Scrapy与 Selenium 的结合
今天我们来使用 Scrapy 和 Selenium 结合爬取京东商城中网络爬虫相关的书籍数据。
1. 需求分析与初步实现
今天我们的目的是使用 Scrapy 和 Selenium 结合来爬取京东商城中搜索 “网络爬虫” 得到的所有图书数据,类似于下面这样的数据:
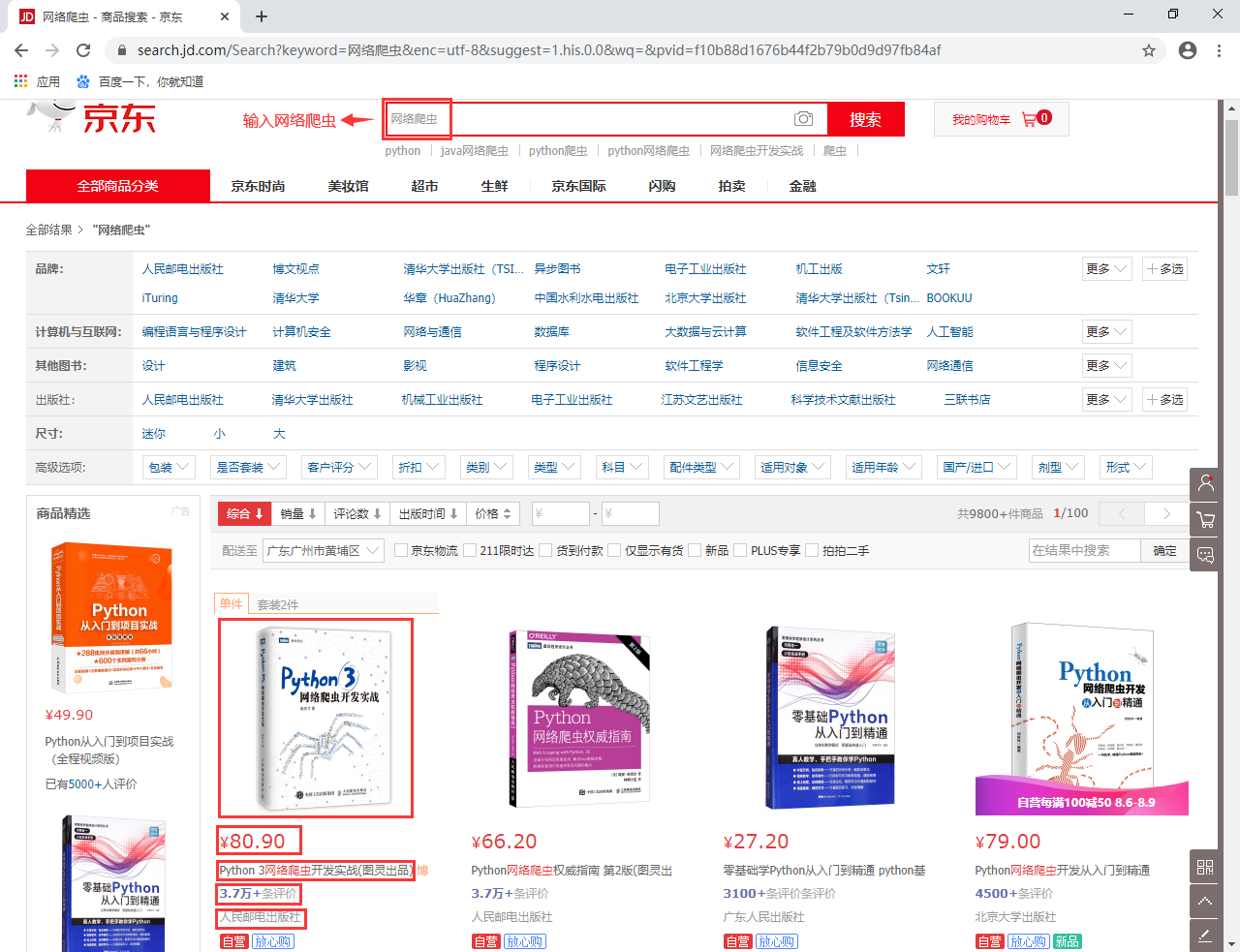
京东商城搜索 网络爬虫 搜索出的结果有9800+条数据,共计100页。我们现在要抓取所有的和网络爬虫相关的书籍数据。有一个问题需要注意,搜索的100页数据中必定存在重复的结果,我们可以依据图书的详细地址来进行去重。此外,我们提取的图书数据字段有:
- 图书名;
- 价格;
- 评价数;
- 店铺名称;
- 图书详细地址;
需求已经非常明确,现在开始使用 Selenium 和 Scrapy 框架结合来完成这一需求。来看看如果我们是单纯使用 Selenium 工具,该如何完成数据爬取呢?这里会有一个问题需要注意:按下搜索按钮后,显示的数据只有30条,只有使用鼠标向下滚动后,才会加载更多数据,最终显示60条结果,然后才会到达翻页的地方。在 selenium 中我们可以使用如下两行代码实现滚动条滑到最底端:
height = driver.execute_script("return document.body.scrollHeight;")
driver.execute_script(f"window.scrollBy(0, {height})")
time.sleep(2)
可以看到,上面两行代码主要是执行 js 语句。第一行代码是得到页面的底部位置,第二行代码是使用 scrollBy() 方法控制页面滚动条移动到底部。接下来,我们来看看页面数据的提取,直接右键 F12,可以通过 xpath 表达式得到所有需要抓取的数据。为此,我编写了一个根据页面代码提取图书数据的方法,具体如下:
def parse\_book\_data(html):
etree_html = etree.HTML(html)
# 获取列表
gl_items = etree_html.xpath('//div[@id="J\_goodsList"]/ul/li')
print('总共获取数据:{}'.format(len(gl_items)))
res = []
for item in gl_items:
book_name_em = item.xpath('.//div[@class="p-name"]/a/em/text()')[0]
book_name_font = item.xpath('.//div[@class="p-name"]/a/em/font/text()')
book_name_font = "".join(book_name_font) if book_name_font else ""
# 获取图书名
book_name = f"{book\_name\_em}{book\_name\_font}"
# 获取图书的详细介绍地址
book_detail_url = item.xpath('.//div[@class="p-name"]/a/@href')[0]
# 获取图书价格
price = item.xpath('.//div[@class="p-price"]/strong/i/text()')[0]
# 获取评论数
comments = item.xpath('.//div[@class="p-commit"]/strong/a/text()')[0]
# 获取店铺名称
shop_name = item.xpath('.//div[@class="p-shopnum"]/a/text()')
shop_name = shop_name[0] if shop_name else ""
data = {}
data['book\_name'] = book_name
data['book\_detail\_url'] = book_detail_url
data['price'] = price
data['comments'] = comments
data['shop\_name'] = shop_name
res.append(data)
# 返回页面解析的结果
print('本页获取的结果:{}'.format(res))
return res
现在来思考下如何能使用 selenium 一页一页访问?我给出了如下代码:
def get\_page\_data(driver, page):
"""
:driver 驱动
:page 第几页
"""
# 请求当前页
if page > 1:
WebDriverWait(driver, 10).until(
EC.visibility_of_element_located((By.ID, 'J\_bottomPage'))
)
driver.find_element_by_xpath(f'//div[@id="J\_bottomPage"]/span/a[text()="{page}"]').click()
time.sleep(2)
# 滚动到最下面,出现京东图书剩余书籍数据
height = driver.execute_script("return document.body.scrollHeight;")
driver.execute_script(f"window.scrollBy(0, {height})")
time.sleep(2)
return parse_book_data(driver.page_source)
对于第一页的访问是在输入关键字<网络爬虫>后点击按钮得到的,我们不需要放到这个函数来得到,只需要滚动到底部得到所有的图书数据即可;而对于第2页之后的页面,我们需要使用 selenium 的模拟鼠标点击功能,点击下对应页后便能跳转得到该页,然后再滚动到底部,就可以得到整页的搜索结果。我们来看看完整的实现:
import time
import random
import re
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains
from lxml import etree
def get\_page\_data(driver, page):
"""
:driver 驱动
:page 第几页
"""
# 具体代码参考上面
# ...
def parse\_book\_data(html):
"""
解析页面图书数据
"""
# 具体代码参考上面
# ...
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ['enable-automation'])
driver = webdriver.Chrome(options=options, executable_path="C:/Users/Administrator/AppData/Local/Google/Chrome/Application/chromedriver.exe")
driver.maximize_window()
driver.get("https://www.jd.com/")
# 输入网络爬虫,然后点击搜索
driver.find_element_by_id('key').send_keys('网络爬虫')
driver.find_elements_by_xpath('//div[@role="serachbox"]/button')[0].click()
time.sleep(2)
max_page = 100
for i in range(1, max_page + 1):
get_page_data(driver, i)
下面来看看代码执行的效果,这里为了能尽快执行完,我将 max_page 参数调整为10,只获取10页搜索结果,一共是600条数据: