深入理解 Scrapy 中间件
本小节我们来深入学习 Scrapy 中间件相关的代码,这里会涉及两个部分,分别是下载中间件和 Spider 中间件。我们会详细介绍到每个中间件模块的执行流程,找出相关代码进行分析。
1. Scrapy 中的中间件管理类
在源码的 scrapy/middleware.py 文件中,定义了一个所有中间件管理类的基类:MiddlewareManager。我们首先来仔细分析下该类的代码。
__init__.py:类初始化;该类的初始化将传入相应的中间件类,一般是列表的形式;
# ...
class MiddlewareManager:
"""Base class for implementing middleware managers"""
component_name = 'foo middleware'
def \_\_init\_\_(self, \*middlewares):
# 中间件类
self.middlewares = middlewares
# 中间件的方法
self.methods = defaultdict(deque)
# 添加中间件
for mw in middlewares:
self._add_middleware(mw)
_get_mwlist_from_settings(): 所有继承该中间件管理类的子类需要实现该方法,用于从 settings.py 中获取该中间件的列表;
# ...
class MiddlewareManager:
"""Base class for implementing middleware managers"""
# ...
@classmethod
def \_get\_mwlist\_from\_settings(cls, settings):
raise NotImplementedError
from_settings():从 settings.py 配置中实例化中间件管理类;
# ...
class MiddlewareManager:
"""Base class for implementing middleware managers"""
@classmethod
def from\_settings(cls, settings, crawler=None):
# 从配置中获取相应设置的中间件,比如设置的下载中间件、spider中间件列表等
mwlist = cls._get_mwlist_from_settings(settings)
middlewares = []
enabled = []
for clspath in mwlist:
try:
# 加载完整的模块路径,得到具体的模块
mwcls = load_object(clspath)
# 创建中间件实例
mw = create_instance(mwcls, settings, crawler)
# 添加到middles中
middlewares.append(mw)
# 用于后续info打印,表明启用的中间件位置路径
enabled.append(clspath)
except NotConfigured as e:
if e.args:
clsname = clspath.split('.')[-1]
logger.warning("Disabled %(clsname)s: %(eargs)s",
{'clsname': clsname, 'eargs': e.args[0]},
extra={'crawler': crawler})
# 打印启用的中间件信息
logger.info("Enabled %(componentname)ss:\n%(enabledlist)s",
{'componentname': cls.component_name,
'enabledlist': pprint.pformat(enabled)},
extra={'crawler': crawler})
# 使用从配置中获取的中间件列表实例化该中间件管理类
return cls(\*middlewares)
from_crawler(): 根据 Crawler 类对象来实例化中间件管理器类;利用的就是 Crawler 对象的 settings 属性值,然后调用 MiddlewareManager 类的 from_settings() 方法进行实例化;
# ...
class MiddlewareManager:
"""Base class for implementing middleware managers"""
# ...
def from\_crawler(cls, crawler):
return cls.from_settings(crawler.settings, crawler)
_add_middleware():添加所管理中间件类中的方法,主要是 open_spider() 和 close_spider() 方法;在这里会更新 self.methods 属性值;
# ...
class MiddlewareManager:
"""Base class for implementing middleware managers"""
# ...
def \_add\_middleware(self, mw):
if hasattr(mw, 'open\_spider'):
self.methods['open\_spider'].append(mw.open_spider)
if hasattr(mw, 'close\_spider'):
self.methods['close\_spider'].appendleft(mw.close_spider)
其他方法:下面的这些方法都是我们在前面 scrapy/utils/defer.py 中介绍过的,在此就不详细展开了;
# ...
class MiddlewareManager:
"""Base class for implementing middleware managers"""
# ...
def \_process\_parallel(self, methodname, obj, \*args):
return process_parallel(self.methods[methodname], obj, \*args)
def \_process\_chain(self, methodname, obj, \*args):
# 执行回调链,依次执行,返回一个Deferred对象
return process_chain(self.methods[methodname], obj, \*args)
def \_process\_chain\_both(self, cb_methodname, eb_methodname, obj, \*args):
return process_chain_both(self.methods[cb_methodname],
self.methods[eb_methodname], obj, \*args)
def open\_spider(self, spider):
return self._process_parallel('open\_spider', spider)
def close\_spider(self, spider):
return self._process_parallel('close\_spider', spider)
以上就是管理中间件类的全部属性和方法。下面我们将具体看由该管理类衍生出来的下载中间件管理类,同时会重点分析下载中间件以及 Spider 中间件的执行流程。
2. 下载中间件执行流程
我们现在来梳理下载中间件这个模块的执行流程。注意在 scrapy/downloadmiddlewares 目录下的代码并没有下载中间件的执行相关代码,该目录下是一系列定义好的内置下载中间件,大部分默认是启用的。这里的代码并不是我们想要的,那么和下载中间件执行流程相关的代码究竟在哪呢?
首先回过来头看下前面描述 Scrapy 的架构图,可知下载中间件位于引擎和下载器之间。上一节中我们介绍了下载器类 (Downloader) ,其中有一个属性 self.middleware,如下图所示。
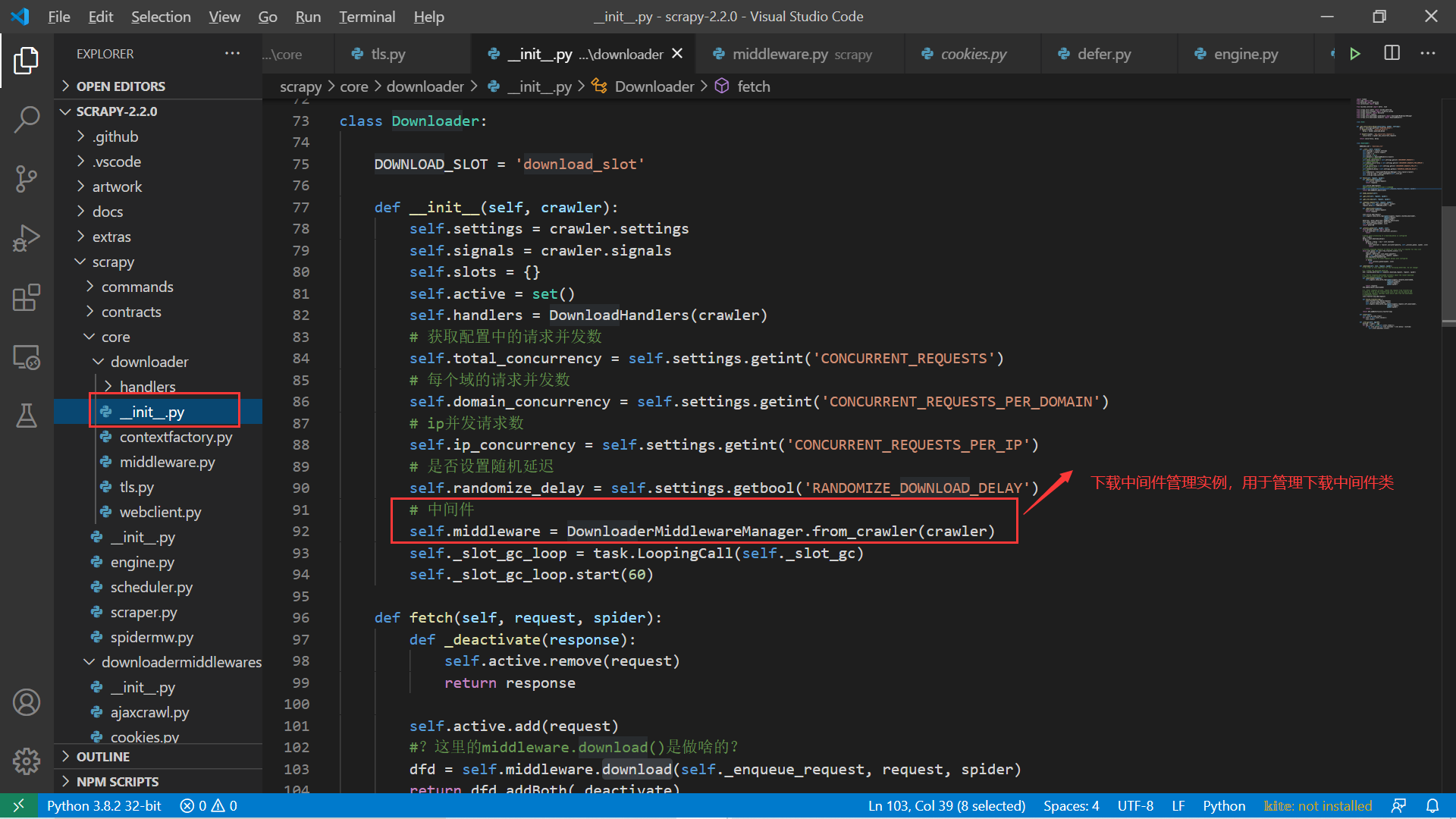
下载器类中的连接下载中间件的属性 该属性值是下载中间件管理器类 (DownloaderMiddlewareManager) 的一个实例,某种意义上来说它是连接下载模块和下载中间件模块之间的桥梁。我们继续研究下这个中间件管理器类,很明显它应该继承自上面介绍的中间件管理器类,事实也是如此:
# 源码位置:scrapy/core/downloader/middleware.py
# ...
class DownloaderMiddlewareManager(MiddlewareManager):
component_name = 'downloader middleware'
@classmethod
def \_get\_mwlist\_from\_settings(cls, settings):
return build_component_list(
settings.getwithbase('DOWNLOADER\_MIDDLEWARES'))
def \_add\_middleware(self, mw):
if hasattr(mw, 'process\_request'):
self.methods['process\_request'].append(mw.process_request)
if hasattr(mw, 'process\_response'):
self.methods['process\_response'].appendleft(mw.process_response)
if hasattr(mw, 'process\_exception'):
self.methods['process\_exception'].appendleft(mw.process_exception)
# ...
上面的两个方法非常容易理解,也透露了一些信息。对于下载中间件对象,中间件管理器主要提取的是中间件对象中的三个方法:process_request()、process_response() 以及 process_exception() 。注意这里方法进入队列的顺序,这也关系到框架对这些方法的调用顺序。在管理器类中还有一个非常重要的 download() 方法,该方法决定了上面三个方法返回不同值时的处理方案,同时也会将下载中间件中的三个方法按照相应的顺序添加到对应的回调链中:
# 源码位置:scrapy/core/downloader/middleware.py
# ...
class DownloaderMiddlewareManager(MiddlewareManager):
# ...
def download(self, download_func, request, spider):
@defer.inlineCallbacks
def process\_request(request):
# 依次遍历下载中间件的process\_request()方法,处理请求
for method in self.methods['process\_request']:
response = yield deferred_from_coro(method(request=request, spider=spider))
if response is not None and not isinstance(response, (Response, Request)):
# 返回非Request或Response类型,抛出异常
# ...
if response:
return response
# 最后将请求传给下载器执行下载
return (yield download_func(request=request, spider=spider))
@defer.inlineCallbacks
def process\_response(response):
# 处理下载的响应
if response is None:
raise TypeError("Received None in process\_response")
elif isinstance(response, Request):
return response
for method in self.methods['process\_response']:
response = yield deferred_from_coro(method(request=request, response=response, spider=spider))
if not isinstance(response, (Response, Request)):
# 返回非Request或Response类型,抛出异常
# ...
if isinstance(response, Request):
# 如果返回Request,则直接返回,后续的中间件的process\_response()不处理
return response
# 最后返回响应结果
return response
@defer.inlineCallbacks
def process\_exception(failure):
exception = failure.value
for method in self.methods['process\_exception']:
response = yield deferred_from_coro(method(request=request, exception=exception, spider=spider))
if response is not None and not isinstance(response, (Response, Request)):
# 返回非Request或Response类型,抛出异常
# ...
if response:
return response
return failure
# 调用请求,同时将process\_request()依次加入回调链中并返回一个Deferred对象
deferred = mustbe_deferred(process_request, request)
# 异常回调
deferred.addErrback(process_exception)
# 响应回调
deferred.addCallback(process_response)
return deferred
这个 download() 方法非常重要,也有些难以理解。注意一点:该方法主要是形成一个完整的下载链路,包括请求链 (process request chain)、下载请求 (在 download() 方法的 download_func 参数)、响应处理链 (process response chain),另外还加上一个请求异常的回调链。来看看我们对这个过程的一个总结图:
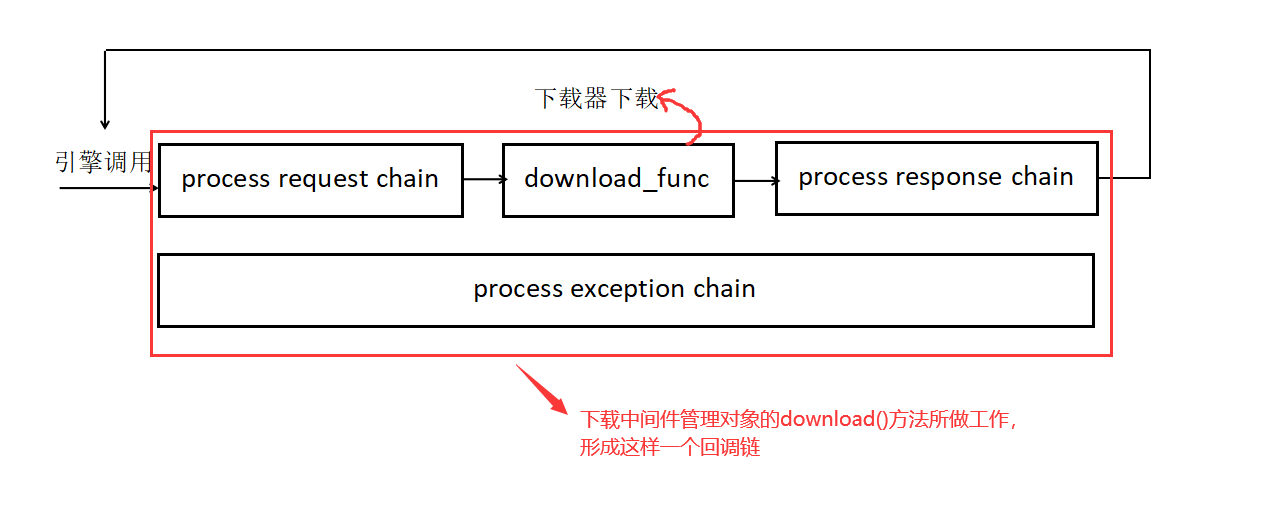
下载中间件管理对象的download()方法 注意,中间件管理器会和引擎模块以及下载模块之间有交互,那么它们之间发生交互的代码是哪一句呢?这里就不卖关子和追踪了,我们直接给出答案:
下载中间件管理对象和下载器的交互就在于 download() 方法中传进来的 download_func 参数。我们在下载器中找到如下代码:
# ...
class Downloader:
# ...
def fetch(self, request, spider):
def \_deactivate(response):
self.active.remove(request)
return response
self.active.add(request)
# 调用下载中间件管理对象的download()方法
dfd = self.middleware.download(self._enqueue_request, request, spider)
return dfd.addBoth(_deactivate)
这里调用的下载中间件管理对象 download() 中的 download_func 参数为 self._enqueue_request,而我们在上一节中正好介绍过该方法正好是下载器中下载网页的起始方法。
另一方面,引擎模块和该下载中间件管理器类的交互也正是通过下载器的这个 fetch() 方法。我们直接找出相关的代码语句:
# 源码位置:scrapy/core/engine.py
# ...
class ExecutionEngine:
# ...
def \_download(self, request, spider):
# ...
# 这里的self.downloader就是下载器对象,调用fetch()方法下载网页
dwld = self.downloader.fetch(request, spider)
dwld.addCallbacks(_on_success)
dwld.addBoth(_on_complete)
return dwld
总的来说,我们可以得到如下的一个调用过程:
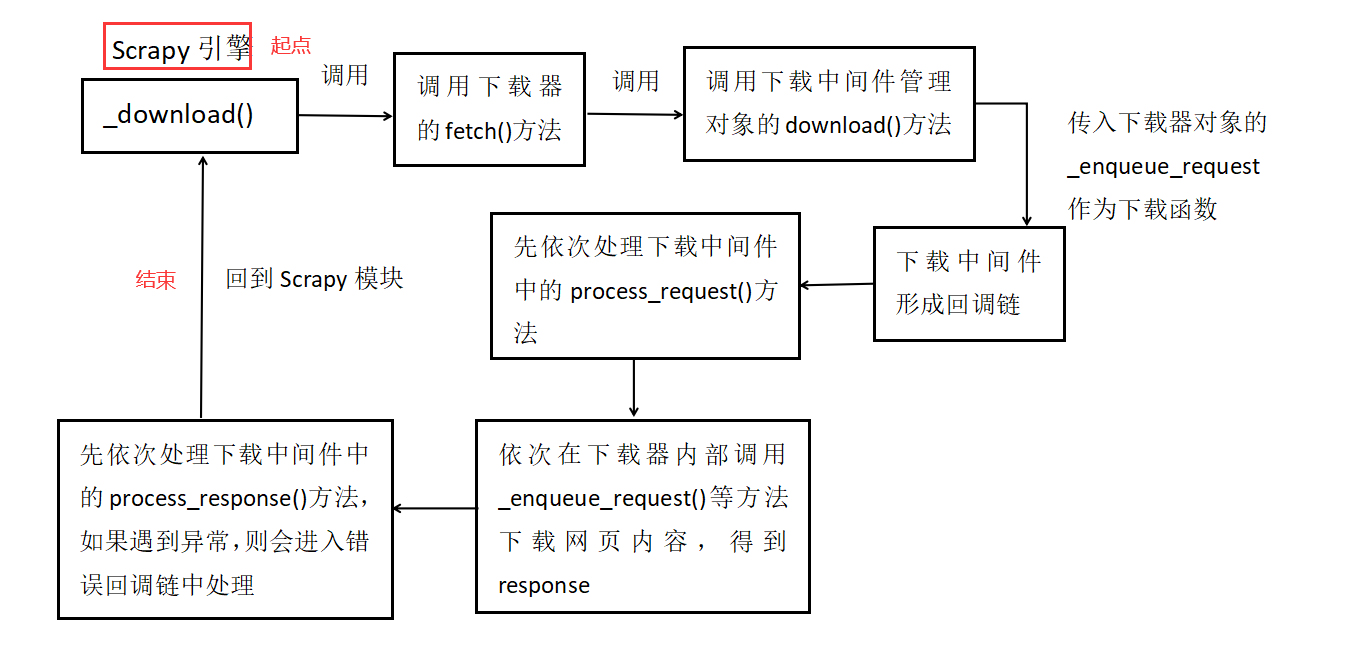
scrapy中下载部分的简要调用过程 到目前为止,我们对下载中间件的执行流程进行了一个简要的概述,但没深究其中的代码细节。如果有兴趣的话可以仔细跟踪下代码的执行过程,这些并不复杂,主要是对 Twisted 模块的应用。
3. Spider 中间件执行流程
上面我们看到了下载中间件的管理类,那么这个 Spider 中间件有没有相应的管理类呢?答案是肯定的,这个类也在 scrapy 的核心目录 (core) 下的 spidermw.py 文件:
# 源码位置:scrapy/core/spidermw.py
# ...
class SpiderMiddlewareManager(MiddlewareManager):
component_name = 'spider middleware'
@classmethod
def \_get\_mwlist\_from\_settings(cls, settings):
return build_component_list(settings.getwithbase('SPIDER\_MIDDLEWARES'))
def \_add\_middleware(self, mw):
super(SpiderMiddlewareManager, self)._add_middleware(mw)
if hasattr(mw, 'process\_spider\_input'):
self.methods['process\_spider\_input'].append(mw.process_spider_input)
if hasattr(mw, 'process\_start\_requests'):
self.methods['process\_start\_requests'].appendleft(mw.process_start_requests)
process_spider_output = getattr(mw, 'process\_spider\_output', None)
self.methods['process\_spider\_output'].appendleft(process_spider_output)
process_spider_exception = getattr(mw, 'process\_spider\_exception', None)
self.methods['process\_spider\_exception'].appendleft(process_spider_exception)
def scrape\_response(self, scrape_func, response, request, spider):
# ...
def process\_start\_requests(self, start_requests, spider):
return self._process_chain('process\_start\_requests', start_requests, spider)
有了前面下载中间件管理器类的剖析经验,我们可以很容易知道这些方法的作用:
_get_mwlist_from_settings():从全局配置中获取定义的 Spider 中间件,包括 settings.py 和 default_settings.py 中的配置;_add_middleware():将各个 Spider 中间件中的相关处理方法添加到对应的self.methods中,和前面的下载中间件管理器类一样;scrape_response()方法类似于前面的下载中间件管理器类的download()方法,它是连接 Spdier 中间件和其他模块的桥梁,我们后面详细介绍其实现细节;process_start_requests()是处理初始请求的方法;
我们来回顾下第8节的 Scrapy 框架的数据流图,如下:
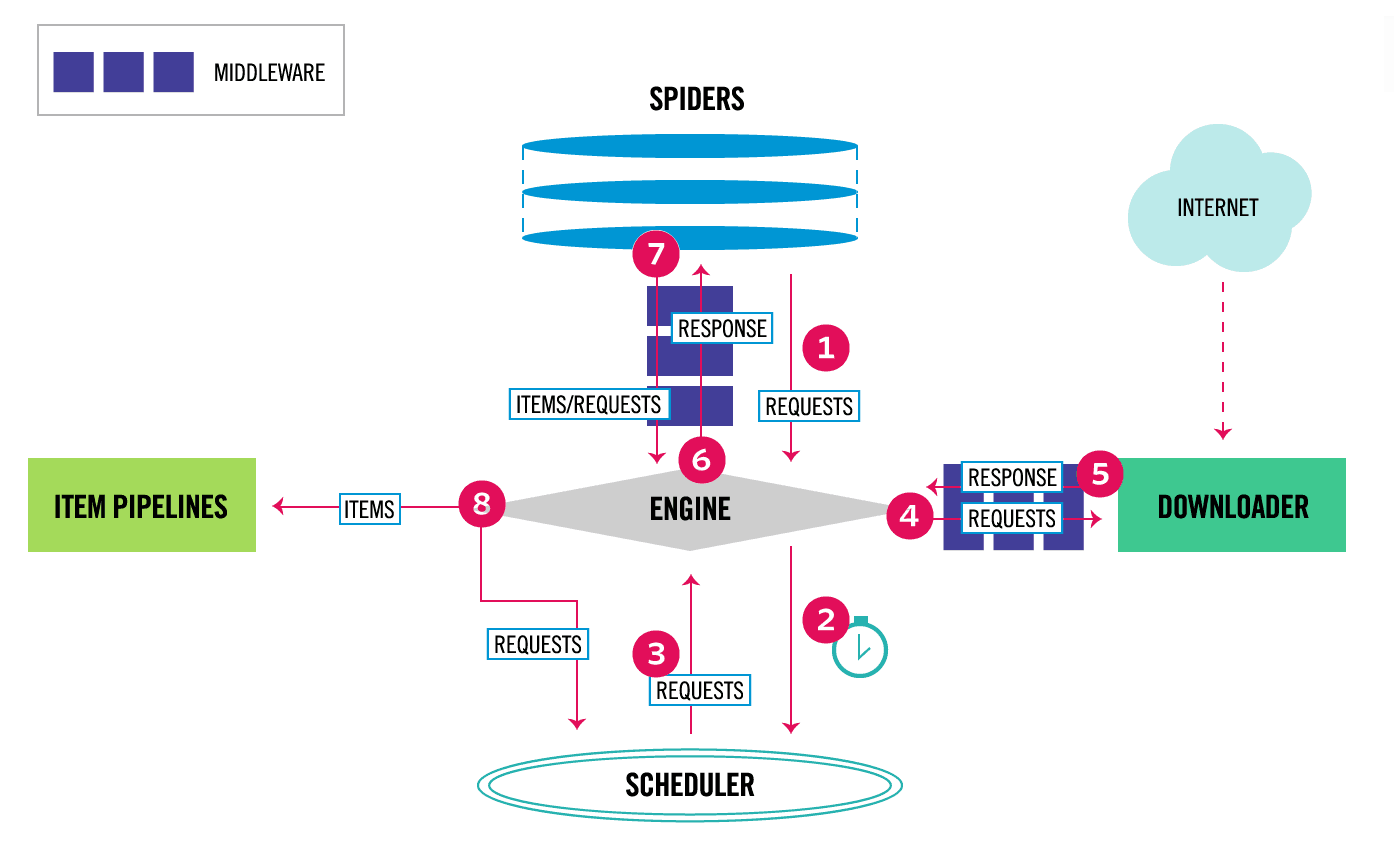
Scrapy框架的数据流图 可以看到 Spider 中间件连接的是 Spider 模块和引擎模块,引擎将下载器获得的 Response 结果交给 Spdier 模块解析,可以返回 ITEMS 类型或者 Requests 类型。有了这个图,我们就可以来代码中去搜索相关代码:
# 源码位置:scrapy/core/engine.py
# ...
class ExecutionEngine:
# ...
def \_handle\_downloader\_output(self, response, request, spider):
if not isinstance(response, (Request, Response, Failure)):
raise TypeError(
"Incorrect type: expected Request, Response or Failure, got %s: %r"
% (type(response), response)
)
# downloader middleware can return requests (for example, redirects)
if isinstance(response, Request):
self.crawl(response, spider)
return
# response is a Response or Failure
d = self.scraper.enqueue_scrape(response, request, spider)
d.addErrback(lambda f: logger.error('Error while enqueuing downloader output',
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))
return d
从引擎的类定义中我们可以很快定位到上面的方法:_handle_downloader_output() 该方法正如其方法名,用于处理下载器的结果,也就是上面数据流图的第5部分。对于下载器部分的返回结果必须是 Request、Response 或者 Failure 三者之一,否则直接抛异常;此外,如果返回结果是 Request 类型,则调用 self.crawl() 方法继续请求。对于 Response 类型的处理就是调用 self.scraper.enqueue_scrape() 方法处理。这里就要涉及到 Scrapy 中定义的 Scraper 类了,它的实现位于 scrapy/core/scraper.py 文件中。我们来看相关的代码段:
# 源码位置:scrapy/core/scraper.py
# ...
class Scraper:
def \_\_init\_\_(self, crawler):
# ...
# 获取Spider中间件管理器对象
self.spidermw = SpiderMiddlewareManager.from_crawler(crawler)
# ...
# ...
def enqueue\_scrape(self, response, request, spider):
slot = self.slot
dfd = slot.add_response_request(response, request)
def finish\_scraping(_):
slot.finish_response(response, request)
self._check_if_closing(spider, slot)
self._scrape_next(spider, slot)
return _
dfd.addBoth(finish_scraping)
# ...
self._scrape_next(spider, slot)
return dfd
def \_scrape\_next(self, spider, slot):
while slot.queue:
response, request, deferred = slot.next_response_request_deferred()
self._scrape(response, request, spider).chainDeferred(deferred)
def \_scrape(self, response, request, spider):
"""Handle the downloaded response or failure through the spider
callback/errback"""
# ...
# 这里就是经过Spider中间件后,调用Spider模块去处理结果
dfd = self._scrape2(response, request, spider) # returns spider's processed output
# 加入回调,处理spider结果成功和失败的回调
dfd.addErrback(self.handle_spider_error, request, response, spider)
dfd.addCallback(self.handle_spider_output, request, response, spider)
return dfd
def \_scrape2(self, request_result, request, spider):
"""Handle the different cases of request's result been a Response or a
Failure"""
if not isinstance(request_result, Failure):
# 下载请求成功,调用Spider中间件管理对象的scrape\_response()方法
return self.spidermw.scrape_response(
self.call_spider, request_result, request, spider)
else:
dfd = self.call_spider(request_result, request, spider)
return dfd.addErrback(
self._log_download_errors, request_result, request, spider)
# ...
def handle\_spider\_output(self, result, request, response, spider):
if not result:
return defer_succeed(None)
it = iter_errback(result, self.handle_spider_error, request, response, spider)
dfd = parallel(it, self.concurrent_items, self._process_spidermw_output,
request, response, spider)
return dfd
def \_process\_spidermw\_output(self, output, request, response, spider):
"""Process each Request/Item (given in the output parameter) returned
from the given spider
"""
if isinstance(output, Request):
# 如归spider模块返回的是Request,则继续请求
self.crawler.engine.crawl(request=output, spider=spider)
elif is_item(output):
# 如果返回的是Item类型,则调用self.itemproc.process\_item()方法处理
self.slot.itemproc_size += 1
dfd = self.itemproc.process_item(output, spider)
dfd.addBoth(self._itemproc_finished, output, response, spider)
return dfd
elif output is None:
pass
else:
typename = type(output).__name__
logger.error(
'Spider must return request, item, or None, got %(typename)r in %(request)s',
{'request': request, 'typename': typename},
extra={'spider': spider},
)
# ...
上面的代码看似复杂,其实逻辑关系非常清晰明了,正如前面的数据流图所画。我们现在也用下面的图来描述下函数的调用过程,方便大家更清楚的看到引擎、Spider 中间件以及 Spider 模块三者之间的调用过程:
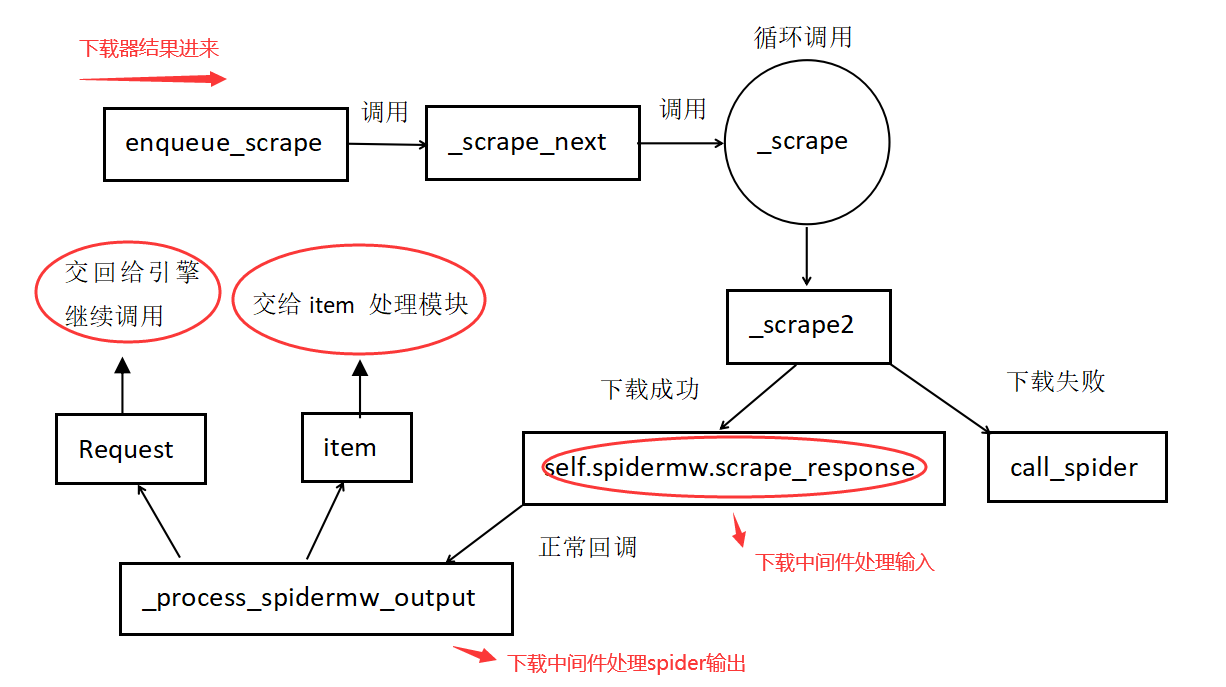
Spider中间件代码追踪
根据这个流程图再回去看相应的代码,是不是会有一些理解的感觉?现在关于 Spider 中间件还有最后一块内容没搞定,就是 Spider 中间件如何与 Spider 模块交互的呢?答案就是 Spider 中间件管理器的 scrape_response() 方法:
# ...
class SpiderMiddlewareManager(MiddlewareManager):
# ...
def scrape\_response(self, scrape_func, response, request, spider):
# ...
# ...
重点关注该方法的第二个参数:scrape_func。通过前面的 _scrapy2() 可知调用 Spider 中间件管理器对象的 scrape_response() 方法时传入的参数为:self.call_spider。其实现如下:
# ...
class Scraper:
# ...
def call\_spider(self, result, request, spider):
result.request = request
dfd = defer_result(result)
callback = request.callback or spider.parse
warn_on_generator_with_return_value(spider, callback)
warn_on_generator_with_return_value(spider, request.errback)
# 将spider对象中设置的解析网页的函数加入回调链
dfd.addCallbacks(callback=callback,
errback=request.errback,
callbackKeywords=request.cb_kwargs)
return dfd.addCallback(iterate_spider_output)
# ...
这里的代码非常关键,先是获取 Request 请求设置的回调函数,如果没有则默认为 spider.parse 函数;紧接着就是将 callback 方法添加到回调链中。我们的请求在通过 Spider 中间件处理之后会进入 Spider 模块中定义的 callback 方法去处理 response。看到了么,这就是我们前面写了那么多的处理下载结果的函数,它的调用就在这里设置的。
到此,我们的下载中间件以及 Spider 中间件的整个代码过程就算大致介绍完毕了,对于更多的代码细节,还需要读者课后仔细研读,期待日后 Scrapy 的源码中能留下你们的足迹 !
4. 小结
本小节中,我们简单分析了 Scrapy 框架中的下载中间件和 Spider 中间件的相关代码,理清楚了之前介绍的实现中间件类所必要的属性方法,对这些中间件类的编写,我们是不是有了更清楚的认识呢?