': '[套装书]Java核心技术 卷Ⅰ 基础知识(原书第10版)+Java核心技术 卷Ⅱ高级特性(原书第10版)', 'book\_url': 'http://product.china-pub.com/7008447', 'author': '(美)凯S.霍斯特曼(Cay S. Horstmann)????(美)凯S. 霍斯特曼(Cay S. Horstmann) (著)', 'publisher': '机械工业出版社', 'isbn': '9787007008447', 'publish\_date': '2017-08-01出版', 'vip\_price': 'VIP会员价:', 'price': '¥258.00'}, {'title': '(特价书)Dojo构建Ajax应用程序', 'book\_url': 'http://product.china-pub.com/216315', 'author': '(美)James E.Harmon (著)', 'publisher': '机械工业出版社', 'isbn': '9787111266648', 'publish\_date': '2009-05-01出版', 'vip\_price': 'VIP会员价:', 'price': '¥45.00'}, {'title': '(特价书)编译原理第2版.本科教学版', 'book\_url': 'http://product.china-pub.com/216336', 'author': '(美)Alfred V. Aho;Monica S. Lam;Ravi Sethi;Jeffrey D. Ullman (著)', 'publisher': '机械工业出版社', 'isbn': '9787111269298', 'publish\_date': '2009-05-01出版', 'vip\_price': 'VIP会员价:', 'price': '¥55.00'}, {'title': '(特价书)用Alice学编程(原书第2版)', 'book\_url': 'http://product.china-pub.com/216354', 'author': '(美)Wanda P.Dann;Stephen Cooper;Randy Pausch (著)', 'publisher': '机械工业出版社', 'isbn': '9787111274629', 'publish\_date': '2009-07-01出版', 'vip\_price': 'VIP会员价:', 'price': '¥39.00'}, {'title': 'Java语言程序设计(第2版)', 'book\_url': 'http://product.china-pub.com/50051', 'author': '赵国玲;王宏;柴大鹏 (著)', 'publisher': '机械工业出版社\*', 'isbn': '9787111297376', 'publish\_date': '2010-03-01出版', 'vip\_price': 'VIP会员价:', 'price': '¥32.00'}, {'title': '从零开始学Python程序设计', 'book\_url': 'http://product.china-pub.com/7017939', 'author': '吴惠茹 (著)', 'publisher': '机械工业出版社', 'isbn': '9787111583813', 'publish\_date': '2018-01-01出版', 'vip\_price': 'VIP会员价:', 'price': '¥79.00'}, {'title': '(特价书)汇编语言', 'book\_url': 'http://product.china-pub.com/216385', 'author': '郑晓薇 (著)', 'publisher': '机械工业出版社', 'isbn': '9787111269076', 'publish\_date': '2009-09-01出版', 'vip\_price': 'VIP会员价:', 'price': '¥29.00'}, {'title': '(特价书)Visual Basic.NET案例教程', 'book\_url': 'http://product.china-pub.com/216388', 'author': '马玉春;刘杰民;王鑫 (著)', 'publisher': '机械工业出版社', 'isbn': '9787111272571', 'publish\_date': '2009-09-01出版', 'vip\_price': 'VIP会员价:', 'price': '¥30.00'}, {'title': '小程序从0到1:微信全栈工程师一本通', 'book\_url': 'http://product.china-pub.com/7017943', 'author': '石桥码农 (著)', 'publisher': '机械工业出版社', 'isbn': '9787111584049', 'publish\_date': '2018-01-01出版', 'vip\_price': 'VIP会员价:', 'price': '¥59.00'}, {'title': '深入分布式缓存:从原理到实践', 'book\_url': 'http://product.china-pub.com/7017945', 'author': '于君泽 (著)', 'publisher': '机械工业出版社', 'isbn': '9787111585190', 'publish\_date': '2018-01-01出版', 'vip\_price': 'VIP会员价:', 'price': '¥99.00'}, {'title': '(特价书)ASP.NET AJAX服务器控件高级编程(.NET 3.5版)', 'book\_url': 'http://product.china-pub.com/216397', 'author': '(美)Adam Calderon;Joel Rumerman (著)', 'publisher': '机械工业出版社', 'isbn': '9787111270966', 'publish\_date': '2009-09-01出版', 'vip\_price': 'VIP会员价:', 'price': '¥65.00'}, {'title': 'PaaS程序设计', 'book\_url': 'http://product.china-pub.com/3770830', 'author': '(美)Lucas Carlson (著)', 'publisher': '机械工业出版社', 'isbn': '9787111482451', 'publish\_date': '2015-01-01出版', 'vip\_price': 'VIP会员价:', 'price': '¥39.00'}, {'title': 'Visual C++数字图像处理[按需印刷]', 'book\_url': 'http://product.china-pub.com/2437', 'author': '何斌 马天予 王运坚 朱红莲 (著)', 'publisher': '人民邮电出版社', 'isbn': '711509263X', 'publish\_date': '2001-04-01出版', 'vip\_price': 'VIP会员价:', 'price': '¥72.00'}]
是不是能正确提取图书列表的相关信息?这也说明我们的函数的正确性,由于也可能在解析中存在一些异常,比如某个字段的缺失,我们需要捕获异常并忽略该条数据,让程序能继续走下去而不是停止运行。
在完成了上述的工作后,我们来通过对页号的 URL 构造,实现采集多个分页下的数据,最后达到读取完该分类下的所有图书信息的目的。完整代码如下:
def get\_category\_books(category, url):
"""
获取类别图书,下面会有分页,我们一直请求,直到分页请求返回404即可停止
:return:
"""
books = []
page = 1
regex = "(http://.\*/)([0-9]+)\_(.\*).html"
pattern = re.compile(regex)
m = pattern.match(url)
if not m:
return []
prefix_path = m.group(1)
current_page = m.group(2)
if current_page != 1:
print("提取数据不是从第一行开始,可能存在问题")
suffix_path = m.group(3)
current_page = page
while True:
# 构造分页请求的URL
book_url = f"{prefix\_path}{current\_page}\_{suffix\_path}.html"
response = requests.get(url=book_url, headers=headers)
print(f"提取分类[{category}]下的第{current\_page}页图书数据")
if response.status_code != 200:
print(f"[{category}]该分类下的图书数据提取完毕!")
break
response.encoding = 'gbk'
# 将该分页的数据加到列表中
books.extend(parse_books_page(response.text))
current_page += 1
# 一定要缓一缓,避免对对方服务造成太大压力
time.sleep(0.5)
return books
最后保存数据到 MongoDB 中,这一步非常简单,我们前面已经操作过 MongoDB 的文档插入,直接搬用即可:
client = pymongo.MongoClient(host='MongoDB的服务地址', port=27017)
client.admin.authenticate("admin", "shencong1992")
db = client.scrapy_manual
collection = db.china_pub
# ...
def save\_to\_mongodb(data):
try:
collection.insert_many(data)
except Exception as e:
print("批量插入数据异常:{}".format(str(e)))
正是由于我们前面生成了批量的 json 数据,这里直接使用集合的 insert_many() 方法即可对采集到的数据批量插入 MongoDB 中。代码的最后我们加上一个 main 函数即可:
# ...
if __name__ == '\_\_main\_\_':
page_url = "http://www.china-pub.com/Browse/"
categories, urls = get_all_computer_book_urls(page_url)
# print(categories)
books_total = {}
for i in range(len(urls)):
books_category_data = get_category_books(categories[i], urls[i])
print(f"保存[{categories[i]}]图书数据到mongodb中")
save_to_mongodb(books_category_data)
print("爬取互动出版网的计算机分类数据完成")
这样一个简单的爬虫就完成了,还等什么,开始跑起来吧!!
4. 图书爬虫之代码运行
这是一个简单的爬虫,代码全在一个 python 文件中,我们直接单机运行即可,下面看在我本机上的演示效果: